卷积神经网络自2012年,到2023年经历了翻天覆地的变化。最早的卷积神经网络由卷积层、池化层和全连接层所构成。其中卷积层用于提取图像的特征,池化层削减特征数量,全连接层用于对特征进行非线性组合并预测类别。然而在transformer横行的年代,池化层几乎要在神经网络中消失了。趁着池化层还能在少部分主流模型中看到,记录一下各种池化层。本博文一共介绍了7种简单的池化层,此外还介绍了一下卷积神经网络的基本结构。
1、卷积神经网络的主要结构
1.1 卷积层
卷积层最早是作用于RGB格式的2D图像(即 W , H , C i n W,H,C_{in} W,H,Cin格式的数据),其输出数据也为 W , H , C o u t W,H,C_{out} W,H,Cout格式,后来在其它领域被扩展到 W , H , C , D W,H,C,D W,H,C,D格式的数据,也就是3D数据。其中 C i n C_{in} Cin是指输入卷积层的通道数, C o u t C_{out} Cout是指输出卷积层的通道数。卷积核的运算过程与图像滤波时的过程最初是一模一样的(这使得卷积运算具有局部连接和参数共享的特性),其有kernel_size的参数设置(通常只能为奇数),后来又被补充了一些其它的概念。如卷积核滑动的步长(图像滤波步长默认为1),同时算法工程师们还考虑到图像经过卷积运算后size会变小(WxH的图像在经过滤波后,size会变化(W-kernel_size+1)x(H-kernel_size+1))。故而,又对卷积运算提出了padding的概念[padding=smae,即自动填充;padding=valid即不填充],即对原始图像进行填充,使运算后的图像与原始图像保持同样的大小。卷积层还有一个特点是,多视角。卷积核的kernel数 C i n ∗ C o u t C_{in}*C_{out} Cin∗Cout,每一个 C o u t C_{out} Cout【对应着 C i n C_{in} Cin个卷积核】都是卷积层观察数据【提取特征】的一个视角。
1.2 池化层
池化层在当时被认为是卷积神经网络中不可缺少的一部分,其提供了卷积神经网络强壮的鲁棒性(平移不变性、旋转不变性、尺度不变性|特征降维,防止过拟合|实现非线性|扩大下一层卷积层的感受野)。池化层的运算与图像下采样过程类似,通过该操作后可以减少网络层中特征的size,从而减少特征与后续全连接网络层中的参数量。平移|旋转不变性是指图像进行平移|旋转后识别结果任然不变,这依赖平移|旋转后提取的特征不发生变化,池化层能在一定程度上保证特征不变。具体深入可以参考,https://zhuanlan.zhihu.com/p/382569419 ,其提到在图像分类中最需要的是平移不变性;在目标检测中最需要的是平移相等性【即目标平移,预测出的boxes也相应平移】。并在实验中指明,当输出存在细微旋转平移时,池化操作能近似达到平移不变性的效果,当平移或旋转太大后则不具备这种效果。
特征降维,通过池化层运算后,网络层输出的特征size减少了很多,这与特征降维效果相同。减少特征数量后,可以在一定程度上抑制过拟合。
实现非线性,这与池化操作的不可逆
自ResNet之后,池化层在分类网络中应用逐渐变少,往往采用stride=2的卷积替代最大值池化层。
1.3 全连接层
全连接层其实也就是多层感知机|BP神经网络。我们可以将卷积神经网络模型分为两部分:卷积基(由池化层和卷积层构成)、全连接层,卷积基被认为是用于提取图像特征的,全连接层被认为是对图像特征进行分类的。在模型模型时,卷积基于全连接层是共同参与训练(前向传播预测与反向传播优化),故此卷积基与全连接层是存在一定的适应关系的,不能自由组合多个模型内的卷积基和全连接层后直接使用(需要重新进行训练,使其相互适应,也就是迁移学习|fine-tuning)。此外,也有人提出用卷积基提取特征,然后训练决策树、随机森林、SVM、极限学习机、贝叶斯方法、KNN等传统方法进行分类。
