池化层
卷积层对位置太敏感了,可能一点点变化就会导致输出的变化,这时候就需要池化层了,池化层的主要作用就是缓解卷积层对位置的敏感性

二维最大池化
这里有一个窗口,来滑动,每次我们将窗口中最大的值给拿出来
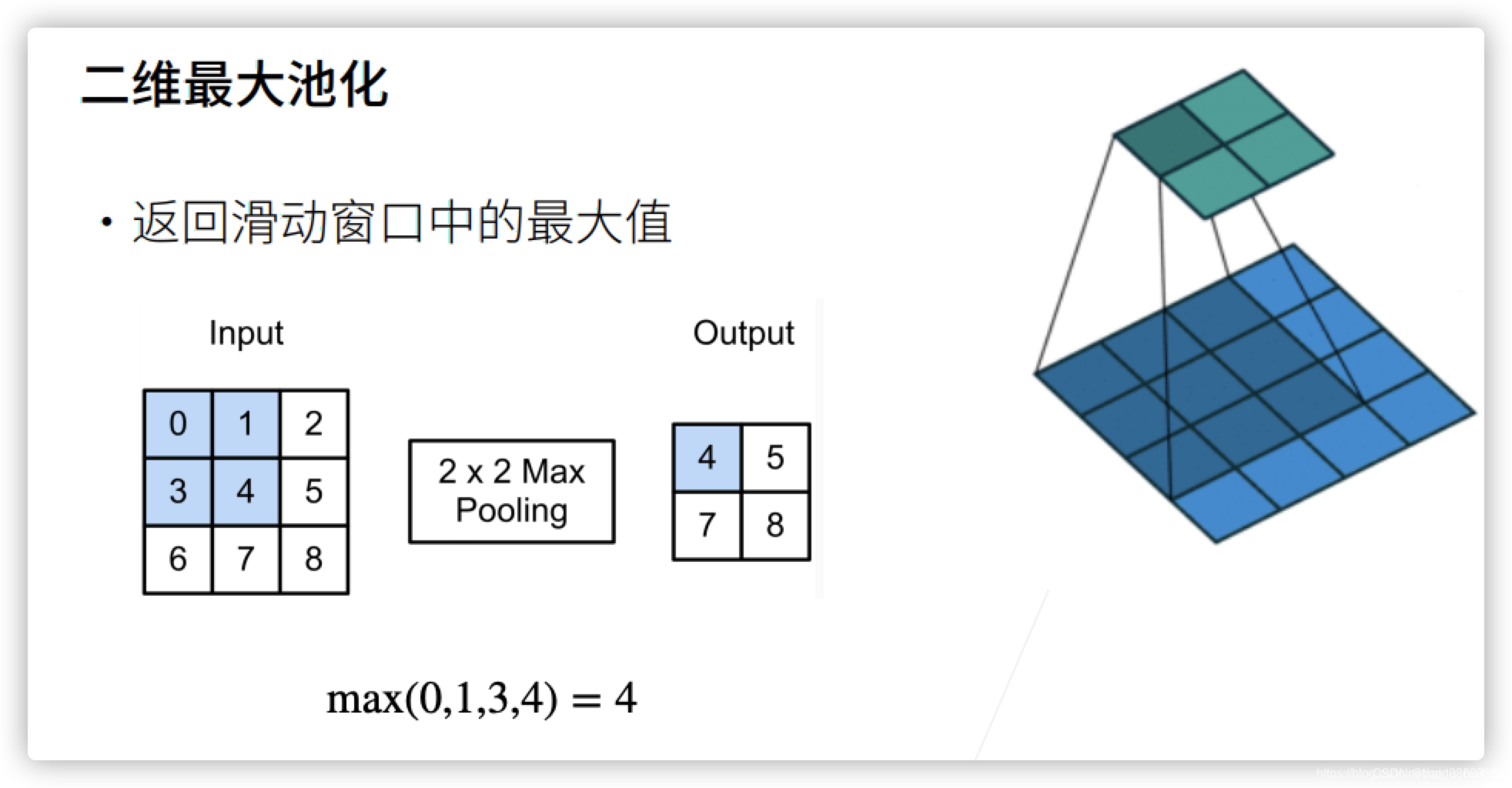
还是上面的例子,这里的最大池化窗口为2*2

