单模式串匹配算法
所谓单模式串匹配算法就是一个串跟一个串进行匹配,这种算法有BF算法和RK算法。而多模式串匹配算法算法就是一个串同时查找多个串,这种算法有Trie树和AC自动机。
BF算法
Bf算法即Brute Force,中文叫做暴力匹配算法,也叫朴素匹配算法。特点是简单、易懂、性能低。
主串和模式串:比如在字符串A中查找字符串B,那么字符串A就是主串,字符串B就是模式串。我们把主串的长度记做n,模式串的长度记做m。由于是在主串中查找模式串所以n>m。
BF算法简单粗暴,它的思想可以用一句话来概括,那就是:
我们在主串中,检查起始位置分别是0,1,2……n-m且长度为m的n-m+1个子串,看有没有跟模式串匹配的。
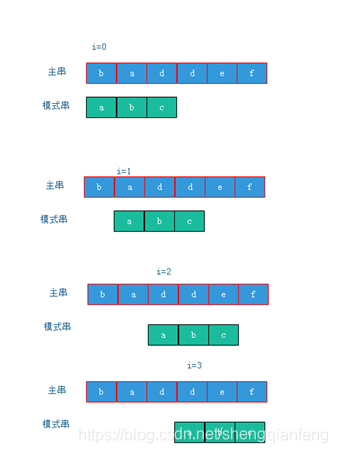
可以看出主串中药比对的是n-m+1个长度为m的子串,而且每一个子串跟模式串比较时,在极端情况下,每一个字符都比较就会比较m个字符,所以时间复杂度为O(n*m).
BF时间复杂度貌似挺高的,其实在实际开发中,它确实一个比较常用的字符串匹配算法,原因有二
- 其一:实际开发中大多数情况下,模式串和主串的长度都不长。而且每次模式串与主串中的子串比较时,只要遇到不能匹配的字符就中途退出了。不需要把m个字符都比对一下,所以,O(m*n)是理论复杂度,实际中算法执行效率肯定比这个高多了。
- 其二:BF算法的思想简单,代码实现也简单不易出错。
在实际开发中,绝大多数情况下,朴素的字符串匹配算法就够用了。
RK算法
Rk算法全称:Rabin-Karp算法,是由两位发明者Rabin和Karp的名字来命名,它其实就是BF算法的升级版。
BF算法的时间复杂度O(n*m)是因为在极端情况下子串和模式串需要比对每一个字符,所以可以对BF算法进行改造一下,引入hash算法时间复杂度就会立马降低。
RK算法思路:
通过hash算法堆主串中的n-m+1个子串分别求hash值,然后逐个与模式串的hash值比较大小,在不考虑hash冲突的前提下,只要子串的hash值跟模式串的hash值相等,那就说明子串和模式串是匹配的。Hash值是一个数字,数字之间的比较时非常快速的,这样依赖模式串跟子串的比较不再是一个个字符的比较,而是粗粒度hash值比较即可,比较效率就大大提高了。
但问题是,子串hash值的计算是一个低效的过程,这个过程需要遍历子串中的每个字符。因此整体RK算法效率并没有提高,要想真正提高RK算法的效率,这个问题就必须解决,即想办法提高计算子串hash值得效率,也就是计算子串hash值得哈希算法的设计问题。
如何设计一个高效的哈希算法?
如何设计一个高效的哈希算法,能够提高子串hash值得计算效率,假设要匹配的字符串的字符集中只包含K个字符,那么就可以利用一个K进制数来表示一个子串,这个K进制的数转化为十进制的数,作为子串的hash值。
举个例子:就好比要匹配的字符串的字符集是a-z这26个小写字母,那我们就可以用二十六进制来表示一个字符串,a-z这26个字符可以映射到0-25这26个数字,则a是0,b是1,以此类推,z表示25.如图

1353就是二十六进制计算cba的hash值,这种hash值计算方法有个特点,在主串中,相邻两个子串的hash值的计算公式有一定的关系。这里我只写出结论:
h[i] = 26 * ( h[i-1] - 26^(m-1) * ( s[i-1]-‘a’) + (s[i+m-1] - ’a’))
其中,h[i]和h[i-1]分别对应s[i]和s[i-1]两个子串的hash值。
也就是说,我们可以使用s[i-1]的hash值h[i-1]很快计算出s[i]的hash值h[i]
这种设计出来的哈希算法是没有散列冲突的,即一个子串就跟一个二十六进制的数对应,不同的字符串的hash值肯定不一样,因为我们是基于进制来表示一个字符串的。
其实就算是有散列冲突也不怕,只要不是太高都可以接受,当比对子串和模式串的散列值的时候如果相等,我们再比对下子串和模式串本身就行了,也不会低效很多。
所以说,RK算法的效率取决于哈希算法的设计方法,如果存在冲突的话,时间复杂度可能会退化,极端情况下,哈希算法大量冲突,每个子串散列值都跟模式串相等,时间复杂度就退化为O(n*m)了。
实际工作中,Rk算法很少见,可以学习下思想吧。
Rk算法的时间复杂度分析
RK算法分为两部分,计算子串hash值 + 模式串hash值比对子串hash值。
第一部分:计算子串的hash值可以通过设计特殊hash算法,只要扫描一遍主串就可以计算出所有子串的hash值,所以第一部分的时间复杂度O(n)
第二部分:模式串和子串hash值得比对时间复杂度O(1),一共需要比对n-m+1个子串的hash值,所以这部分的时间复杂度就是O(n),因此整体RK算法的时间复杂度就是O(n)