特征的概念,特征本质上就是一个属性,当其与任务密集相关时就是有效特征,当其与任务无关时就是噪声数据。在深度学习中,通常使用relu或者其变种函数作为激活函数,其会对负值区域进行抑制,而对正值区域进行保留。也就是说,在深度学习中,卷积基输出的值越大,则表明特征响应强度越大。
2、池化层详解
在深度学习中,池化层只是削减特征的一种运算规则,其并没有参数。按其运算规则区分,有平均池化层、最大池化层、全局平均|最大池化层、随机池化层、混合池化、中值池化层、组合池化层等。其中前3个为常见池化操作,后面的比较少见。
除了这7种池化方法外,在极市平台的 https://jishuin.proginn.com/p/763bfbd5c125 中还介绍了幂平均池化(根据幂运算值使用平均|最大池化)、DPP池化(该池化可以放大空间变化并保留重要的图像结构细节)、Local Importance Pooling(局部重要性池化)和Soft Pooling(软池化)等
2.1 平均池化层
参考 https://zhuanlan.zhihu.com/p/77040467
在前向传播过程中,计算图像区域中的均值作为该区域池化后的值;在反向传播过程中,梯度特征分均配到各个位置。根据下图效果,可以看出均值池化与低通滤波存在一定相似度,可以将高频信息进行滤除(模糊掉图像边缘,忽略掉噪声点),尽可能保存纹理信息,其对于以纹理特性分类的数据或许有用。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RLNJY3n3-1687252619299)(2023-06-20-15-43-32.png)]
其反向传播时,示意如下,可以看到其优化目的是使网络层数据尽可能接近平均值(对2x2的输入输入都使用相同梯度值)

平均池化取每个矩形区域中的平均值,可以提取特征图中所有特征的信息进入下一层,而不像最大池化只保留值最大的特征,所以平均池化可以更多保留些图像的背景信息。
在实际应用中,均值池化往往以全局均值池化的形式出现。常见于SE模块以及分类模块中。极少见于作为下采样模块用于分类网络中。
2.2 最大池化层
在前向过程,选择图像区域中的最大值作为该区域池化后的值;在反向过程中,梯度通过前向过程时的最大值反向传播,其他位置的梯度为0。根据下图效果,可以看出平均池化效果与高通滤波存在一定相似度,将低频信息进行滤除(移除细纹理,只保留最大值),对一个2x2的区域只保留最大的值(类似于relu操作)。
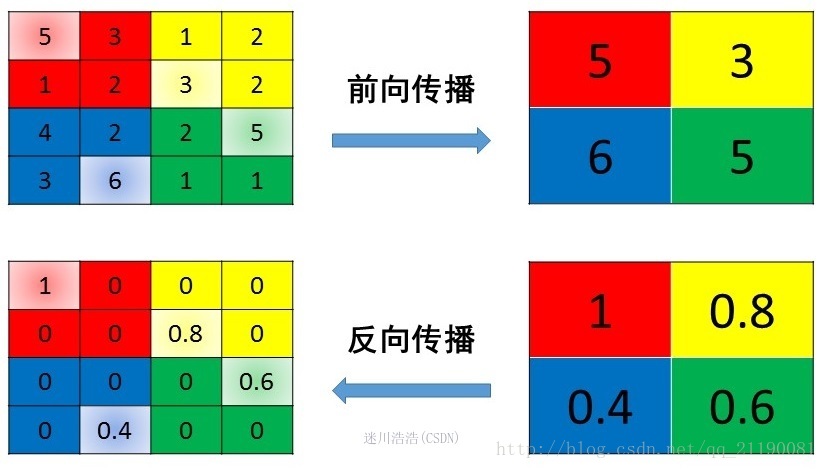
其反向传播时,示意如上图,可以看到只有最大值所对应的区域有梯度值得到优化,而其它区域则没有梯度值。
这种方式摒弃了网络中大量的冗余信息,使得网络更容易被优化。同时这种操作方式也常常丢失了一些特征图中的细节信息,所以最大池化更多保留些图像的边缘信息。
2.3 全局池化层
全局池化层(Global Average Pooling,GAP)是平均|最大池化层的空间泛化,在平均|最大池化层中通常需要设置pool_size(池化区域的大小),而全局全局池化层则是默认为pool_size为WxH,将所有的数据一次性计算出结果(平均|最大池化层需要进行滑窗,滑动一次计算出一个结果)。故此,全局池化层有全局平均池化层和全局最大池化层。

GAP对整个网络在结构上做正则化防止过拟合,直接剔除了全连接层中黑箱的特征,直接赋予了每个channel实际的类别意义。除此之外,使用GAP代替全连接层,可以实现任意图像大小的输入(以往的CNN使用flatten操作将2d数据转成1维,不同的输入size,输出的特征维度不同,故只能固定图像输入尺寸)。GAP对整个特征图求平均值,也可以用来提取全局上下文信息,全局信息作为指导进一步增强网络性能。
