前面主要学习了有关机器学习的基础知识,如VC维、误差衡量等,上一讲知道了即使是在 含有噪声的数据中,我们的学习也是可行的。这一讲开始学习第一个学习算法:线性回归,主要是从下面四个方面进行学习

比如之前的信用卡的例子,用户提交了一系列的数据后,我们如何根据用户数据给出具体的透支的额度呢?用分类的方法显然不能很好的解决这个问题,回归算法就是一个很好的选择。

如下图所示,用户的信息有年龄、年收入、工作年限和当前的债务,为了后面更好的采用数学的方式来进行阐述,我们使用xi来表示用户的特征,对每个特征数据加权求和来得到一个加权和作为最后的y,权重用w表示

将数据用矩阵表示,这样我们的假设就是如下的形式,类似之前的感知机算法假设的样子,但是没有取符号函数sign(x)

那么这个假设在数据中是怎么样表现的呢?例如在二维平面上,画好坐标轴后,将数据描点,得到的假设h就是图中的蓝线;如果是在三维空间中,h(x)就是蓝色的平面。我们将图中点到线(或面)的距离称为余数或是差距 (红线的长度)

而线性回归算法的目标就是找到一个合适的h(x)来减小各个点的h(x)差距

那么如何表示这种差距嘞?这里最常用的就是上一讲提到过的平方误差(y_hat表示我们假设得到的预测值)
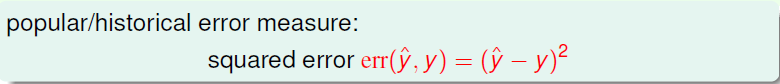
将训练数据中得到的误差的平均值作为我们的Ein,而将未知数据的误差值作为Eout

接下来主要问题就转换成了如何在最小化Ein(W )?这和我们之前的学习的思路是一致的
如上面in-sample中Ein的表达式所示,我们进行一系列的转换和矩阵表示,最后可以得到Ein(w)=1/N * ||XW-Y||^2,其中各个矩阵的形式图中已标出

目标就是如下表达式,其中X和y都是已知的,只有权重矩阵W是需要我们去求的,如果能够得到想要的W,那么Ein就会足够小到我们的要求。
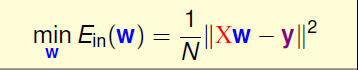
在这里表达式是连续可微的凸函数,画出来如左下图所示,既然是凸函数,就可以使用求梯度为零(梯度为零是说在各个方向上都为零)的点来得到WLIN.

再将表达式做一点变换
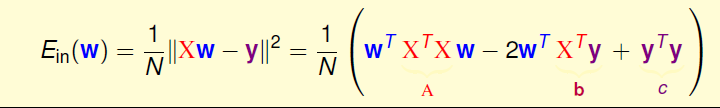
如果这里的W是一维的情况,求偏导数为零的点是很容易的;如果W是矩阵表示的,同样是求偏导数为零的点,可能有一点复杂而已。

所要做的就是使▽Ein(W)=0
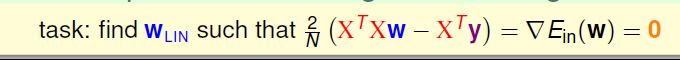
具体的计算过程这里没有给出,详细的可见之前写过的一篇线性回归

最终,我们推导得到了权重向量
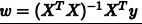
其中(xTx)^-1xTy, 又称为伪逆矩阵pseudoinverse,记为x+,维度是(d+1)xN。这样就得到了学习的最终结果,代入上面的假设就可以使Ein足够的小。
但是,我们注意到,伪逆矩阵中有逆矩阵的计算,逆矩阵是否一定存在?一般情况下,只要满足样本数量N远大于样本特征维度d+1,就能保证矩阵的逆是存在的,称之为非奇异矩阵。但是如果是奇异矩阵,不可逆怎么办呢?其实,大部分的计算逆矩阵的软件程序,都可以处理这个问题,也会计算出一个逆矩阵。所以,一般伪逆矩阵是可解的。
现在,可能有这样一个疑问,就是这种求解权重向量的方法是机器学习吗?或者说这种方法满足我们之前推导VC Bound,即是否泛化能力强Ein≈Eout?

有两种观点:1、这不属于机器学习范畴。因为这种closed-form解的形式跟一般的机器学习算法不一样,而且在计算最小化误差的过程中没有用到迭代。2、这属于机器学习范畴。因为从结果上看, 和都实现了最小化,而且实际上在计算逆矩阵的过程中,也用到了迭代。其实,只从结果来看,这种方法的确实现了机器学习的目的。下面通过介绍一种更简单的方法,证明linear regression问题是可以通过线下最小二乘法方法计算得到好的和的。

首先,我们根据平均误差的思想,把Ein(Wlin)写成如图的形式,经过变换得到:
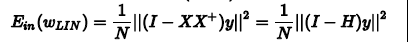
我们称XX+为帽子矩阵,用H表示。下面从几何图形的角度来介绍帽子矩阵H的物理意义





之前介绍的Linear Classification问题使用的Error Measure方法用的是0/1 error,那么Linear Regression的squared error是否能够应用到Linear Classification问题?

下图展示了两种错误的关系,一般情况下,squared error曲线在0/1 error曲线之上。

根据之前的VC理论, Eout的上界满足:

从图中可以看出,用erragr代替err0/1, Eout仍然有上界,只不过是上界变得宽松了。也就是说用线性回归方法仍然可以解决线性分类问题,效果不会太差。二元分类问题得到了一个更宽松的上界,但是也是一种更有效率的求解方式。

具体参见线性回归
最后总结一下,这一讲我们主要介绍了Linear Regression。首先,我们从问题出发,想要找到一条直线拟合实际数据值;然后,我们利用最小二乘法,用解析形式推导了权重w的解;接着,用图形的形式得到Eout-Ein≈2(N+1)/N,证明了linear regression是可以进行机器学习的,;最后,我们证明linear regressin这种方法可以用在binary classification上,虽然上界变宽松了,但是仍然能得到不错的学习方法。