一、概述
顾名思义,字符串匹配就是在主字符串中找到与目标字符串(模式串)匹配的操作。
传统的串匹配算法可以概括为前缀搜索、后缀搜索、子串搜索。
本文主要从算法推演流程和分析,对常见的BF、RK、BM、KMP等算法进行阐述。
二、BF算法
BF:BruteForce,算法使用简单粗暴的方式,对主串和模式串进行逐个字符比较。
2.1 推演流程
主字符串:GTTATAGCTGGTAGCGGCGAA
模式串:GTAGCGGCG
-
第一轮,模式串和主串的第一个等长子串比较,发现第0位字符一致,第1位字符一致,第2位字符不一致:
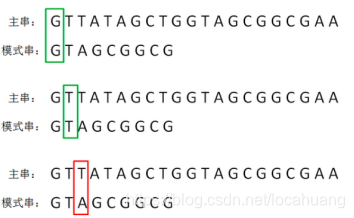
-
模式串向后挪动一位,和主串的第二个等长子串比较,发现第0位字符不一致
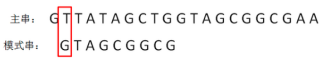
-
……依次类推,一直到第N轮:
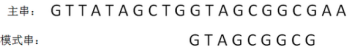
-
当模式窜挪动到某个合适位置,逐个字符比较,得到每一位都匹配时,比较结束

2.2 算法分析
通过以上推演流程,我们知道BF算法思想比较简单明了,对于长度相对较短的字符串或者效率要求不是很高的使用场来说还是可以用的。与此同时,BF算法的缺点也比较明显,就是效率太低,每一轮只能把模式串右移一位,实际上做了很多无谓的比较。
举个栗子:
主串:aaaaaaaaaaaaaaaaaaaaab
模式串:aaab
这种情况,在每一轮进行字符匹配时,模式串的前三个字符a都和主串中的字符相匹配,一直检查到模式串最后一个字符b,才发现不匹配:

假设主串的长度是m,模式串的长度是n,那么在这种极端情况下,BF算法的最坏时间复杂度是O(mn)。
三、RK算法
RK:全称Rabin-Karp,基于BF算法的一种改进,由算法的两位发明者Rabin和Karp的名字命名。利用比较两组字符串的哈希值实现。比较hash值是什么意思?
用过哈希表的朋友都知道,每一个字符串都可以通过某个哈希算法,转换成一个整型数,这个整型数就是hashcode:hashcode=hash(string)。
显然,相对于逐个比较两个字符串,仅仅比较两个字符串的hashcode要容易的多。
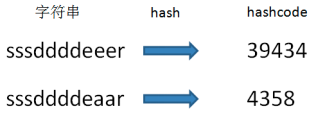
3.1 推演流程
主字符串:abbcefgh
模式串:bce
-
生成模式串的hashcode
生成方法有两种:
1)方法1:按位相加
这是最简单的方法,可以把a当做1,b当做2,c当做3….然后把字符串的所有字符相加,相加结果就是它的hashcode,如bce=2+3+5=10。这个算法虽然简单,但是很可能产生冲突,比如bce、bec、cbe的hashcode是一样的。2)方法2:转换成26进制数
既然字符串值包含26个小写字母,那么可以把每一个字符串当成一个26进制数来计算。
bce = 2*(26^2) + 3*26 + 5 = 1435,这样做好处是大幅减少了hash冲突,缺点是计算量较大,而且有可能出现超出整型范围的情况,需要对计算结果进行取模。我们这里为了方便演示,采用的是按位相加的hashcode算法,因此bce的hashcode是10。
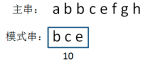
-
生成主字符串当中第一个等长子串的hashcode
abb=1+2+2=5
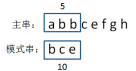
比较两个hashcode
5!=10,说明模式串与第一个子串不匹配,继续下一轮比较。 -
生成主串当中第二个等长子串的hashcode
bbc=2+2+3=7
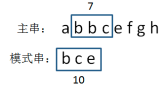
比较两个hashcode,7!=10说明模式串与第二个子串不匹配,继续下一轮比较。 -
生成第三个等长子串的hashcode
bce=2+3+5=10
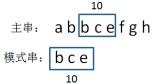
比较两个hashcode,10==10,两个hashcode相等。
由于存在hash冲突的可能,需要进一步验证。 -
逐个字符比较两个字符串
Hashcode的比较只是初步验证,之后还需要像BF算法那样对两个字符串比较,最终判断两个字符串是否匹配。
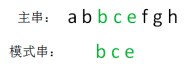
最后得出结论,模式串bce是主串abbcefgh的子串,第一次出现的下标是2。
3.2 算法分析
-
每次hash的时间复杂度是O(n),如果把全部子串都进行hash,总的时间复杂度岂不是和BF一样,都是O(mn)了吗?
答:对子串的hash计算并不是独立的,从第二个子串开始,每一个子串的hash都可以由上一个子串进行简单的增量计算得到。举个栗子:
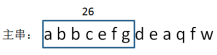
上图中,已知子串abbcefg的hashcode是26,那么如何计算下一个子串bbcefgd的hashcode呢?
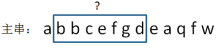
这时候没有必要把子串的字符重新进行累加计算,而是可以采用一个更简单的方法。由于新子串的前面少了一个a,后面多了一个d,所以:
新hashcode=旧hashcode-1+4=26-1+4=29再下一个子串bcefgde的计算也是同理:
新hashcode=旧hashcode-1+4=26-2+5=32 -
算法时间复杂度
RK算法计算单个子串hash的时间复杂度是O(n),但由于后续的子串hash是增量计算,所以总的时间复杂度仍然是O(n)。
相比于BF算法,RK算法采用哈希值比较的方式,免去了许多无谓的字符比较,所以时间复杂度大大提高了。 -
RK算法缺点
每一次哈希冲突的时候,RK算法都要对子串和模式串进行逐个字符的比较,如果冲突太多,RK算法就退化成BF算法了。
四、BM算法
BM 算法名称来自它的两位发明者Bob Boyer和Strother Moore。
BM算法借助“坏字符规则”和“好后缀规则”,在每一轮比较时,让模式串尽可能多挪动几位,减少了BF算法中很多无谓的比较。
4.1 推演流程
-
坏字符规则
“坏字符”指的是模式串和子串当中不匹配的字符。
举例说明:

1)如上图,当模式串和主串的第一个等长子串比较时,子串的最后一个字符串T就是坏字符。疑问:为什么坏字符不是主串第2位的字符T呢?这个位置不是最先被检测到的吗?
答:BM算法的检测顺序相反,是从字符串的最右侧向左测检测。这样检测顺序的目的是,当检测到第一个坏字符之后,我们就没有必要让模式串一位一位向后挪动比较了。因为只有模式串和坏字符T对齐的位置也是字符T的情况下,两者才有匹配的可能。
2)不难发现,模式串的第1位字符也是T,这样一来就可以对模式串做一次“乾坤大挪移”,直接把模式串当中的字符T和主串的坏字符对接,进行下一轮的比较。
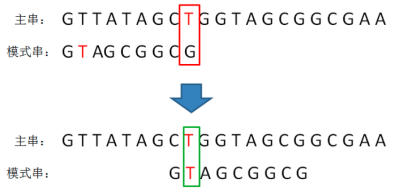
坏字符的位置越靠右,下一轮模式串的挪动跨度就可能越长,节省的比较次数也就越多。这就是BM算法从右向左侧检测的好处。3)接下来,继续逐个字符比较,发现右侧的GCG都是一致的,检测到主串中的字符A为坏字符:
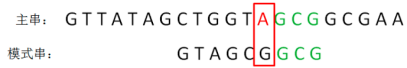
按照刚才的方式,找到模式串的第2位也是A,于是把模式串的字符A和主串中的坏字符对齐,进行下一轮的比较:
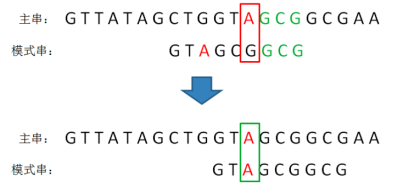
4)接下来,从右到左继续逐个字符比较,这次发现全部字符都是匹配的,比较完成:

5)“乾坤大挪移”说明:当坏字符在模式串不存在时,直接把模式串挪到主串坏字符的下一位。
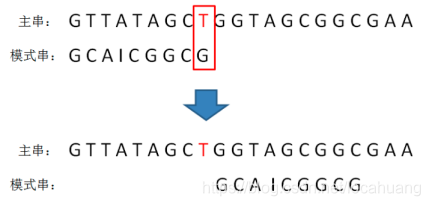
-
好后缀规则
“好后缀”指模式串和子串当中想匹配的后缀。举例说明:
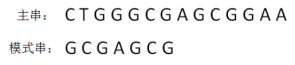
1)第一轮比较发现主串和模式串都有共同的后缀“GCG”,这就是所谓的“好后缀”。

