前言
前面两篇笔记写了卷积神经网络的两个部件,即卷积层与反卷积层,这篇笔记写池化层与反池化层。池化是一种很重要的下采样方法,它像水池一样汇集一个小区域内的值,并总结浓缩成一个值输出,常用的有最大池化Maxpooling——选择最大值输出,和平均池化Avepooling——取平均值作为输出。反池化,是一种和转置卷积类似的上采样方法,在分割任务中会用到。分组卷积是一种使模型轻量化的方法,本笔记也将浅浅的记录。本笔记的知识框架主要来源于深度之眼,并依此作了内容的丰富拓展,拓展内容主要源自对torch文档的翻译,对孙玉林等著的PyTorch深度学习入门与实战的参考和自己的粗浅理解,所用数据来源于网络。发现有人在其他平台照搬笔者笔记,不仅不注明出处,有甚者更将其作为收费文章,因此笔者将在文中任意位置插入识别标志。
笔记是笔者根据自己理解一字一字打上去的,还要到处找合适的图片,有时为了便于理解还要修图,原创不易,转载请注明出处,文中笔者哪怕是引图也注明了出处的
结果可视化见:深度之眼Pytorch打卡(十):Pytorch数据预处理——数据统一与数据增强(上)
卷积操作见:深度之眼Pytorch打卡(十四):Pytorch卷积神经网络部件——卷积操作与卷积层、转置卷积操作与转置卷积层(反卷积)(对卷积转置卷积细致动图分析)
转置卷积操作见:深度之眼Pytorch打卡(十五):Pytorch卷积神经网络部件——转置卷积操作与转置卷积层(对转置卷积操作全网最细致分析,转置卷积的stride与padding,转置与反卷积名称论证)
池化与池化层
池化(pooling)是一种下采样方法,其能在保持数据空间特征的同时减少数据大小1,进而减少冗余信息,降低训练时的运算量。最常用的主要包括最大池化和平均池化,即对区域内的值进行总结的方法是取最大值和取平均值。池化没有参数,故一般不算入卷积神经网络层数,它常常放在连续的卷积操作中间,卷积-池化-卷积-池化是较为典型的结构。
最大池化:
用区域内的最大值(响应)来代表该区域的所有值(响应),移位过程有点像卷积,但它是非线性运算,并且相邻两次移动到的区域一般不重叠,即stride=kernel_size,操作过程如图1所示,其摘自国外的文章:Convolution Neural Network。kernel_size=2,stride=2是最常用的池化超参数。
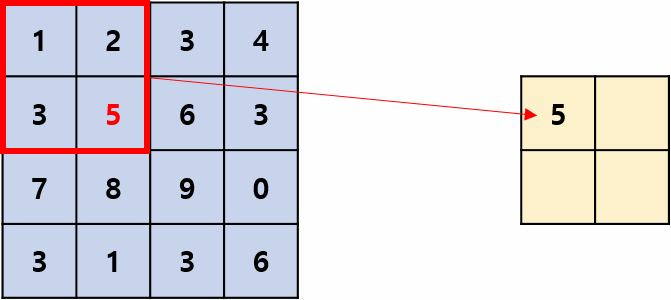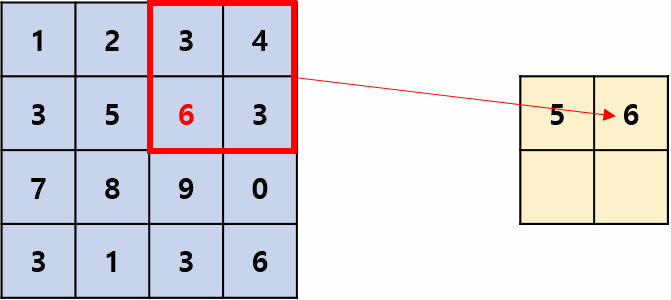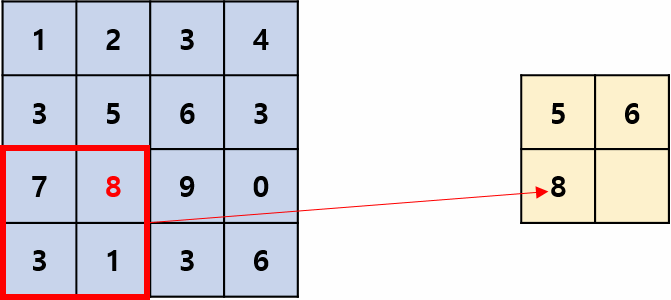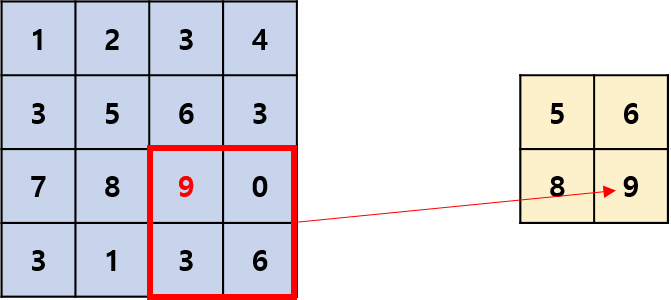
平均池化:
用区域内的平均值(响应)来代表该区域的所有值(响应),操作过程如图2所示,其摘自国外的文章:Convolution Neural Network。平均池化是线性运算。
