Lecture 9: Linear Regression线性回归
9-1 线性回归问题
信用额度问题:
x=(x0,x1,x2,...,xd)为顾客特征,y是输出的加权后的信用额度,线性回归假说为h,如图:

那么线性回归长什么样呢?在输入为一维时如左图,输入为二维时如右图:

线性回归分析想要做的就是找到一个最好的线或者最好的面,希望红色的线的部分越小越好。
那通常是怎么使得红色的线最小呢?一般是squared error的方式:
in-sample是训练样本,out-of-sample是测试样本。

那么现在的问题是,应当如何使Ein最小化?

9-2 线性回归算法
衔接9-1,所以要求得使得Ein最小的好的w。对Ein公式进行矩阵变换:
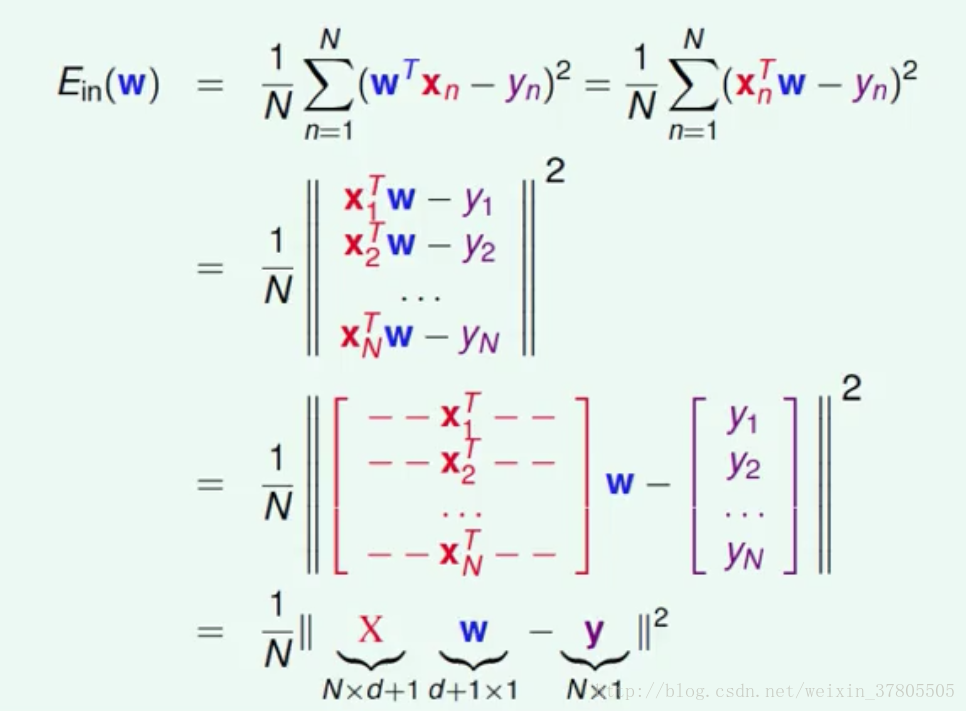
对变换后的公式进行分析:
Ein:连续可微凸函数,所以存在着全局最优点,此时是Ein的最小值,即一个好的w对应的Ein。故转换问题为找到使得Ein梯度为0的地方。
对Ein的公式变换:

其中,A为矩阵,b为向量,c为常数。
目标:找到梯度为0的点。此时求得一个好的w值:

9-3 一般化问题
9-2是一个公式就可以算出来的,这真的是机器学习吗?
是的,它会有好的Ein,好的Eout,而且算pseudo-inverse的过程并不是一步登天。所以如果这个方法的Eout是好的,那么机器学习过程已经发生了。
那么Eout为什么是好的呢?
我们需要看Ein的平均(对不同的data),得到的公式为:

d+1是自由度,有多少个不同的w;N是data的量。
证明过程为:

其中我们把XX^+叫做帽子矩阵(给y带了帽子变成y_height)
几何上来说,y_height会在下图粉红色的空间里:

那么我们想要的,就是y-y_height最小的时候,也即垂直投影的时候。
当我们考虑nosie的时候,上图变成了:

所以可以得到:

其中H是从y到y_height的投影(线性变换),I-H是求y-y_height余数部分的线性变换。
最终可以证得9-3最开始的公式,此外也可以相似地证明出Eout的公式,我们把公式得到的曲线叫做学习曲线:

我们可以得到:一般化的错误概率为:2(d+1)/N;并且在线性回归问题中,学习真的已经发生了。
9-4 线性分类和线性回归
classification和regression:前者是NP-难问题,而后者非常好解,那么可以用线性回归做二分类问题吗?
那么两者最大的区别,是对平方的衡量:

当y=1或-1时,两者的图形化区别为:

可以看出:平方的error都比0/1的error大。

回到9-4最开始的问题,答案是肯定的。我们可以用regression做classification问题(一个宽松的bound)。
注:从本次笔记开始,以后绿色标记统一为着重强调内容,紫色标记统一为不完全理解的内容。
另外,没有特别声明的,“机器学习基石课程”分类中所有博文的配图,都来自台湾大学《机器学习基石》网络课程截图。