引言
一般训练神经网络,总是逃不开optimizer.zero_grad之后是loss(后面有的时候还会写forward,看你网络怎么写了)之后是是net.backward之后是optimizer.step的这个过程。
real_a, real_b = batch[0].to(device), batch[1].to(device)
fake_b = net_g(real_a)
optimizer_d.zero_grad()
# 判别器对虚假数据进行训练
fake_ab = torch.cat((real_a, fake_b), 1)
pred_fake = net_d.forward(fake_ab.detach())
loss_d_fake = criterionGAN(pred_fake, False)
# 判别器对真实数据进行训练
real_ab = torch.cat((real_a, real_b), 1)
pred_real = net_d.forward(real_ab)
loss_d_real = criterionGAN(pred_real, True)
# 判别器损失
loss_d = (loss_d_fake + loss_d_real) * 0.5
loss_d.backward()
optimizer_d.step()
上面这是一段cGAN的判别器训练过程。标题中所涉及到的这些方法,其实整个神经网络的参数更新过程(特别是反向传播),具体是怎么操作的,我们一起来探讨一下。
参数更新和反向传播
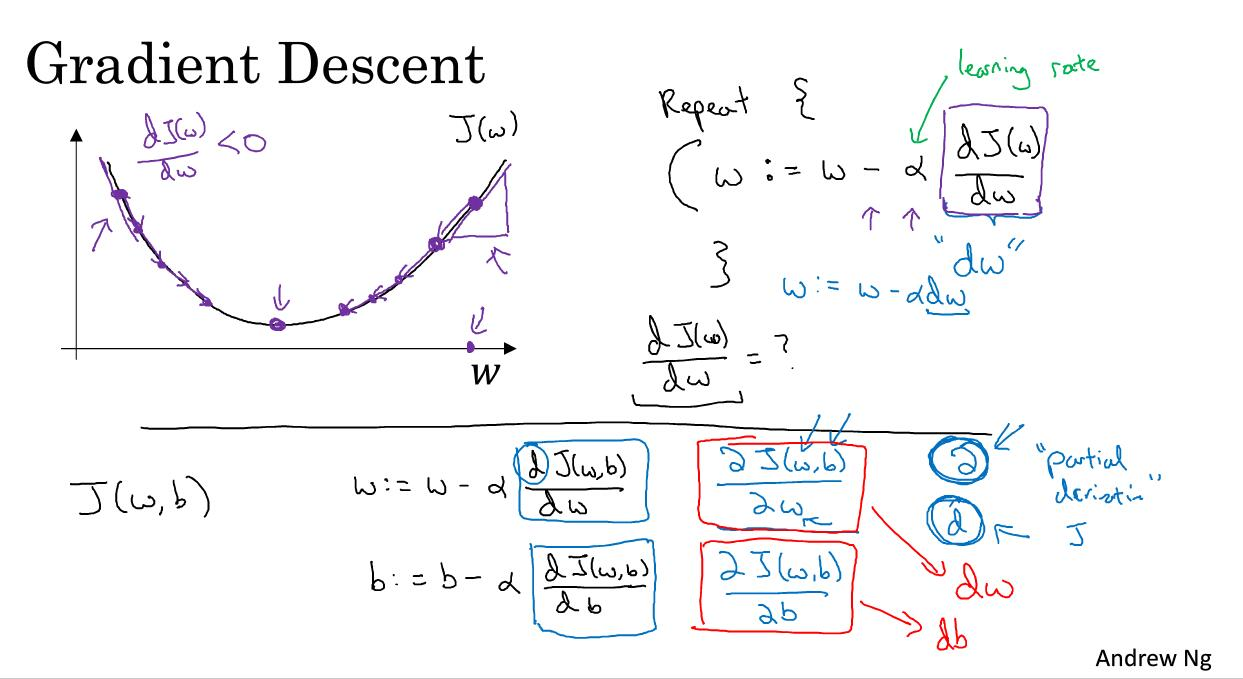
上图为一个简单的梯度下降示意图。比如以SGD为例,是算一个batch计算一次梯度,然后进行一次梯度更新。这里梯度值就是对应偏导数的计算结果。显然,我们进行下一次batch梯度计算的时候,前一个batch的梯度计算结果,没有保留的必要了。所以在下一次梯度更新的时候,先使用optimizer.zero_grad把梯度信息设置为0。
我们使用loss来定义损失函数,是要确定优化的目标是什么,然后以目标为头,才可以进行链式法则和反向传播。
调用loss.backward方法时候,Pytorch的autograd就会自动沿着计算图反向传播,计算每一个叶子节点的梯度(如果某一个变量是由用户创建的,则它为叶子节点)。使用该方法,可以计算链式法则求导之后计算的结果值。
optimizer.step用来更新参数,就是图片中下半部分的w和b的参数更新操作。
参考
[1Pytorch optimizer.step() 和loss.backward()和scheduler.step()的关系与区别
[2]torch代码解析 为什么要使用optimizer.zero_grad()
