目录
如果这篇文章对你有一点小小的帮助,请给个关注,点个赞喔~我会非常开心的~
花书+吴恩达深度学习(十二)卷积神经网络 CNN 之全连接层
花书+吴恩达深度学习(十三)卷积神经网络 CNN 之运算过程(前向传播、反向传播)
花书+吴恩达深度学习(十四)卷积神经网络 CNN 之经典案例(LetNet-5, AlexNet, VGG-16, ResNet, Inception Network)
0. 前言
池化(pooling)使用某一位置的相邻输出的总体统计特征来代替网络在该位置的输出。
因为池化层没有需要学习的参数,所以通常将卷积层和池化层合起来看作神经网络的一层。
池化后,通常图像大小会减小,可以提高统计效率并且减少对于参数的存储需求。
1. 最大池化(max pooling)
max pooling 给出相邻矩形区域内的最大值,如下图所示(图源:吴恩达深度学习):

将原图像分成不同的区域,将每个区域的最大值,作为输出。
在 max pooling 中,因为输出的大小是确定的,所以 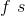
通常使用 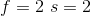
如果是 3D 图像,那么原始图像的通道数和输出图像的通道数是相同的,等于是在每一层的通道执行 max pooling 。
2. 平移不变形
平移的不变性是指当我们对输入进行少量平移的时候,经过池化函数后的大多数输出并不会发生改变。
当我们关心某个特征是否出现而不关心它具体的出现位置时,局部平移不变形很有用。
例如下图所示(图源:深度学习),上方为平移前,下放为平移后:

3. 其他池化函数
一般不常用:
- 平均池化
- L2 范数池化
- 基于距中心像素距离的加权平均池化
4. 卷积和池化作为一种无限强的先验
先验被认为是强或者弱取决于先验中概率密度的集中程度。
弱先验具有较高的熵值,例如方差很大的高斯分布。这样的先验允许数据对于参数的改变具有或多或少的自由性。
强先验具有较低的熵值,例如方差很小的高斯分布。这样的先验在决定参数最终取值时起着更加积极的作用。
我们可以把卷积的使用当作是对网络中一层的参数引入了一个无限强的先验概率分布。这个先验说明了该层应该学得的函数只包含局部连接关系并且对平移具有等变性。类似的,使用池化也是一个无限强的先验:每一个单元都具有对少量平移的不变性。
如果一项任务依赖于保存精确的空间信息,那么在所有的特征上使用池化将会增大训练误差。
如果这篇文章对你有一点小小的帮助,请给个关注,点个赞喔~我会非常开心的~