如果模式串其他位置也包含与“GCG”相同的片段,就可以挪动模式串,让这个片段和好后缀对齐,进行下一轮的比较。
2)挪动
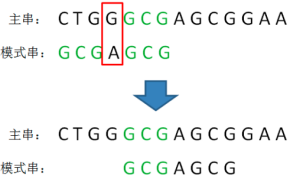
显然,在这个例子中,采用好后缀规则能够让模式串向后移动更多位,节省了更多无谓的比较。
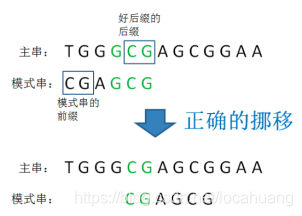
3)如果模式串中并不存在其他与好后缀相同的片段,该怎么处理?是否可以直接把模式串挪到好后缀之后呢?

答案是否定的。
我们不能直接挪动模式串到好后缀的后面,需要先判断一种特殊情况,模式串的前缀是否和好后缀的后缀相匹配,免得挪过头了。
4.2 算法分析
什么情况下使用坏字符规则,什么情况下使用好后缀规则?
答:可以在每一轮的字符比较之后,按照坏字符和好后缀规则分别计算相应的挪动距离,哪一种距离更长,就把模式串挪动对应的长度。
五、KMP算法
KMP算法名字取自发明这个算法的三位计算机科学家:D.E.Knuth、J.H.Morris、V.R.Pratt。 该算法目标是让模式串在每一轮尽量多移动几位,从而减少无所谓的字符比较。KMP算法把专注点放在“已匹配的前缀”。5.1 推演流程
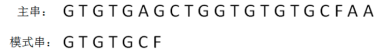
KMP算法与BF算法的“开局”是一样的,同样是把主串和模式串的首位对齐,从左到右逐个字符进行比较。
-
第一轮:模式串和主串的第一个等长子串比较,发现前5个字符都匹配,第6个字符不匹配,是一个“坏字符”:
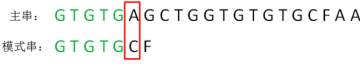
如何有效利用已匹配的前缀“GTGTG”呢?从上面观察可以发现,在前缀“GTGTG”当中,后三个字符“GTG”和前三位字符“GTG”是相同的。

在下一轮的比较时,只有把这两个相同的片段对齐,才有可能出现匹配。这两个字符串片段,分别叫做最长可匹配后缀子串和最长可匹配前缀子串。 -
第二轮,直接把模式串向后移动两位,让两个“GTG”对齐,继续从刚才主串的坏字符A开始进行比较:
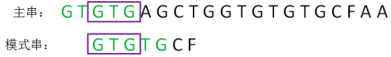
显然,主串的字符A仍然是坏字符,这时候的匹配前缀缩短成了GTG:
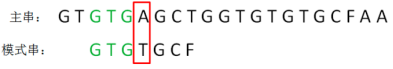
按照第一轮的思路,重新确定最长可匹配后缀子串和最长可匹配前缀子串:

-
第三轮:再次把模式串向后移动两位,让两个G对齐,继续从刚才主串的坏字符A开始进行比较:

上面就是KMP算法的整体思路:在已匹配的前缀当中寻找到最长可匹配后缀子串和最长可匹配前缀子串,在下一轮直接把两者对齐,从而实现模式串的快速移动。
5.2 算法分析
-
如何找到一个字符串前缀的“最长可匹配后缀子串”和”最长可匹配前缀子串”?难道每一轮都要重新遍历吗?
答:没有必要每次都去遍历,可以事先缓存到一个集合中,用的时候再去集合取。这个集合被称为next数组 ,如何生成next数组是KMP算法的最大难点。
-
next数组
next数组是一个一维整型数组,数组的下标代表了“已匹配前缀的下一个位置”,元素的值则是“最长可匹配前缀子串的下一个位置”。 -
回溯
回溯是相对于模式串来说,回溯多少取决于模式串共同的前缀和后缀有多少。


转载:https://blog.csdn.net/bjweimengshu/article/details/104528964?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.control&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.control