PyTorch中关于backward、grad、autograd计算原理的深度剖析
PyTorch中Tensor的详细说明
PyTorch中所有的计算其实都可以回归到Tensor上,所以有必要重新认识一下Tensor。如果我们需要计算某个Tensor的导数,那么我们需要设置其参数.requires_grad属性为True。
在PyTorch中torch()的官方解释如下:
torch()
Type: module
String form: <module 'torch' from '/usr/local/lib/python3.7/site-packages/torch/__init__.py'>
File: /usr/local/lib/python3.7/site-packages/torch/__init__.py
Docstring:
The torch package contains data structures for multi-dimensional
tensors and mathematical operations over these are defined.
Additionally, it provides many utilities for efficient serializing of
Tensors and arbitrary types, and other useful utilities.
在PyTorch中,我们自己定义的变量,我们称之为叶子节点(leaf nodes),而基于叶子节点得到的中间或最终变量则可称之为结果节点。例如下面例子中的 x x x 则是叶子节点, y y y 则是结果节点。
import torch
x = torch.rand(3, requires_grad=True) # 创建自变量x,并赋值为3
y = x**2 # 创建中间/结果变量
z = x + x # 创建中间/结果变量
另外一个Tensor中通常会记录如下图中所示的属性:
data: 即存储的数据信息。requires_grad: 设置为True,则表示该Tensor需要求导。grad: 该Tensor的梯度值, 每次在计算backward时都需要将前一时刻的梯度归零,否则梯度值会一直累加。grad_fn: 用于指示梯度函数是哪种类型,叶子节点通常为None,只有结果节点的grad_fn才有效。例如:上面示例代码中的y.grad_fn=<PowBackward0 at 0x213550af048>,z.grad_fn=<AddBackward0 at 0x2135df11be0>is_leaf: 用来指示该Tensor是否是叶子节点。
参数
requires_grad的含义及标志位说明:
- 如果对于某Variable 变量 x ,其
x.requires_grad == True, 则表示它可以参与求导,也可以从它向后求导。默认情况下,一个新的Variables 的 requires_grad 和 volatile 都等于 False 。requires_grad == True具有传递性,例如:
x.requires_grad == True ,y.requires_grad == False , z=f(x,y)
则, z.requires_grad == True。- 凡是参与运算的变量(包括 输入量,中间输出量,输出量,网络权重参数等),都可以设置
requires_grad。volatile==True就等价于requires_grad==False。volatile==True同样具有传递性。一般只用在inference(推理)过程中。 若是某个过程,从 x 开始都只需做预测,不需反传梯度的话,那么只需设置x.volatile=True ,那么 x 以后的运算过程的输出均为volatile==True,即requires_grad==False。
由于inference 过程不必backward(),所以requires_grad 的值为False 或 True,对结果是没有影响的,但是对程序的运算效率有直接影响;因此,在inference过程中,使用volatile=True,就不必把运算过程中所有参数都手动设一遍requires_grad=False了,方便快捷 。detach():如果 x 为中间输出,x’ = x.detach 表示创建一个与 x 相同,但requires_grad==False的variable,(实际上是把x’ 以前的计算图 grad_fn 都消除了),x’ 也就成了叶节点。原先反向传播时,回传到x时还会继续,而现在回到x’处后,就结束了,不继续回传求到了。另外值得注意,x (variable类型) 和 x’ (variable类型)都指向同一个Tensor ,即 x.data,因此,detach_() 表示不创建新变量,而是直接修改 x 本身。retain_graph:每次backward()时,默认会把整个计算图free掉。一般情况下是每次迭代,只需一次 forward() 和一次 backward() ,前向运算forward() 和反向传播backward()是成对存在的,一般一次backward()也是够用的。但是不排除,由于自定义loss等的复杂性,需要一次forward()之后,通过多个不同loss的backward()来累积同一个网络的grad,进行参数更新。于是,若在当前backward()后,不执行forward() 而可以执行另一个backward(),需要在当前backward()时,指定保留计算图,即backward(retain_graph)。