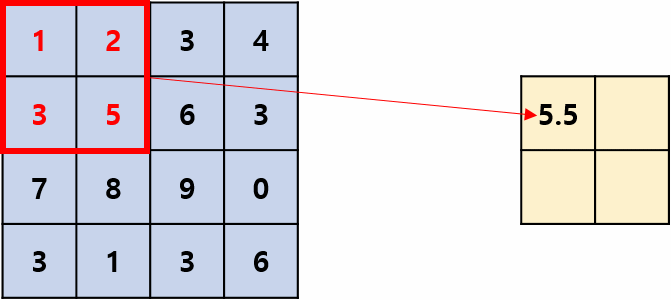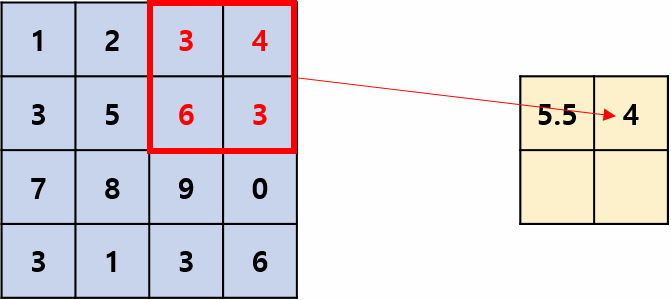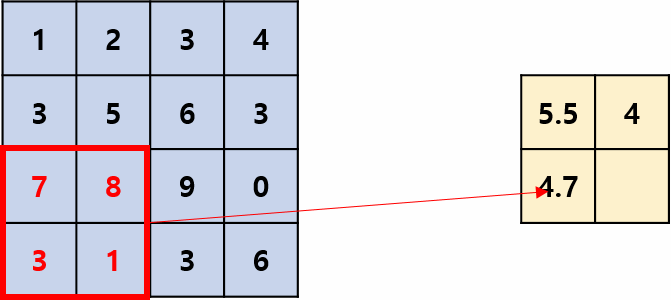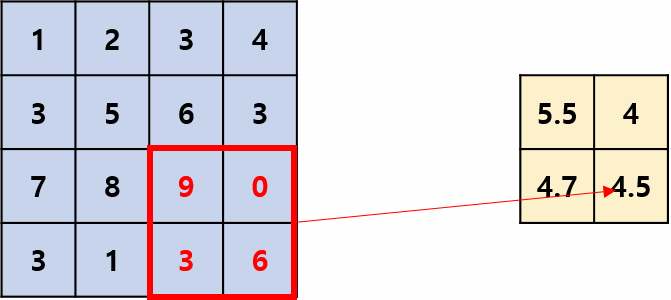
最大池化层:
Pytorch的最大池化层有三个,即nn.MaxPool1d()、nn.MaxPool2d()、nn.MaxPool2d()。这里只单独学习最最常用的nn.MaxPool2d(),其他的都类似或者相同。
CLASS torch.nn.MaxPool2d(kernel_size: Union[int, Tuple[int, ...]],
stride: Union[int, Tuple[int, ...], None] = None,
padding: Union[int, Tuple[int, ...]] = 0,
dilation: Union[int, Tuple[int, ...]] = 1,
return_indices: bool = False,
ceil_mode: bool = False)
# (CSDN意疏原创笔记:https://blog.csdn.net/sinat_35907936/article/details/107833112)
return_indices: 如果为True,该函数类除了返回池化结果外,还会返回输入中每个最大值所在位置的索引(indices)。 在用MaxUnpool2d做上采样(反池化)时需要该参数。
ceil_mode: 输出尺寸取整方式,默认向下取整(floor),当ceil_mode为True时向上取整。如输入尺寸5x5,取stride=2,kernel_size=2,则默认情况下输出尺寸为2x2,ceil_mode为True时输出尺寸为3x3。
平均池化层:
Pytorch的平均池化层也有三个,即nn.AvgPool1d()、nn.AvgPool2d()、nn.AvgPool2d()。这里也只单独学习最最常用的nn.AvgPool2d(),其他的都类似或者相同。
CLASS torch.nn.AvgPool2d(kernel_size: Union[int, Tuple[int, int]],
stride: Union[int, Tuple[int, int], None] = None,
padding: Union[int, Tuple[int, int]] = 0,
ceil_mode: bool = False,
count_include_pad: bool = True,
divisor_override: bool = None)
#(CSDN意疏原创笔记:https://blog.csdn.net/sinat_35907936/article/details/107833112)
