池化层在两个卷积层之间,可以有效的缩小矩阵的尺寸(也可以减小矩阵深度,但实践中一般不会这样使用),co。池从而减少最后全连接层中的参数。
池化层既可以加快计算速度也可以防止过度拟合问题的作用。
池化层也是通过一个类似过滤器结构完成的,计算方式有两种:
- 最大池化层:采用最大值操作计算的池化层
- 平均池化层:使用平均值操作计算的池化层
池化层的过滤器也需要人工设定过滤器的尺寸、是否使用全0填充以及过滤器移动的步长等设置。
过滤器只影响一个深度上的节点,所以它需要在深度这个维度移动,这一点与卷积层不同,卷积层的过滤器是横跨整个深度的。
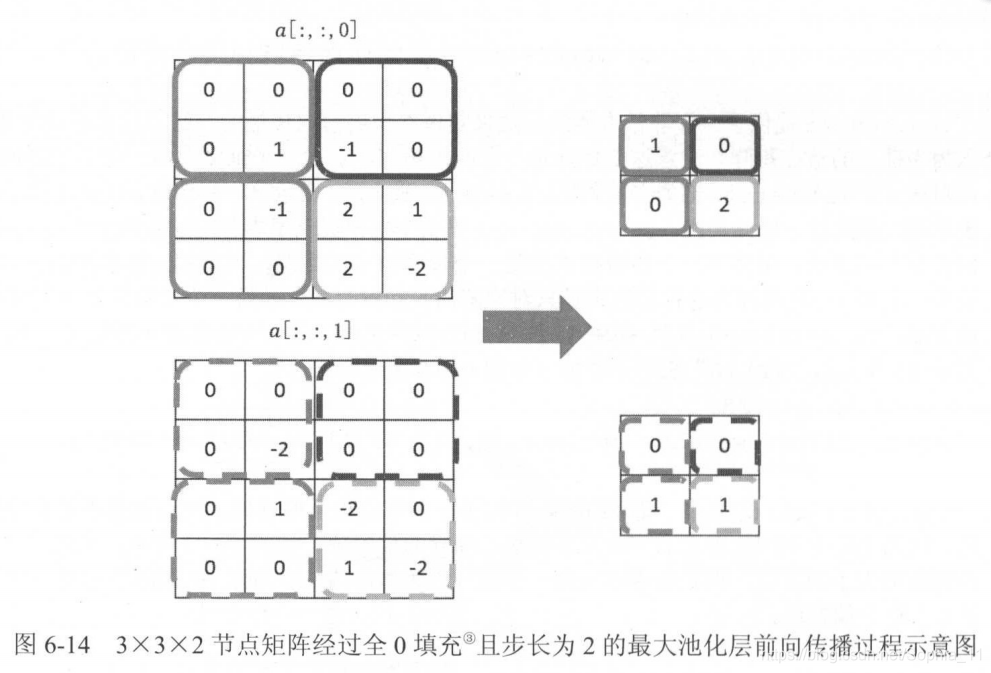
图6-14展示了一个最大池化层的过程:
下边例子是TensorFlow程序实现最大池化层:
# TF.nn.max_pool()实现了最大池化层,参数和tf.nn.conv2d类似
# ksize提供了过滤器的尺寸,strides提供了步长信息,padding提供了是否使用全0填充。
pool = tf.nn.max_pool(actived_conv, ksize = [1, 3, 3, 1], strides = [1, 2, 2, 1], padding = 'SAME')第一个参数输入当前层的节点矩阵,这个矩阵是一个思维矩阵。
第二个参数过滤器(ksize)的尺寸是一个长度为4的一维数组,但是这个数组的第一个和最后一数必须为1。这意味着池化层的过滤器是不可以跨不同输入样例或者节点矩阵深度的。实际应用中,使用最多的过滤器尺寸为[1, 2, 2, 1]或者[1, 3, 3, 1]。
第三个参数strides步长,和tf.nn.conv2d函数中步长意义相同,第一维和最后一维也只能为1。
第四个参数padding表示是否用qu全0填充,'VALID'表示不填充,'SAME'表示用0填充
TensorFlow还提供了tf.nn.avg_pool()来实现平均池化层。tf.nn.avg_pool函数的调用格式和tf.nn.max_pool函数是一致的。