\quad
create_graph ,这个标志位暂时还未深刻理解,等之后再更新。
参考链接:Pytorch的backward()相关理解
典型示例:
x = torch.tensor(1.0, requires_grad = True) # 叶子节点,equires_grad = True表示我们需计算Tensor的导数
y = torch.tensor(2.0, requires_grad = True) # 叶子节点
z = x**2 + y # 结果节点
z.backward() # 反向传播求导数
print(z) # 输出结果节点
print(x.grad_fn) # 指示梯度函数是哪种类型,叶子节点通常为None,只有结果节点的grad_fn才有效
print(y.grad_fn)
print(z.grad_fn)
>>>
tensor(3., grad_fn=<AddBackward0>)
None
None
<AddBackward0 object at 0x122e00c10>
典型示例——说明备注:
\quad
- 如果 z z z 是一个标量,当调用它的
backward方法后会根据 ”链式求导法则“ 自动计算出各叶子节点的梯度值。- 如果 z z z 是一个向量或者是一个矩阵的情况,此时该怎么计算梯度呢?这种情况我们需要定义
grad_tensor来计算矩阵的梯度。
PyTorch中backward计算机制详解
backward构建计算图过程
pytorch是动态图机制,所以在训练模型时候,每迭代一次都会构建一个新的计算图。而计算图实质表征了程序中各变量之间的运算关系。举个列子:若 y = ( a + b ) ( b + c ) y=(a+b)(b+c) y=(a+b)(b+c),则在这个运算过程会建立出如下的计算图:
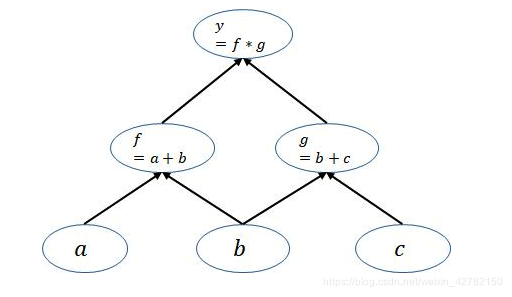
在这个计算图中, 节点就是参与运算的变量,在pytorch中是用Variable()变量来包装的;而图中的 边就是变量之间的运算关系,比如:torch.mul(),torch.mm(),torch.div() 等等。
备注:
上图中的leaf_node——叶子节点:就是由用户自己创建的Variable变量,在这个图中仅有a,b,c 是 leaf_node。
\quad
pytoch构建的计算图是动态图,为了节约内存,所以每次一轮迭代完也即是调用了一次backward函数计算之后,计算图就被在内存释放,因此如果你需要多次backward只需要在第一次反向传播时候添加一个参数retain_graph=True标识,让计算图不被立即释放。实际上文档中retain_graph和create_graph两个参数作用相同,因为前者是保持计算图不释放,而后者是创建计算图,因此如果我们不想要计算图释放掉,将任意一个参数设置为True都行。
为什么我们需要关注leaf_node?
因为在网络backward时候,需要用链式求导法则求出网络最后输出的梯度,然后再对网络进行优化,如下就是网络的求导过程。
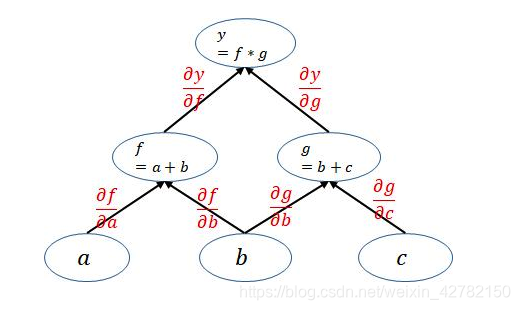
通过观察上面的计算图可以发现一个很重要的点:
pytorch在利用计算图求导的过程中根节点都是一个标量(即一个数)。然而,当根节点(即:函数的因变量)为一个向量的时候,会构建多个计算图对该向量中的每一个元素分别进行求导。由此引出了关于Tensor为向量(矩阵)时,计算对叶子节点向量(矩阵)的导数的计算原理和PyTorch实现方法。
关于Tensor为向量(矩阵)时,计算对叶子节点向量(矩阵)的导数的计算原理和PyTorch实现方法
结合上面两节的分析,可以发现,pytorch在求导的过程中,分为下面两种情况:
如果是标量对向量求导(scalar对tensor求导),那么就可以保证上面的计算图的根节点只有一个,此时不用引入grad_tensors参数,直接调用backward函数即可
如果是(向量)矩阵对(向量)矩阵求导(tensor对tensor求导),实际上是先求出Jacobian矩阵中每一个元素的梯度值(每一个元素的梯度值的求解过程对应上面的计算图的求解方法),然后将这个Jacobian矩阵与grad_tensors参数对应的矩阵进行对应的点乘,得到最终的结果。
参考链接:
pytorch中backward()函数详解
pytorch的计算图