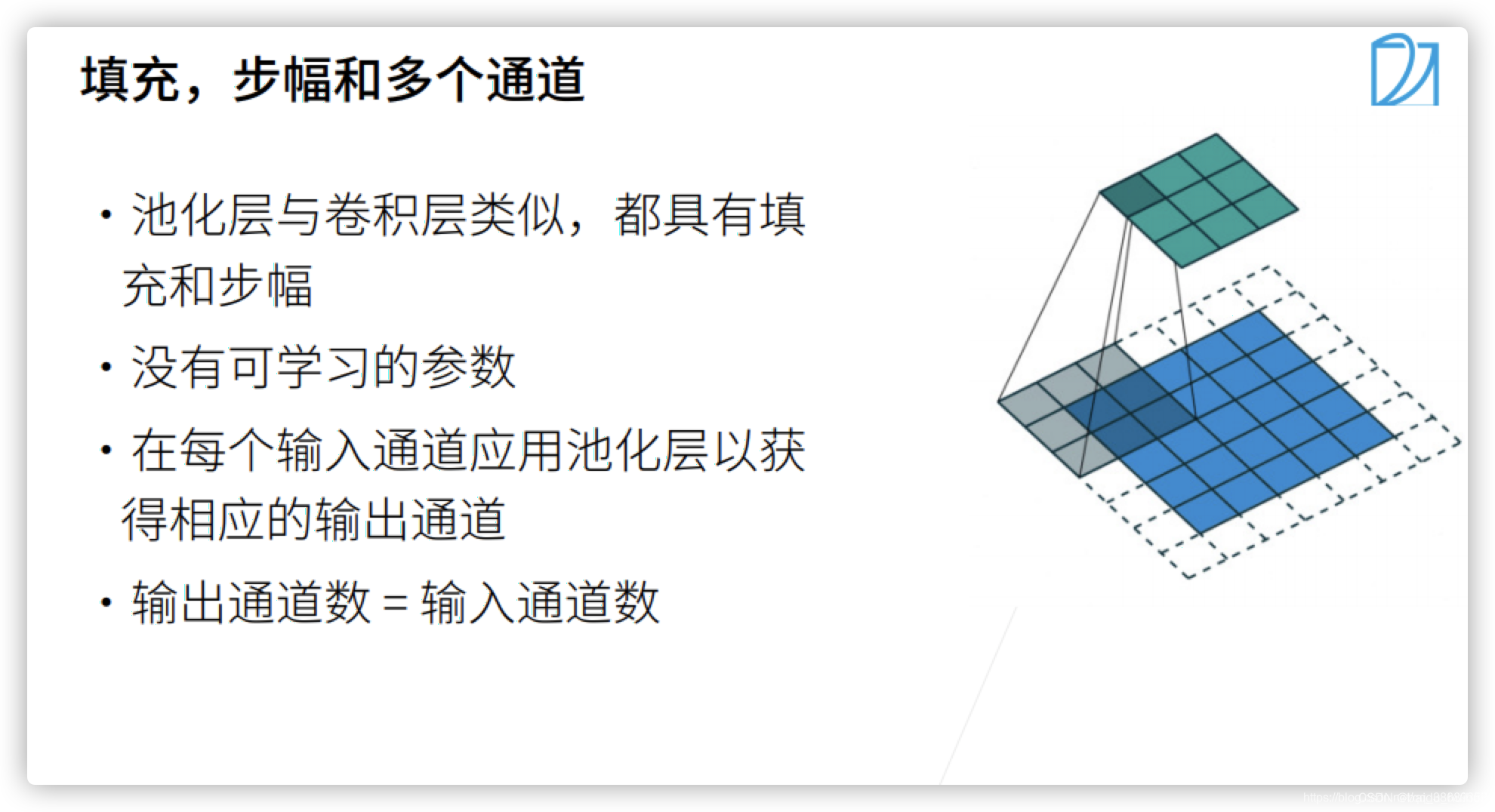
填充、步幅和多个通道
这里基本与卷积层类似,与卷积层不同的是,池化层不需要学习任何的参数
平均池化层
与最大池化层不同的地方在于将最大操作子变为平均,最大池化层是将每个窗口中最强的信号输出,平均池化层就是取每个窗口中的平均效果

总结

实现池化层
import torch
from torch import nn
from d2l import torch as d2l
# 实现池化层的正向传播,这里没有padding,没有stride
def pool2d(X, pool_size, mode="max"):
p_h, p_w = pool_size # 这里我们拿到池化窗口的高和宽
Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1)) # 这里我们先把输出的形状给构造好
# 遍历输入然后赋值
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max': # 这里做最大池化
Y[i, j] = X[i:i + p_h, j:j + p_w].max()
elif mode == 'avg': # 这里做平均池化
Y[i, j] = X[i:i + p_h, j:j + p_w].mean()
return Y
# 验证二维最大池化层的输出
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
pool2d(X, (2, 2))
tensor([[4., 5.],
[7., 8.]])
#验证平均池化层的输出
pool2d(X, (2, 2), 'avg')
tensor([[2., 3.],
[5., 6.]])
# 填充和步幅
X = torch.arange(16, dtype=torch.float32).reshape((1, 1, 4, 4)) # 这里我们创建一个4*4的矩阵,通道为1,批量大小为1
X
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]]]])
# PyTorch中的步幅与池化层窗口的大小相同
pool2d = nn.MaxPool2d(3) # 这里3的意思就是一个3*3的窗口,这里没有指定步幅和填充
pool2d(X)
/Users/tiger/opt/anaconda3/envs/d2l-zh/lib/python3.8/site-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at ../c10/core/TensorImpl.h:1156.)
return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)
tensor([[[[10.]]]])
# 手动设定填充和步幅
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
pool2d(X)
tensor([[[[ 5., 7.],
[13., 15.]]]])
# 设定一个任意大小的矩形池化窗口,并分别设定填充和步幅的高度和宽度
pool2d = nn.MaxPool2d((2, 3), padding=(1, 1), stride=(2, 3)) # 这里padding是对称的,这里的stride和窗口大小一样不重叠
pool2d(X)
tensor([[[[ 1., 3.],
[ 9., 11.],
[13., 15.]]]])
# 池化层在每个输入通道上单独运算
X = torch.cat((X, X + 1), 1) # 这里cat是拼接两个张量,1的意思是按照维度1来拼接
pool2d = nn.MaxPool2d(3, padding=1, stride=2) # padding参数是有一个行和宽的,假设我们指定一个数的话,他的padding就是等于那个值,如果用一个元组的话前面的就是对于行的padding,后面的就是对于列的padding
pool2d(X)
tensor([[[[ 5., 7.],
[13., 15.]],
[[ 6., 8.],
[14., 16.]]]])
文章知识点与官方知识档案匹配,可进一步学习相关知识
Python入门技能树>首页>概览384043 人正在系统学习中