1 深层卷积神经网络概述
1.1 深层卷积神经网络模型结构图
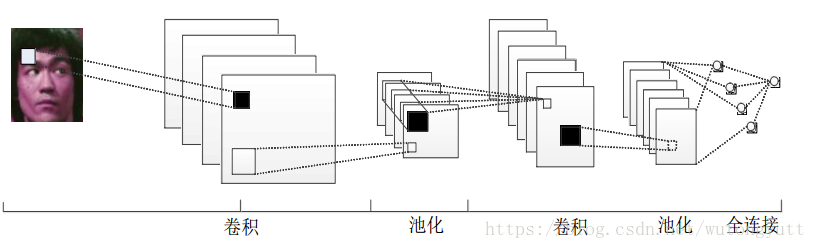
1.1.1 深层卷积神经网络的正向结构构成剖析
- 输入层,将每个像素作为一个特征节点输入网络。
- 卷积层:由多个滤波器组合而成。
- 池化层:将卷积结果降维,对卷积后的特征图进行降维处理,得到更为显著的特征,池化层会对特征图中的数据作最大值/均值处理,在保留特征图原有的特征的基础上,减少后续运算量。
- 全局平均池化层:对生成的特征图取全局平均值,该层可以用全连接网络代替。
- 输出层:网络需要将数据分成几类,该层就有几个输出节点,每个输出节点代表属于当前样本的该类型的概率。
1.2 卷积神经网络的反向传播的步骤
(1)将误差传到前面一层,对卷积操作的反向求导时、需要先将生成的特征图做一次padding,再与转置后的卷积核做一次卷积操作,即得到输入端的误美,丛而实现了误差的反向传递。
(2)根据当前的误差对应的学习参数表达式来算出其需要更新的差值,与全连接网络中的反向求导是一样的,仍然是使用链式求县法则,找到使误差最小化的横度,再配合学习率算出更新的差值。
2 池化操作
2.1 池化操作的概述
2.1.1 池化操作的作用
主要目的降维,使得保持原有的特征基础上最大限度的降低数组大小。
2.1.2 池化与卷积对比
池化:只关心滤波器的尺寸,主要将滤波器映射区内的像素点取平均值或者最大值。
卷积:对应位置上的像素点的乘积。
2.2 池化操作的分类
2.2.1 均值池化
在图片上的对应出滤波器大小的区域,对于其所有像素点取均值,对背景信息更敏感。
2.2.2 最大池化
在图片上的对应出滤波器大小的区域,对于其所有像素点取最大值,对纹理特征更敏感。
2.2 池化函数接口
2.2.1 平均池化函数
nn.AvgPool2d——二维平均池化操作 https://blog.csdn.net/qq_50001789/article/details/120537858
https://blog.csdn.net/qq_50001789/article/details/120537858
torch.nn.AvgPool2d(kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True, divisor_override=None)- kernel_size:池化核的尺寸大小
- stride:窗口的移动步幅,默认与kernel_size大小一致
- padding:在两侧的零填充宽度大小
- ceil_mode:设为True时,在计算输出形状的过程中采用向上取整的操作,否则,采用向下取整
- count_include_pad:布尔类型,当为True时,将在平均池化计算中包括零填充,否则,不包括零填充
- divisor_override:如果被指定,则除数会被代替成divisor_override。换句话说,如果不指定该变量,则平均池化的计算过程其实是在一个池化核内,将元素相加再除以池化核的大小,也就是divisor_override默认为池化核的高×宽;如果该变量被指定,则池化过程为将池化核内元素相加再除以divisor_override。
2.2.2 最大池化函数
class torch.nn.MaxPool1d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)- kernel_size(int or tuple) - max pooling的窗口大小
- stride(int or tuple, optional) - max pooling的窗口移动的步长。默认值是kernel_size
- padding(int or tuple, optional) - 输入的每一条边补充0的层数
- dilation(int or tuple, optional) – 一个控制窗口中元素步幅的参数
- return_indices - 如果等于True,会返回输出最大值的序号,对于上采样操作会有帮助
- ceil_mode - 如果等于True,计算输出信号大小的时候,会使用向上取整,代替默认的向下取整的操作
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)- kernel_size(int or tuple) - max pooling的窗口大小
- stride(int or tuple, optional) - max pooling的窗口移动的步长。默认值是kernel_size
- padding(int or tuple, optional) - 输入的每一条边补充0的层数
- dilation(int or tuple, optional) – 一个控制窗口中元素步幅的参数
- return_indices - 如果等于True,会返回输出最大值的序号,对于上采样操作会有帮助
- ceil_mode - 如果等于True,计算输出信号大小的时候,会使用向上取整,代替默认的向下取整的操作
2.3 池化函数的实战
2.3.1 定义输入变量 --- pool2d.py(第1部分)
import torch
### 1.1 定义输入变量
img = torch.tensor([
[[0.0,0.0,0.0,0.0],[1.0,1.0,1.0,1.0],[2.0,2.0,2.0,2.0],[3.0,3.0,3.0,3.0]],
[[4.0,4.0,4.0,4.0],[5.0,5.0,5.0,5.0],[6.0,6.0,6.0,6.0],[7.0,7.0,7.0,7.0]]
]).reshape([1,2,4,4]) # 定义张量,模拟输入图像
print(img) # 输出结果
print(img[0][0]) # 输出第1通道的内容# 输出:
# tensor([[0, 0, 0, 0],
# [1, 1, 1, 1],
# [2, 2, 2, 2],
# [3, 3, 3, 3]])
print(img[0][1]) # 输出第2通道的内容
# 输出:
# tensor([[4, 4, 4, 4],
# [5, 5, 5, 5],
# [6, 6, 6, 6],
# [7, 7, 7, 7]])
2.3.2 定义池化操作并计算 --- pool2d.py(第2部分)