backward函数介绍及使用
PyTorch官方文档中关于backward( )函数解释如下图,官方网址链接:backward()

创建一个Tensor时,使用requires_grad参数指定是否记录对其的操作,以便之后利用backward()方法进行梯度求解。
backward()函数接受参数,表示在特定位置求梯度值,该参数应和调用backward()函数的Tensor的维度相同,或者是可broadcast的维度。默认为torch.tensor(1),也就是在当前梯度为标量1的位置求叶子Tensor的梯度。
- 默认同一个运算得到的Tensor仅能进行一次
backward()。再次运算得到的Tesnor,可以再次进行backward()。 - 当多个Tensor从相同的源Tensor运算得到,这些运算得到的Tensor的
backwards()方法将向源Tensor的grad属性中进行数值累加。
参考链接:PyTorch的学习笔记02 - backward( )函数
backward只能被应用在一个标量上,也就是一个一维tensor,或者传入跟变量相关的梯度。backward里传入的参数是每次求导的一个系数。 特别注意: Variable里面默认的参数requires_grad=False,所以这里我们要重新传入requires_grad=True让它成为一个叶子节点。
我们先看一下源代码中backward的接口是如何定义的:
torch.autograd.backward(
tensors,
grad_tensors=None,
retain_graph=None,
create_graph=False,
grad_variables=None)
Docstring:
Computes the sum of gradients of given tensors w.r.t. graph leaves.
参数说明:
tensors: 用于计算梯度的tensor。也就是说 这两种方式是等价的 :torch.autograd.backward(z) == z.backward()grad_tensors: 在计算矩阵的梯度时会用到。grad_tensors其实也是一个tensor,它的shape一般需要和前面的tensor保持一致。 该参数的具体实例见下面实例001所示。retain_graph: 通常在调用一次backward后,pytorch会自动把计算图销毁,所以要想对某个变量重复调用backward,则需要将该参数设置为True。create_graph: 当设置为True的时候可以用来计算更高阶的梯度grad_variables: 这个官方说法是grad_variables’ is deprecated. Use ‘grad_tensors’ instead.也就是说这个参数后面版本中应该会丢弃,直接使用grad_tensors就好了。
实例001:
# grad_tensors参数功能说明
import torch
import torch.nn as nn
# (1)首先,创建一个张量x,并设置其 requires_grad参数为True,程序将会追踪所有对于该张量的操作;
# 接下来,当完成计算后通过调用 .backward(),自动计算所有的梯度, 这个张量的所有梯度将会自动积累到 .grad 属性。
x = torch.tensor([2,3,4], dtype=torch.float, requires_grad=True)
print(x)
>>>tensor([2., 3., 4.], requires_grad=True)
#(2)其次,创建一个关于x的函数y,由于x的requires_grad参数为True,所以y对应的用于求导的参数grad_fn为<MulBackward0>。
# 这是因为在自动梯度计算中还有另外一个重要的类Function,Tensor 和 Function互相连接并生成一个非循环图,它表示和存储了完整的计算历史。 每个张量都有一个.grad_fn属性,这个属性引用了一个创建了Tensor的Function(除非这个张量是用户手动创建的,即,这个张量的 grad_fn 是 None,例如1中创建的x的 grad_fn 是 None)
y = x * 2
while y.norm() < 1000:
y = y*2
print(y)
>>>tensor([ 512., 768., 1024.], grad_fn=<MulBackward0>)
#(3)最后,.backward()进行反向传播并输出x的梯度值,而这里出现了一个参数torch.ones_like(y),它即为backward()函数中的grad_tensors参数,要求grad_tensors参数的shape与待求梯度的Tensor向量(此处为y)的shape保持一致。
y.backward(torch.ones_like(y))
print(x.grad)
>>>tensor([256., 256., 256.])
