之前学习的演算法都是建立在理想的数据上的,也就是我们的数据没有所谓的噪声,在无噪声的数据上算法是可行的,那么在实际中数据通常是很杂乱的,会有很多的噪声存在,那么在这些数据中,我们的算法是否还可行呢?
上一讲学习了VC维的相关知识,我们知道如果我们有一个dvc,数据足够的多,并且可以得到足够小的Ein,那么就认为学习是可行的。接下来来学习在有噪声的数据中,我们的学习是怎么样的呢?

Noise and Probabilistic Target
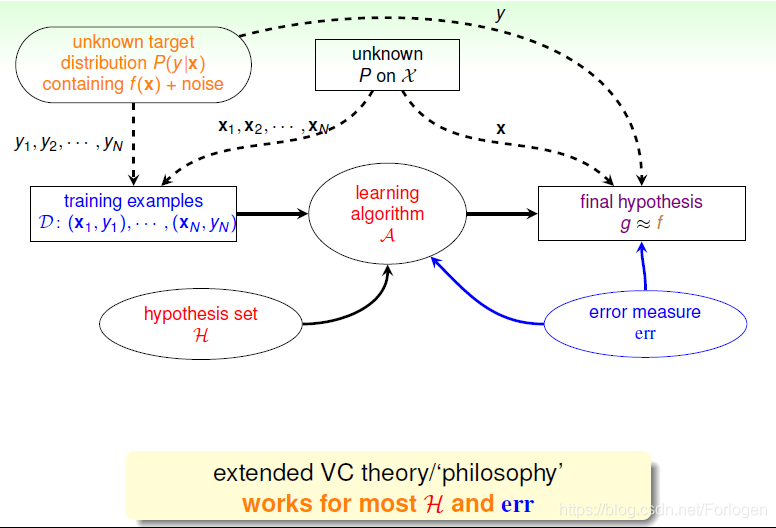
在数据中有噪声后,我们的学习流程图如下
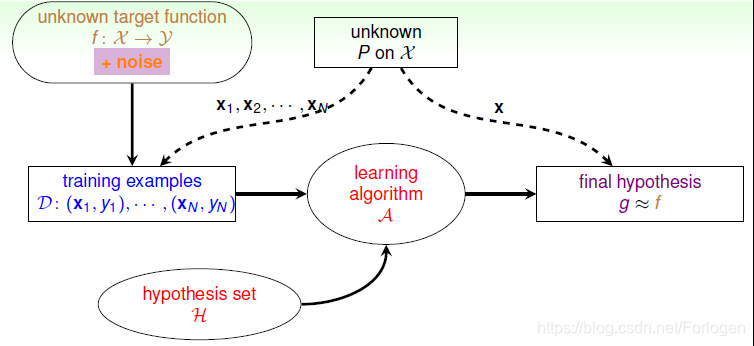
那么噪声是怎么存在的呢?例如在之前的二分类问题中,总会有某些点无法分类正确,那么它们就是数据中存在的噪声。

再比如在提到的信用卡的例子中,在数据的采集中,由于人为的原因,会导致数据输入的错误;又比如数据没有太多的错误,但是在审批时可能会驳回本应该可以得到审批的用户,这样的决策也是噪声;或是对于同一客户,不同的工作人员也可能做出不同的决策,这也是噪声……总之在实际的应用场景中,噪声是无法避免的。

这就提出一个问题,之前学习的VC bound在有噪声的数据中能否正常的工作呢?之前我们想知道一个瓶子中的某种颜色的弹珠是怎么做的呢?采用的方法时抽样,通过多次抽样计算每次抽样中弹珠的比例来猜测整个瓶子中的比例,根据统计学的知识,在数据足够的情况下,我们就可以说抽样的比例就是整体样本中的比例。

没有噪声的数据我们称之为deterministic,数据满足某种分布,我们的假设得出的结果要么满足f(x)=h(x),要么就不等于。但是在有噪声的数据中,就不是这么个情况了,也就是说在某个x处不在是确定的分布了,而是满足某种概率分布P(y|x).
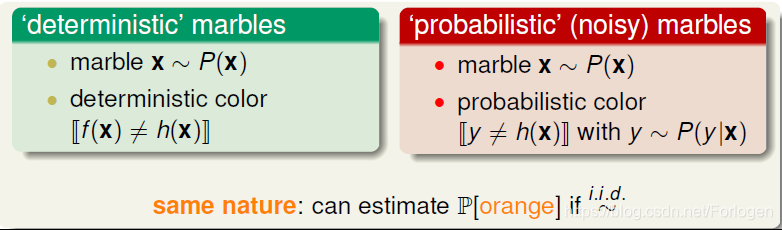
经过相关的证明我们可以得到:在x和y满足如下的分布,也就是x,y满足某种联合概率分布时,VC bound仍然是可行的。
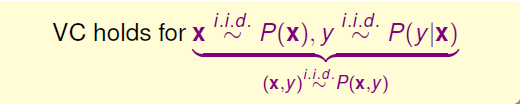
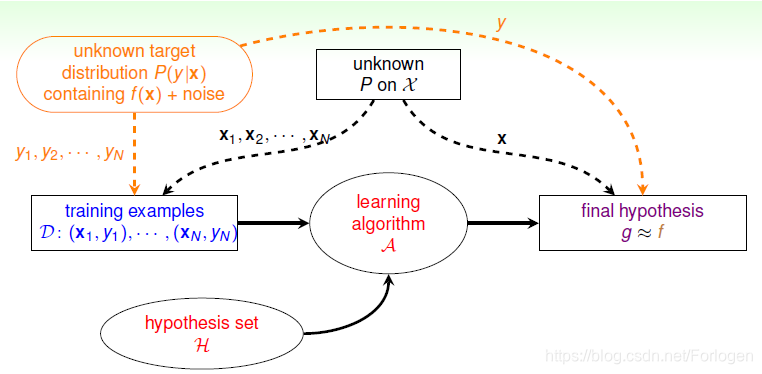
这里将P(y|x)称之为Target Distribution,它告诉我们最好的选择是什么,同时伴随着多少noise,即可以写成P(y|x)≈ideal mini-target + noise。比如如下的例子中,在某个x下,o的概率为0.7,×的概率为0.3,那么我们就可以说ideal mini-target为o,浮动的噪声的水平也就是0.3。其实,没有noise的数据仍然可以看成“特殊”的概率分布,即概率仅是1和0。