count_include_pad: 计算均值时是否把padding的像素值算在内。
divisor_override: 除法因子更改,如果设置了该值,则在求均值时不再除以kernel覆盖的像素个数,而是除以该值。
池化层使用
代码:transform_inverse()函数定义见此文,池化过程不改变通道数。
import torch
from PIL import Image
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision.transforms as transforms
from tools.transform_inverse import transform_inverse
MaxPool_layer = nn.MaxPool2d((2, 2), 2)
AvgPool_layer = nn.AvgPool2d((2, 2), 2)
# 4个元素,除法因子应该为4,此处改为8,输出会黯淡一倍
AvgPool_layer1 = nn.AvgPool2d((2, 2), 2, divisor_override=8)
pil_img = Image.open('data/lenna.jpg').convert('RGB')
img = transforms.ToTensor()(pil_img)
print(img.size())
c = img.size()[0]
h = img.size()[1]
w = img.size()[2]
img = torch.reshape(img, [1, c, h, w])
MaxPool_out = MaxPool_layer(img)
AvgPool_out = AvgPool_layer(img)
AvgPool_out1 = AvgPool_layer1(img)
MaxPool_out = torch.squeeze(MaxPool_out)
AvgPool_out = torch.squeeze(AvgPool_out)
AvgPool_out1 = torch.squeeze(AvgPool_out1)
print(MaxPool_out.size())
MaxPool_pil = transform_inverse(MaxPool_out, None)
AvgPool_pil = transform_inverse(AvgPool_out, None)
AvgPool_pil1 = transform_inverse(AvgPool_out1, None)
plt.figure(0)
ax = plt.subplot(2, 2, 1)
ax.set_title('input img')
ax.imshow(pil_img)
ax = plt.subplot(2, 2, 2)
ax.set_title('MaxPool_out img')