### 备注:
Question:为什么在上述求导过程中需要引入参数grad_tensors?
Because:如果我们不引入这个参数的话,运行代码会报下面的错误:
RuntimeError: grad can be implicitly created only for scalar outputs
即:提示我们输出y不是一个标量,无法直接求导。
Answer:引入参数grad_tensors,解决欲求导的Tensor是非标量的情况。
参数grad_tensors的核心功能:
先举个栗子:
x = torch.ones(2,requires_grad=True)
z = x + 2
print(z)
>>> tensor([3., 3.], grad_fn=<AddBackward0>)
# 假设直接对矩阵z用反向传播求导数
z.backward()
>>> ...
RuntimeError: grad can be implicitly created only for scalar outputs
错误分析:
当我们运行上面的代码的话会报错,报错信息为RuntimeError: grad can be implicitly created only for scalar outputs。大意是只有对标量输出视,它才会计算梯度,而求一个矩阵对另一矩阵的导数则束手无策。
\quad
上述代码的计算过程如下:
X = [ x 0 x 1 ] Z = X + 2 = [ x 0 + 2 x 1 + 2 ] ⇓ 求 解 ∂ Z ∂ X = ? \begin{aligned} &\mathbf{X} = \left[ \begin{matrix} x_0 & x_1\end{matrix} \right]\\ &\mathbf{Z} = \mathbf{X}+2= \left[ \begin{matrix} x_0 +2& x_1+2 \end{matrix} \right]\\ & \quad \Downarrow\\ &求解\frac{\partial \mathbf{Z} }{\partial\mathbf{X} }=? \end{aligned} X=[x0x1]Z=X+2=[x0+2x1+2]⇓求解∂X∂Z=?
如何解决矩阵无法直接求导:
那么我们只要想办法把矩阵转变成一个标量不就好了。比如我们可以对 z z z求和,然后用求和得到的标量在对 x x x求导,这样不会对结果有影响,例如:
Z s u m = ∑ z i = x 0 + x 1 + 4 ⇓ t h e n ∂ Z s u m ∂ x 0 = ∂ Z s u m ∂ x 1 = 1 \begin{aligned} &\mathbf{Z_{sum}} = \sum \mathbf{z_i}= x_0 +x_1+4\\ & \quad \Downarrow\\ &then \quad \frac{\partial \mathbf{Z_{sum}} }{\partial\mathbf{x_0} }=\frac{\partial \mathbf{Z_{sum}} }{\partial\mathbf{x_1} }=1 \end{aligned} Zsum=∑zi=x0+x1+4⇓then∂x0∂Zsum=∂x1∂Zsum=1
我们可以看到先对矩阵 z z z求和,后再计算梯度没有报错,结果也与预期一样:
优化后的代码结果如下:
x = torch.ones(2,requires_grad=True)
z = x + 2
z.sum().backward() # 对矩阵z先求和,再求导
print(x.grad)
>>>
tensor([1., 1.])
