- 这是《算法笔记》的读书记录
- 本文参考自4.3节
文章目录
一. 分治
- 分治(分而治之):将原问题划分成若干个规模较小而结构与原问题相同或相似的子问题,然后分别解决这些子问题,最后合并子问题的解
- 分治的三个步骤
- 分解:将原问题分解为若干结构相同或相似的子问题。分解的子问题应当是相互独立没有交叉的,否则不应使用分治解决
- 解决:递归求解所有子问题。如果子问题的规模小到可以直接解决,就直接解决它(这往往是递归退出位置)
- 合并:将子问题的解合并为原问题的解
- 分治是一种算法思想,递归是一种编程技巧手段。分治可以用递归方法实现,也可以用非递归方法实现。
- 用递归实现分治往往比较容易
二. 递归
1. 什么是递归
-
要理解递归,你要先理解递归,直到你能理解为止
-
上面这句描述就是一个递归,递归就在于反复调用自身,每次调用都把问题规模缩小,直到范围小到可以直接求得结果,然后再在返回路上求出问题的解。从这点上看,递归很适合处理分治问题
-
递归的两个关键
- 递归边界:原问题分解为子问题的尽头
- 递归式:把原问题分解为若干子问题的手段
2. 简单实例
(1)递归求阶乘
- 递归式:
n! = n*(n-1)! - 递归边界:
n=0 - 示例代码
#include<iostream> using namespace std; int func(int n) { if(n==0) return 1; return n*func(n-1); } int main() { int n; cin>>n; cout<<func(n)<<endl; return 0; }
(2)求斐波那契数列第n项
- 递归式:
f(n) = f(n-1)+f(n-2) - 递归边界:
n=0 或 n=1 - 示例代码
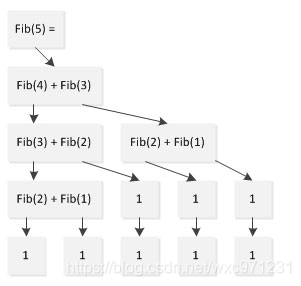
#include<iostream> using namespace std; int func(int n) { if(n==0 || n==1) return 1; return func(n-1)+func(n-2); } int main() { int n; cin>>n; cout<<func(n)<<endl; return 0; } - 分析:递归虽然很简洁,但是效率不高。观察上述递归执行过程如下,可以看出,在计算Fib(5)的过程中,Fib(1)计算了两次、Fib(2)计算了3次,Fib(3)计算了两次,本来只需要5次计算就可以完成的任务却计算了9次。这个问题随着规模的增加会愈发凸显,以至于Fib(1000)已经无法再可接受的时间内算出。同时,递归还需要不断进行函数调用,会在内存中不断发生调用栈处理,这降低了效率,同时增大了空间复杂度。为了解决这个问题,一个常用的方法是把递归转化为递推,从而避免冗余计算和返回函数调用。
(3)全排列
- 递归式:
输出n的全排列 = (在第1位填入1~n) + (在第2位填入1~n) + ... + (在第N位填入1~n) - 递归边界:
填写到第n+1位了,说明前n位已经填满 - 示例代码
#include<iostream> using namespace std; int res[110]; //记录当前生成的全排列 int flag[110] = { 0}; //记录整数x是否已在排列中 int n; //排列位数 void func(int index) { // 退出条件:n个数已经填完 if(index == n+1) { //输出生成的全排列 for(int i=1;i<=n;i++) cout<<res[i]; cout<<endl; } //依次把1~n填入第index位 for(int i=1;i<=n;i++) { if(!flag[i]) { res[index] = i; //在第index位填入i flag[i] = 1; //标记i已在全排列中 func(index+1); //递归排第index+1位 flag[i] = 0; //准备在第index位填入i+1,去除i的标记 } } } int main() { cin>>n; func(1); return 0; } - 有一个经典的八皇后问题,和全排列有很大的关系,可以参考这里:数据结构(6)栈和队列->栈的应用之八皇后问题
三. 回溯
- 回溯法常常也使用递归手段实现,因此这里先简单说一下,具体的等到深度优先搜索时再写
- 回溯法是深度优先搜索的一个优化,它是在问题的解空间树中,按深度优先策略,从根结点出发搜索解空间树。算法搜索至解空间树的任意一点时,先判断该结点是否包含问题的解。如果肯定不包含(剪枝过程),则跳过对该结点为根的子树的搜索,逐层向其祖先结点回溯;否则,进入该子树,继续按深度优先策略搜索
- 在上面用全排列解八皇后问题的例子中,我们生成了所有全排列,一一测试是否符合条件,这种把所有可能性枚举出来的做法称作暴力法。相对的,如果在递归的某层,由于一些事实导致已经不需要往任何一个子问题递归,就可以直接返回上一层,从而对搜索树进行一些剪枝以提高效率,这就是回溯法了
四. 更多递归相关题目
1. 逆波兰表达式
- 题目链接:NOI 1696:逆波兰表达式
- 总时间限制: 1000ms 内存限制: 65536kB
- 描述
逆波兰表达式是一种把运算符前置的算术表达式,例如普通的表达式2 + 3的逆波兰表示法为+ 2 3。逆波兰表达式的优点是运算符之间不必有优先级关系,也不必用括号改变运算次序,例如(2 + 3) * 4的逆波兰表示法为* + 2 3 4。本题求解逆波兰表达式的值,其中运算符包括+ - * /四个。
- 输入
输入为一行,其中运算符和运算数之间都用空格分隔,运算数是浮点数。
- 输出
输出为一行,表达式的值。可直接用printf("%f\n", v)输出表达式的值v。
- 样例输入
* + 11.0 12.0 + 24.0 35.0 - 样例输出
1357.000000