ax.imshow(MaxPool_pil)
ax = plt.subplot(2, 2, 3)
ax.set_title('Avgpool_out img')
ax.imshow(AvgPool_pil)
ax = plt.subplot(2, 2, 4)
ax.set_title('AvgPool_out with divisor_override=8')
ax.imshow(AvgPool_pil1)
plt.show()
#(CSDN意疏原创笔记:https://blog.csdn.net/sinat_35907936/article/details/107833112)
结果:用kernel_size = 2,stride = 2的池化层,可以将输入尺寸缩减一半,但是大部分的信息都没有丢失,如图3所示。所以池化操作可以减少冗余,进而减小后续的计算量。平均池化,可以通过修改除法因子来修改池化结果,除法因子是根据实际情况的需要的修改的,一般保持默认值。
torch.Size([3, 440, 440])
torch.Size([3, 220, 220])

反池化与反池化层
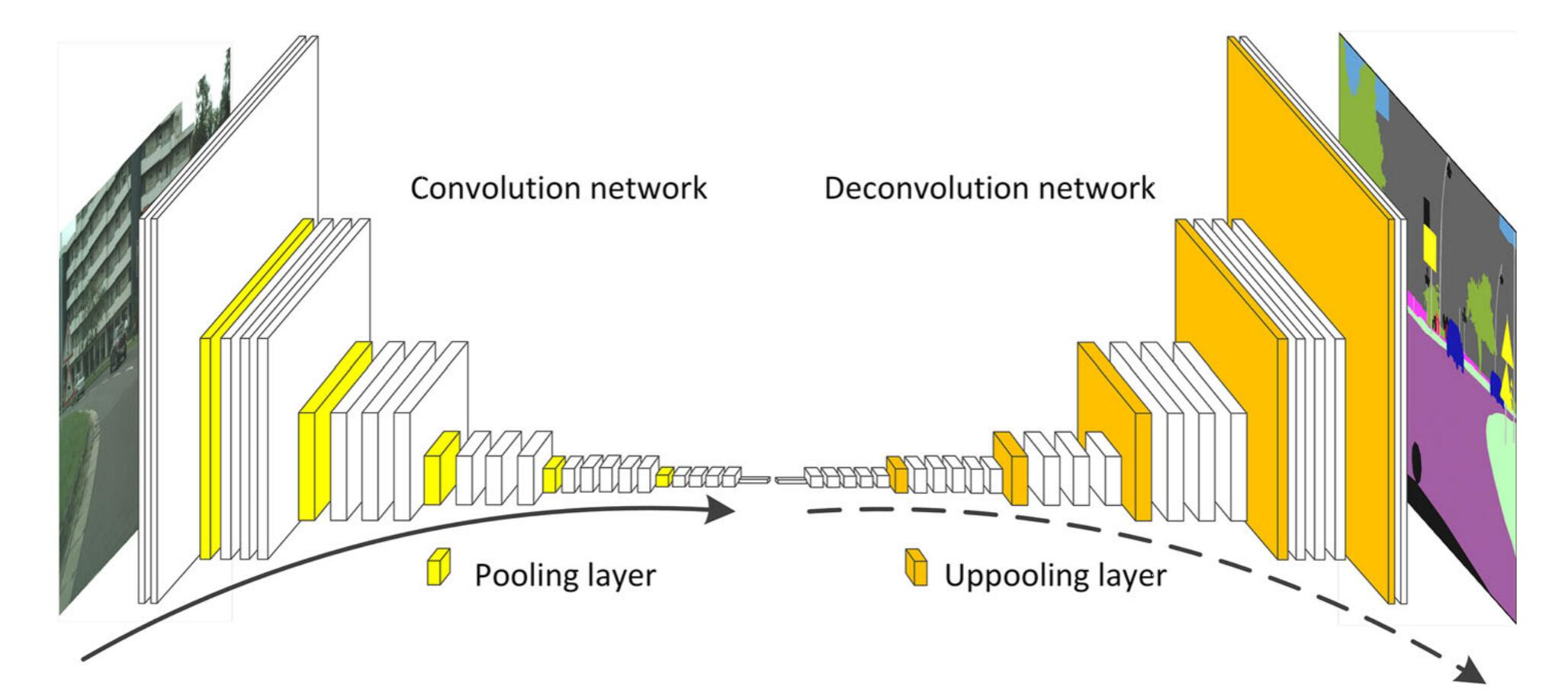
反池化是一种上采样技术,常用在图像分割任务中。如图4,就是反池化在经典的编码-解码图像分割网络中,与转置卷积共同作用,进行上采样的图示,图源。
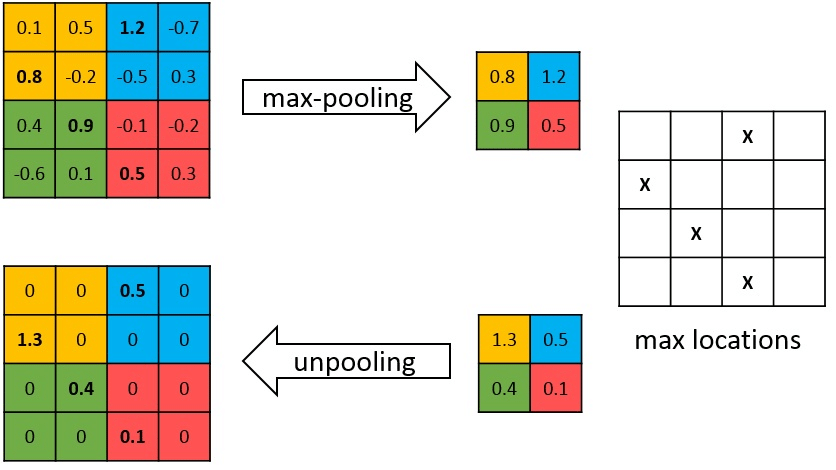
最大池化的反池化。在进行最大池化时,记录下输入的最大值所在位置的索引。在进行反池化时,将输入值根据其所在位置分别放到索引指示的地方,其他位置补零,流程如图5所示,图源。可以看出,两者是一个对称的过程,即池化输入尺寸等于反池化输出尺寸,池化输出尺寸等于反池化输入尺寸,正是应为这样,索引才能对应上。
CLASS torch.nn.MaxUnpool2d(kernel_size: Union[int, Tuple[int, int]],
stride: Union[int, Tuple[int, int], None] = None,
padding: Union[int, Tuple[int, int]] = 0)
stride: 笔者觉得官方文档的解释有问题,以下是笔者理解:输入的一个元素在输出中对应区域的宽高,如stride=2,则表示MaxUnpool2d输入的一个元素,在输出中对应2*2的一个区域。一般取stride=kernel_size。
padding: 笔者觉得官方文档的解释有问题,以下是笔者理解:输入计算尺寸被缩减的值。如输入尺寸是3*3,若padding=1,则表示输入计算尺寸被缩减到(3-1)*(3-1),即2*2,若此时stride=2,则可得输出尺寸是4*4。因为并且索引必须与输入同尺寸,即3*3,所以最后输出就是4*4的张量中有9个点有值,其他均为零。如下代码所示。
代码:
import torch