进阶实例01:
假设叶子节点、结果节点的计算满足如下关系,则求解 o u t out out分别对 x 1 , x 2 x_1, x_2 x1,x2的偏导数:
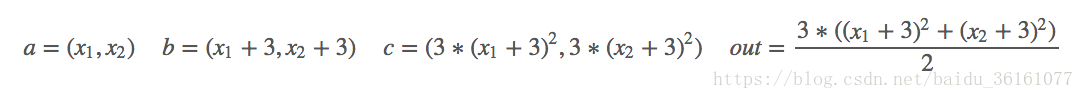
数学计算——对 x 1 , x 2 x_1, x_2 x1,x2分别求偏导:
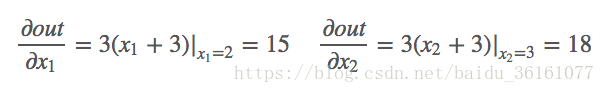
import torch
from torch.autograd import Variable
a = Variable(torch.Tensor([2,3]), requires_grad = True) # torch.Tensor([2, 3])用于生成新张量,新张量的为tensor([2., 3.], requires_grad=True)
b = a+3
c = b*b*3
out = c.mean()
print(a)
print(b)
print(c)
print(out)
>>>
tensor([2., 3.], requires_grad=True)
tensor([5., 6.], grad_fn=<AddBackward0>)
tensor([ 75., 108.], grad_fn=<MulBackward0>)
tensor(91.5000, grad_fn=<MeanBackward0>)
# 求导
out.backward()
print('input num is :{}'.format(a.data))
print('compute result is :{}'.format(out))
print('input gradients are: {}'.format(a.grad.data))
torch.autograd.Variable模块说明:
注:torch.autograd.Variable是Autograd的核心类,它封装了Tensor,并整合了反向传播的相关实现
Varibale包含三个属性:
•data:存储了Tensor,是本体的数据
•grad:保存了data的梯度,grad本身也是个Variable而非Tensor,与data形状一致
•grad_fn:指向Function对象,用于反向传播的梯度计算之用。
进阶实例02:
k.backward(parameters)接受的参数parameters必须要和k的大小一模一样,然后作为k的系数传回去,backward里传入的参数是每次求导的一个系数。
(1)若定义输入 m = ( x 1 , x 2 ) = ( 2 , 3 ) m=(x_1,x_2)=(2,3) m=(x1,x2)=(2,3),然后我们做的操作就是 n = ( x 1 2 , x 2 3 ) n= (x_1^2 , x_2^3) n=(x12,x23),这样我们就定义好了一个输出向量 n n n,结果第一项只和 x 1 x_1 x1有关,第二项只和 x 2 x_2 x2有关,那么求解输出向量 n n n的梯度,数学求导过程如下:
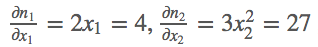
代码执行过程如下:
import torch
from torch.autograd import Variable
#(1) 若定义输入m=(x1,x2)=(2,3),而n= (x1**2,x2**3),则
m = Variable(torch.Tensor([[2,3]]), requires_grad = True)
n = Variable(torch.zeros(1,2))
print(m)
print(n)
n[0,0] = m[0,0] ** 2
n[0,1] = m[0,1] ** 3
n.backward(torch.Tensor([[1,1]]))
print(m.grad.data)
>>>
tensor([[ 4., 27.]])
(2)若定义输入 m = ( x 1 , x 2 ) = ( 2 , 3 ) m=(x_1,x_2)=(2,3) m=(x1,x2)=(2,3),然后我们做的操作就是 k = ( x 1 2 + 3 ∗ x 2 , x 2 3 + 2 ∗ x 1 ) k= (x_1^2 +3*x_2, x_2^3 +2*x_1) k=(x12+3∗x2,x23+2∗x1),这样我们就定义好了一个输出向量 k k k,那么求解输出向量 k k k的梯度,数学求导过程如下:
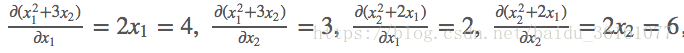
代码执行过程如下:
import torch
from torch.autograd import Variable
#(2) 若输入m=(x1,x2)=(2,3), 而k = (x1**2+3*x2,x2**2+2*x1),则
j = torch.zeros(2 ,2)
k = Variable(torch.zeros(1, 2))
k[0, 0] = m[0, 0] ** 2 + 3 * m[0 ,1]
k[0, 1] = m[0, 1] ** 2 + 2 * m[0, 0]
# [1, 0] dk0/dm0, dk1/dm0
k.backward(torch.FloatTensor([[1, 0]]), retain_graph=True) # 需要两次反向求导
j[:, 0] = m.grad.data
m.grad.data.zero_()
# [0, 1] dk0/dm1, dk1/dm1
k.backward(torch.FloatTensor([[0, 1]]))
j[:, 1] = m.grad.data
print('jacobian matrix is:{}'.format(j))
我们要注意
backward()里面另外的一个参数retain_variables=True,这个参数默认是False,也就是反向传播之后这个计算图的内存会被释放,这样就没办法进行第二次反向传播了,所以我们需要设置为True,因为这里我们需要进行两次反向传播求得jacobian矩阵。
参考链接:
Pytorch autograd,backward详解
pytorch中 backward 机制理解
可以看到backward函数有一个奇怪的参数:grad_tensors,在实现PyTorch的官方教程中可以发现:
import torch
x = torch.tensor([2, 3, 4], dtype=torch.float, requires_grad=True)
print(x)
>>>tensor([2., 3., 4.], requires_grad=True)
y = x*2
print(y)
>>>tensor([4., 6., 8.], grad_fn=<MulBackward0>)
while y.norm() < 1000: # `norm(X)`如果x是一个向量,那么norm(x)就等于x的模长
y = y*2
print(y)
>>>tensor([ 512., 768., 1024.], grad_fn=<MulBackward0>)
y.backward(torch.ones_like(y)) # `torch.ones_like`(input, dtype=None, layout=None, device=None, requires_grad=False) → Tensor,返回一个填充了标量值1的张量,其大小与之相同 input。
print(x.grad)
>>>tensor([256., 256., 256.])