在这种情况下,学习的目标就变成在在x的输入上,预测最理想的概率分布P(y|x)。

学习的流程图就变成了这样
Error Measure
在之前的学习中,我们希望学习到一个g使它可以很好的接近数据中隐含的f。

那么如何来衡量模型的错误呢?之前我们通过数据学习到一个模型后,在未知的数据集上对每一个数据,通过如下的公式来计算Eout(g)。我们介绍的g对错误的衡量有三个特性:
• outofsample:样本外的未知数据
• pointwise:对每个数据点x进行测试
• classification:看prediction与target是否一致

比如在二分类问题中,结果就是对或不对,也就是常说的0/1 error。

因此在实际中一般使用如下的公式计算Eout(g),将err称之为PointWise error。它实际上就是对数据集的每个点计算错误并计算平均, Ein和Eout的pointwise error的表达式为:

下面介绍两种常用的pointwise error,为了方便我们引入下面的记号

一种是之前的0/1 error,只关注对错与否,通常用在分类问题中,比如之前的感知机算法;另一种是平方误差,它表示了预测值与真实值的距离,通常用在回归算法中,比如后面学到的线性回归等。

了解了常用的error后,需要明白它是如何的指导演算法的学习的呢?

通过条件概率和error来共同得到最理想的f(x)。

0/1 error和squared error的Ideal Mini Target计算方法不一样。例如下面这个例子,分别用0/1 error和squared error来估计最理想的mini target是多少。0/1 error中的mini target是取P(y|x)最大的那个类,而squared error中的mini target是取所有类的加权平方和。

在知道了上面的错误衡量后,我们可以使用error measure来指导演算法,使得到的g更加接近目标的f。学习流程图变成了如下
比如在常见的指纹识别中,根据f的值来决定是否识别成功。
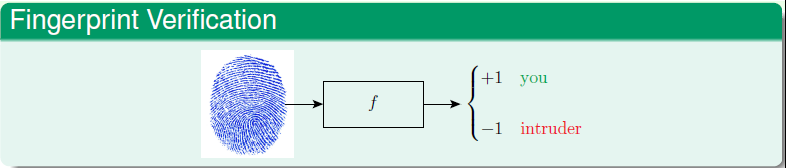
error常见的有两种,false accept和false reject,false accept表示不该接受的却错误的接受了;false reject表示错误的接受,即把闯入者当成了合法的用户。

这理论上把这两种错误的代价看成是一样的了,发生的不同的错误对于结果的影响是相同的。但是实际中,却不是这样。比如在超市营销中,如果某个用户没有优惠但是系统错误的给了优惠,那么结果可能就是超市减少点盈利,不会有太大的影响,所以我们可以将false accept的代价值记为1;而如果某用户本应该有优惠但没有改,那么用户就不开心了,再一传十十传百,将会对超市的营收造成很大的影响,故将false reject的代价记为10。

在其他的实际应用中,我们可以根据不同的应用场景对于不同的错误设置不同的代价值。

在应用中,机器学习演算法A的cost function error估计有多种方法,真实的err一般难以计算,常用的方法可以采用plausible或者friendly,根据具体情况而定。plausible是指采用一种可以是用户满意的方式控制噪声的存在,比如尽可能最小化flipping noise或者是认为噪声是满足高斯分布的。另一种是采用一种“友好的方法”,可以被演算法很好的使用。

将误差衡量加入到学习中后,学习的流程图就变成了如下的形式:我们的目标 变成了err,而且err_hat也成为了演算法中的关键的部分。

实际上,机器学习的Cost Function即来自于这些error,也就是算法里面的迭代的目标函数,通过优化使得Error(Ein)不断变小。
通常使用的是最小化有权重的分类中,我们通过最小化带权重的Ein(h)来达到学习的目标。在PLA中,主要是线性可分的就不太关注err。但是在pocket算法中,如果想要使用误差衡量,我们就需要调整一下

比如在之前的数据中,代价值如图所示,在引入误差衡量后,代价均为1,但是我们可以将对应的数据复制1000次,来达到相同的效果。

在cost function中,false accept和false reject赋予不同的权重,在演算法中体现。对不同权重的错误惩罚,可以选用virtual copying的方法。

最后总结一下,通过这一将我们知道,即使数据集中含有噪声,VC Dimension仍然是成立的,我们的学习也是可行的。也了解了两种常用的误差衡量,同时也要明白,需要根据实际的场景设置不同的代价值。最后介绍了如何在pocket算法中经过调整来引入误差衡量。