import torch.nn as nn
MaxUnpool_layer = nn.MaxUnpool2d((2, 2), 2, padding=0)
MaxUnpool_layer1 = nn.MaxUnpool2d((2, 2), 2, padding=1)
In = torch.randn(1, 1, 3, 3)
print(In)
idx = torch.tensor([[0, 5, 3],
[8, 6, 11],
[12, 13, 14]]) # 4*4的张量被拉成一维张量后的序号
print(idx)
idx = torch.reshape(idx, [1, 1, 3, 3])
MaxunPool_out = MaxUnpool_layer(In, indices=idx)
MaxunPool_out1 = MaxUnpool_layer1(In, indices=idx)
print(MaxunPool_out)
print(MaxunPool_out1)
结果:
# input
tensor([[[[ 2.0394, -0.0362, 0.0612],
[-0.3057, -0.3779, 0.2984],
[-0.4500, 1.2419, 0.1124]]]])
# indices
tensor([[ 0, 5, 3],
[ 8, 6, 11],
[12, 13, 14]])
# padding=0,输出6*6的张量
tensor([[[[ 2.0394, 0.0000, 0.0000, 0.0612, 0.0000, -0.0362],
[-0.3779, 0.0000, -0.3057, 0.0000, 0.0000, 0.2984],
[-0.4500, 1.2419, 0.1124, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]]]])
# padding=1,输出4*4的张量
tensor([[[[ 2.0394, 0.0000, 0.0000, 0.0612],
[ 0.0000, -0.0362, -0.3779, 0.0000],
[-0.3057, 0.0000, 0.0000, 0.2984],
[-0.4500, 1.2419, 0.1124, 0.0000]]]])
MaxPool与MaxUnPool配合使用,此时MaxUnPool不要用Padding,否则会报如下错误:RuntimeError: Found an invalid max index。
MaxPool_out, idx1 = MaxPool_layer(In)
MaxunPool_out = MaxUnpool_layer(MaxPool_out, indices=idx1)
其他层
很多非线性激活函数在这篇笔记中已经梳理,此处不赘述。
参考
https://yjjo.tistory.com/8 ↩︎