接下来,分步讲解上述代码的执行过程:
- x = torch.tensor([2, 3, 4], dtype=torch.float, requires_grad=True)——创建一个张量x,并设置其参数
requires_grad=True。
备注:
设置创建张量x的参数requires_grad==True,则程序将会追踪所有对于该张量的操作,当完成计算后通过调用.backward(),自动计算所有的梯度, 这个张量的所有梯度将会自动积累到.grad属性。
- y = x*2——创建一个关于x的函数y,由于设置x的参数
requires_grad=True,所以y对应的用于求导的参数grad_fn=<MulBackward0>。这是因为在自动梯度计算过程中,还有另外一个重要的类Function。Tensor和Function互相连接生成一个非循环图,它表示和存储了完整的计算历史。每个张量都有一个.grad_fn属性,这个属性引用了一个创建了Tensor的Function(除非这个张量是用户手动创建的)即,这个张量的grad_fn==None,例如:步骤1中创建的张量x的grad_fn==None) - y.backward(torch.ones_like(y))——进行反向传播并输出x的梯度值,而这里出现了一个参数torch.ones_like(y)即为
grad_tensors参数,这里便引入了我们的问题:
为什么在求导的过程中需要引入这个参数,如果我们不引入这个参数的话,则会报下面的错误:
\quad
RuntimeError: grad can be implicitly created only for scalar outputs
\quad
即:提示我们输出的不是一个标量
下面就开始分析这个问题以及这个参数的作用。
backward函数:
结合上面两节的分析,可以发现,pytorch在求导的过程中,分为下面两种情况:
- 如果是 标量对向量求导(scalar对tensor求导) ,那么就可以保证上面的计算图的根节点只有一个,此时不用引入grad_tensors参数,直接调用backward函数即可;
- 如果是 (向量)矩阵对(向量)矩阵求导(tensor对tensor求导),实际上是先求出Jacobian矩阵中每一个元素的梯度值(每一个元素的梯度值的求解过程对应上面的计算图的求解方法),然后将这个Jacobian矩阵与grad_tensors参数对应的矩阵进行对应的点乘,得到最终的结果。
参考链接:PyTorch 的 backward 为什么有一个 grad_variables 参数?