### 定义池化操作
pooling = torch.nn.functional.max_pool2d(img,kernel_size=2)
print("pooling :",pooling) # 输出最大池化结果(池化区域为2,步长为2),
pooling1 = torch.nn.functional.max_pool2d(img,kernel_size=2,stride=1) # 不补0
print("pooling1 :",pooling1) # 不补0,输出最大池化结果(池化区域为2X2,步长为1),生成3X3的矩阵
pooling2 = torch.nn.functional.avg_pool2d(img,kernel_size=2,stride=1,padding=1)# 先执行补0,再进行池化
print("pooling2 :",pooling2) # 先执行补0,输出平均池化结果(池化区域为4X4,步长为1),生成3X3的矩阵
# 全局池化操作,使用一个与原来输入相同尺寸的池化区域来进行池化操作,一般在最后一层用于图像表达
pooling3 = torch.nn.functional.avg_pool2d(img,kernel_size=4)
print("pooling3 :",pooling3) # 输出平均池化结果(池化区域为4,步长为4)
# 对于输入的张量计算两次均值,可得平均池化结果
m1 = img.mean(3)
print("第1次均值结果",m1)
print("第2次均值结果",m1.mean(2))
### 对于输入数据进行两次平均值操作时,可以看到在输入数据进行两次平均值计算的结果与pooling3的数值是一直的,即为等价pooling : tensor([[[[1., 1.],
[3., 3.]],[[5., 5.],
[7., 7.]]]])
pooling1 : tensor([[[[1., 1., 1.],
[2., 2., 2.],
[3., 3., 3.]],[[5., 5., 5.],
[6., 6., 6.],
[7., 7., 7.]]]])
pooling2 : tensor([[[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.2500, 0.5000, 0.5000, 0.5000, 0.2500],
[0.7500, 1.5000, 1.5000, 1.5000, 0.7500],
[1.2500, 2.5000, 2.5000, 2.5000, 1.2500],
[0.7500, 1.5000, 1.5000, 1.5000, 0.7500]],[[1.0000, 2.0000, 2.0000, 2.0000, 1.0000],
[2.2500, 4.5000, 4.5000, 4.5000, 2.2500],
[2.7500, 5.5000, 5.5000, 5.5000, 2.7500],
[3.2500, 6.5000, 6.5000, 6.5000, 3.2500],
[1.7500, 3.5000, 3.5000, 3.5000, 1.7500]]]])
pooling3 : tensor([[[[1.5000]], [[5.5000]]]])
第1次均值结果 tensor([[[0., 1., 2., 3.],
[4., 5., 6., 7.]]])
第2次均值结果 tensor([[1.5000, 5.5000]])
2.3.3 代码总览 --- pool2d.py
import torch
### 1.1 定义输入变量
img = torch.tensor([
[[0.0,0.0,0.0,0.0],[1.0,1.0,1.0,1.0],[2.0,2.0,2.0,2.0],[3.0,3.0,3.0,3.0]],
[[4.0,4.0,4.0,4.0],[5.0,5.0,5.0,5.0],[6.0,6.0,6.0,6.0],[7.0,7.0,7.0,7.0]]
]).reshape([1,2,4,4]) # 定义张量,模拟输入图像
print(img) # 输出结果
print(img[0][0]) # 输出第1通道的内容
# 输出:
# tensor([[0, 0, 0, 0],
# [1, 1, 1, 1],
# [2, 2, 2, 2],
# [3, 3, 3, 3]])
print(img[0][1]) # 输出第2通道的内容
# 输出:
# tensor([[4, 4, 4, 4],
# [5, 5, 5, 5],
# [6, 6, 6, 6],
# [7, 7, 7, 7]])
### 定义池化操作
pooling = torch.nn.functional.max_pool2d(img,kernel_size=2)
print("pooling :",pooling) # 输出最大池化结果(池化区域为2,步长为2),
pooling1 = torch.nn.functional.max_pool2d(img,kernel_size=2,stride=1) # 不补0
print("pooling1 :",pooling1) # 不补0,输出最大池化结果(池化区域为2X2,步长为1),生成3X3的矩阵
pooling2 = torch.nn.functional.avg_pool2d(img,kernel_size=2,stride=1,padding=1)# 先执行补0,再进行池化
print("pooling2 :",pooling2) # 先执行补0,输出平均池化结果(池化区域为4X4,步长为1),生成3X3的矩阵
# 全局池化操作,使用一个与原来输入相同尺寸的池化区域来进行池化操作,一般在最后一层用于图像表达
pooling3 = torch.nn.functional.avg_pool2d(img,kernel_size=4)
print("pooling3 :",pooling3) # 输出平均池化结果(池化区域为4,步长为4)
# 对于输入的张量计算两次均值,可得平均池化结果
m1 = img.mean(3)
print("第1次均值结果",m1)
print("第2次均值结果",m1.mean(2))
### 对于输入数据进行两次平均值操作时,可以看到在输入数据进行两次平均值计算的结果与pooling3的数值是一直的,即为等价