全局池化层通常被放置在卷积基于全连接层中间,或者是CBAM(Channel attention)中。
2.4 随机池化层
参考自:https://zhuanlan.zhihu.com/p/77040467
随机池化是ICLR2013的一篇论文Stochastic Pooling所提出的,其结合了平均池化层和最大池化层的优缺点。随机池化的方法非常简单,只需对特征区域元素按照其概率值大小随机选择,元素值大的被选中的概率也大(避免了总是最大值被选中)。
2.5 混合池化
参考自:https://jishuin.proginn.com/p/763bfbd5c125
其受dropout的启发,用随机过程代替了常规的确定性池化操作,在模型训练期间随机采用了最大池化和平均池化方法,并在一定程度上有助于防止网络过拟合现象。混合池化以随机方式改变了池调节的规则,这将在一定程度上解决最大池和平均池所遇到的问题。
混合池化优于传统的最大池化和平均池化方法,并可以解决过拟合问题来提高分类精度。此外该方法所需要的计算开销可忽略不计,而无需任何超参数进行调整,可被广泛运用于CNN。
2.6 中值池化层
参考图像处理中的中值滤波所实现,基本上没有在CNN网络中看到。使用排序后的中值作为输出值,其前向传播与反向传播与最大池化类似。
博主推断其看是能提取图像纹理特征,但很难具备稳定性(中值在网络深层容易受感染),只可用在网络浅层中。在实际使用过程中,不支持将学习率设置的较大,且极难优化。
与最大池化相比,最大值虽然也不是很稳定,但是在整个训练过程中均以数值大小来描述特征对结果的影响力,故在整个体系下其还是具备稳定性的。
2.7 组合池化层
组合池化则同时利用最大值池化与均值池化两种的优势而引申的一种池化策略,其与混合池化的区别在于确定性(组合池化是确定的使用两个池化方式,混合池化是不确定的使用两个池化方式)。常见组合策略有两种:Cat与Add。其代码描述如下:
def add_avgmax_pool2d(x, output_size=1):
x_avg = F.adaptive_avg_pool2d(x, output_size)
x_max = F.adaptive_max_pool2d(x, output_size)
return 0.5 * (x_avg + x_max)
def cat_avgmax_pool2d(x, output_size=1):
x_avg = F.adaptive_avg_pool2d(x, output_size)
x_max = F.adaptive_max_pool2d(x, output_size)
return torch.cat([x_avg, x_max], 1)
3、总结
自从2021年Transformer被引入到视觉模型后,卷积神经网络基本上要末路了,虽然此后也有ConvNeXt、SegNeXt成功挑战过Transformer的地位,但也无力挽回卷积神经网络的大势已去。
ConvNeXt使用了一些列的训练技巧(AdamW 优化器、Mixup、Cutmix、RandAugment、Random Erasing等数据增强技)和随机深度和标签平滑等正则化方案,也不过是勉强将 ResNet-50 模型的性能从 76.1% 提高到了 78.8%。而,Transformer并不需要使用如此复杂的增强策略,仅需要不断扩充训练集即可。整个模型没有池化层做特征降维
SegNeXt号称是在语义分割上使用卷积模型超过了Transformer模型,实则是使用了Transformer模型的中patch embeding,并用MLP层替换了multi head self-attention,其与卷积神经网络的关系并不大。整个模型没有池化层
在这些先进的模型结构中,再也不会使用池化层来提取图像特征(特征降维),以后得卷积神经网络通用结果或许会被重新定义。