Towser
PyTorch中torch.autograd的实现
torch.autograd提供了类和函数用来对任意标量函数进行求导。要想使用自动求导,只需要将所有的tensor包含进Variable对象中即可。
(1) torch.autograd.backward语法说明(详见:官方文档中关于torch.autograd说明)
torch.autograd.backward(variables, grad_variables, retain_variables=False)
核心功能:
Computes the sum of gradients of given variables w.r.t. graph leaves. 给定图的叶子节点variables, 计算图中变量的梯度和。
计算图可以通过链式法则求导。如果variables中的任何一个variable是 非标量(non-scalar)的,且requires_grad=True。那么此函数需要指定grad_variables,它的长度应该和variables的长度匹配,里面保存了相关variable的梯度(对于不需要gradient tensor的variable,None是可取的,例如:叶子节点)。
此函数累积leaf variables计算的梯度。你可能需要在调用此函数之前将leaf variable的梯度置零。
参数说明:
variables(variable 列表) – 被求微分的叶子节点,即 ys 。grad_variables(Tensor 列表) – 对应variable的梯度。仅当variable不是标量且需要求梯度的时候使用。retain_variables(bool) – True,计算梯度时所需要的buffer在计算完梯度后不会被释放。如果想对一个子图多次求微分的话,需要设置为True。
(2) torch.autograd.Variable语法说明(详见:官方文档中关于torch.autograd说明)
class torch.autograd.Variable [source]
核心功能:
包装一个Tensor,并记录用在它身上的operations。
Variable是Tensor对象的一个thin wrapper(包装),它同时保存着Variable的梯度和创建这个Variable的Function的引用。这个引用可以用来追溯创建这个Variable的整条链。如果Variable是被用户所创建的,那么它的creator是None,我们称这种对象为 leaf Variables。
由于autograd只支持标量值的反向求导(即:y是标量),梯度的大小总是和数据的大小匹配。同时,仅仅给leaf variables分配梯度,其他Variable的梯度总是为0。
(3) backward语法说明(详见:官方文档中关于torch.autograd说明)
backward(gradient=None, retain_variables=False)[source]
核心功能:
当前Variable对leaf variable求偏导。
计算图可以通过链式法则求导。如果Variable是 非标量(non-scalar)的,且requires_grad=True。那么此函数需要指定gradient,它的形状应该和Variable的长度匹配,里面保存了Variable的梯度。
此函数累积leaf variable的梯度。你可能需要在调用此函数之前将Variable的梯度置零。否则,梯度不置零将出现结果累加。
总结:如果需要计算导数,可以在
Tensor上调用.backward()。
- 如果Tensor是一个标量(即它包含一个元素的数据),则不需要为backward()指定任何参数
- 但是如果Tensor是 非标量(即:它包含更多的元素),则需要指定一个gradient参数,它是形状匹配的张量。
实例演示:
Question:计算函数对于变量x的导数?
即:当前Variable(理解成函数Y)对leaf variable(理解成变量X=[x1,x2,x3])求偏导。
计算图可以通过链式法则求导。如果Variable是 非标量(non-scalar)的(即:Y中有不止一个y,即Y=[y1,y2,…]),且requires_grad=True。那么此函数需要指定gradient,它的形状应该和Variable的长度匹配(这个就很好理解了,gradient的长度体与Y的长度一直才能保存每一个yi的梯度值),里面保存了Variable的梯度。
参数说明:
gradient(Tensor) –
其他函数对于此Variable的导数。仅当Variable不是标量的时候使用,类型和位形状应该和self.data一致。retain_variables(bool) – True,
计算梯度所必要的buffer在经历过一次backward过程后不会被释放。如果你想多次计算某个子图的梯度的时候,设置为True。在某些情况下,使用autograd.backward()效率更高。
典型范例:
import torch
a = torch.ones(2, 3, requires_grad=True) # 创建一个张量并设置requires_grad = True 为跟踪张量
print('input:',a.data)
'''情况1:out是一个标量(就是说一个输出值)'''
b = a+3
c = b*3
out = c.mean()
print(out)
out.backward()
print('input gradients are:', a.grad)
print(a.numel()) # #返回元素个数,所以c关于a的导数应该是[(a+3)*3]/6 就是0.5
"""情况2:out是一个向量(就是说输出一列值)"""
a = torch.ones(2, 1, requires_grad=True)
b = torch.zeros(2,1)
print(a)
print(b)
>>>
tensor([[1.],
[1.]], requires_grad=True)
tensor([[0.],
[0.]])
b[0,0] = a[0,0]**2 + a[1,0]*5
b[1,0] = a[0,0]**2 + a[1,0]*5
print(b)
# (1)若直接调用b.backward(),不加任何参数,结果报错
b.backward()
print(a.grad)
>>>
RuntimeError: grad can be implicitly created only for scalar outputs
# (2)当输出为向量时,调用b.backward()需要输入一个gradient,其shape和变量y保持一致
b.backward(gradient=torch.ones(b.shape))
print(a.grad)
>>>
tensor([[ 4.],
[10.]])