提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
本来在写GAN生成手写数字这篇博客的时候,遇到了一些和梯度有关的代码没看懂,憋得自己很难受,赶紧把pytorch最基础的知识赶紧补了一下
在数学上,梯度就是由于偏导数组成的一个向量,其方向为多维曲面某点的方向导数最大值所在的方向。
一、pytorch里自动求导的基础概念
1.1、自动求导 requires_grad=True
一般来说,在tensor里需要设置requires_grad=True,这样tensor就能自动求导了。默认情况下requires_grad=False:
import torch
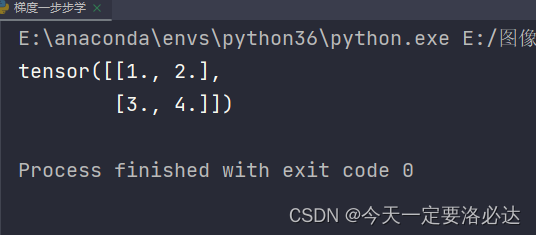
x = torch.tensor([[1.0,2.0],[3.0,4.0]])
print(x)
结果为:
我们将requires_grad设置为True:
import torch
x = torch.tensor([[1.0,2.0],[3.0,4.0]], requires_grad=True)
print(x)
结果为:
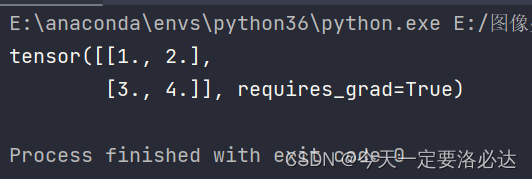
在这里可以看到求导开关被打开了。我们指定矩阵x可以求导
1.2、求导 requires_grad=True是可以传递的
我们设置一个函数y=x**2+2x+1,因为x是可以自动求导的,那么y也是
import torch
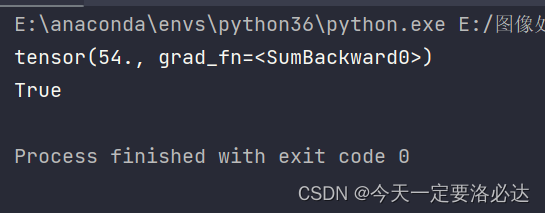
x = torch.tensor([[1.0,2.0],[3.0,4.0]], requires_grad=True)
y=torch.sum(x**2+2*x+1)
print(y)
print(y.requires_grad)
1.3、tensor.backward() 反向计算导数
使用backward() 函数,以本题为例,就能算出y在x上每个元素的导数,使用来查看x.grad梯度信息。梯度就是由tensor.backward()产生的
import torch
x = torch.tensor([[1.0,2.0],[3.0,4.0]], requires_grad=True)
print(x.grad)
y=torch.sum(x**2+2*x+1)
y.backward()
print(x.grad)
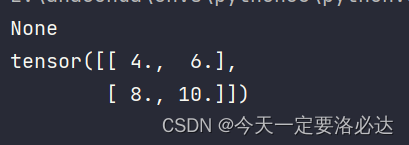
从这张结果图能看出,最开始直接打印x.grad的梯度信息是没有的,而是在backward()后,再使用x.grad才会看到梯度信息。
1.4、tensor的梯度是可以累加
张量的梯度是可以一直叠加的,一般都会在用之前把梯度清零(optim.zero_grad())
x = torch.tensor([[1.0,2.0],[3.0,4.0]], requires_grad=True)
print(x.grad)
y1=torch.sum(x**2+2*x+1)
y1.backward()
print(x.grad)
#进行梯度叠加
y2=torch.sum(x)
y2.backward()
print(x.grad)

y2对于x的梯度是1(x求导为1),所以后续x矩阵的值都加上了1。
二、tensor.detach()梯度截断函数
张量截断的应用,我第一次是在生成对抗网络中见到的,当时是为了截断梯度,防止判别器的梯度传入生成器:
fake_image = g_net(noises.detach()).detach()
tensor.detach()梯度截断函数的解释如下:会返回一个新张量,阻断梯度传播
我们来看一个梯度截断的简单例子。
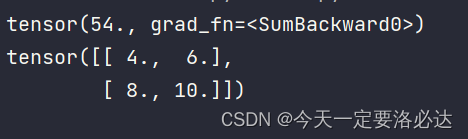
正常情况下,代码的结果应该是:
x = torch.tensor([[1.0,2.0],[3.0,4.0]], requires_grad=True)
y=torch.sum(x**2+2*x+1)
print(y)
y.backward()
print(x.grad)
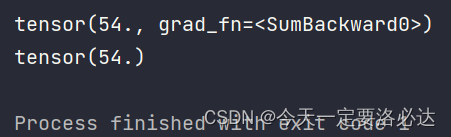
进行梯度截断之后:
import torch
x = torch.tensor([[1.0,2.0],[3.0,4.0]], requires_grad=True)
y=torch.sum(x**2+2*x+1)
print(y)
y = y.detach()
print(y)
y.backward()
print(x.grad)
代码会直接报错:

同时再次打印y,张量里的grad_fn=SumBackward0直接不见了:
三、with torch.no_grad()函数
这部分简要阐述一一下就行。
在代码里面,神经网络求梯度和求导是需要吃内存的,但是有些操作是不需要求梯度的(比如统计每一轮的损失,损失求平均这些)。为了节约内存,人们总是喜欢在这些代码前面加上with torch.no_grad()函数。下面就是个很好的例子:
# 得到生成器的损失
g_optim.zero_grad()
fake_output = dis(gen_img)
g_loss = loss_function(fake_output,
torch.ones_like(fake_output))
g_loss.backward()
g_optim.step()
d_epoch_loss += d_loss
g_epoch_loss += g_loss
d_epoch_loss /= batch_count
g_epoch_loss /= batch_count
D_loss.append(d_epoch_loss)
G_loss.append(g_epoch_loss)
print('Epoch:', epoch)
gen_img_plot(gen, test_input)
你可以很明显看出后面的代码是不需要求梯度的,为了节约内存所以会改成:
# 得到生成器的损失
g_optim.zero_grad()
fake_output = dis(gen_img)
g_loss = loss_function(fake_output,
torch.ones_like(fake_output))
g_loss.backward()
g_optim.step()
with torch.no_grad():
d_epoch_loss += d_loss
g_epoch_loss += g_loss
with torch.no_grad():
d_epoch_loss /= batch_count
g_epoch_loss /= batch_count
D_loss.append(d_epoch_loss)
G_loss.append(g_epoch_loss)
print('Epoch:', epoch)
gen_img_plot(gen, test_input)
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。