- 提示
可使用
atof(str)把字符串转换为一个double类型的浮点数。atof定义在math.h中。此题可使用函数递归调用的方法求解。
(1)常规非递归写法
- 这个题描述的实际上应该是 “波兰表达式”,所以我先用波兰表达式的一般求解方法来做一下,这个做法用到了栈。具体可以参考 数据结构(5)栈和队列->栈的应用之表达式求值 这篇文章中的前缀表达式解法
#include<iostream>
#include<cmath>
#include<string>
#include<vector>
#include<algorithm>
using namespace std;
vector<string> data; //存分解后的输入内容
vector<double> cal; //计算辅助栈
int main()
{
// 获取原始输入
string raw;
getline(cin,raw);
// 分解输入到容器中
int pos;
while(1)
{
pos = raw.find(" ");
data.push_back(raw.substr(0,pos));
if(pos == string::npos)
break;
raw = raw.substr(pos+1);
}
// 翻转一下(方便遍历)
reverse(data.begin(),data.end());
// 利用计算栈求解
double t1,t2;
for(auto i:data)
{
if(i!="+" && i!="-" && i!="*" && i!="/")
cal.push_back(stof(i));
else
{
t1 = cal.back();
cal.pop_back();
t2 = cal.back();
cal.pop_back();
if(i == "+")
cal.push_back(t1+t2);
else if(i=="-")
cal.push_back(t1-t2);
else if(i=="*")
cal.push_back(t1*t2);
else
cal.push_back(t1/t2);
}
}
printf("%f\n", cal[0]);
return 0;
}
(2)递归写法
- 认清前缀表达式的本质,整个前缀表达式就是很多
算符 操作数1 操作数2的嵌套组合,这样就把原问题分解为子问题 - 递归边界:找到了
算符 操作数1 操作数2这个结构中的最基本元素,即一个操作数
#include<stdio.h>
#include<math.h>
#include<stdlib.h>
double exp()
{
char a[10];
scanf("%s",a);
switch(a[0])
{
case '+': return exp()+exp();
case '-': return exp()-exp();
case '*': return exp()*exp();
case '/': return exp()/exp();
default: return atof(a);
}
}
int main()
{
double ans;
ans=exp();
printf("%f",ans);
return 0;
}
2. 字母全排列
-
题目链接:NOI 1750:全排列
-
总时间限制: 1000ms 内存限制: 65536kB
-
描述
给定一个由不同的小写字母组成的字符串,输出这个字符串的所有全排列。 我们假设对于小写字母有’a’ < ‘b’ < … < ‘y’ < ‘z’,而且给定的字符串中的字母已经按照从小到大的顺序排列。
-
输入添加链接描述
输入只有一行,是一个由不同的小写字母组成的字符串,已知字符串的长度在1到6之间。
-
输出
输出这个字符串的所有排列方式,每行一个排列。要求字母序比较小的排列在前面。字母序如下定义:
已知S = s1s2…sk , T = t1t2…tk,则S < T 等价于,存在p (1 <= p <= k),使得
s1 = t1, s2 = t2, …, sp - 1 = tp - 1, sp < tp成立。 -
样例输入
abc
-
样例输出
abc
acb
bac
bca
cab
cba -
这个题和上面简单实例的第三个本质完全一样,就是套了个字母的皮。正好这个可以用我上午写的哈希散列来套壳子,参考【算法笔记】4.2 散列(哈希)
-
代码
#include<iostream> #include<string> using namespace std; char hashMap[10]; //哈希表,实现整数到字母的映射 int res[110]; //记录当前生成的全排列 int flag[110] = { 0}; //记录整数x是否已在排列中 int n; //排列位数 void func(int index) { // 退出条件:n个数已经填完 if(index == n+1) { //输出生成的全排列 for(int i=1;i<=n;i++) cout<<hashMap[res[i]]; cout<<endl; } //依次把1~n填入第index位 for(int i=1;i<=n;i++) { if(!flag[i]) { res[index] = i; //在第index位填入i flag[i] = 1; //标记i已在全排列中 func(index+1); //递归排第index+1位 flag[i] = 0; //准备在第index位填入i+1,去除i的标记 } } } int main() { string raw; cin>>raw; n = raw.length(); for(int i=1;i<=raw.length();i++) hashMap[i] = raw[i-1]; func(1); return 0; }
3. 数楼梯
-
题目链接:洛谷 P1255 数楼梯
-
题目描述
楼梯有 NN 阶,上楼可以一步上一阶,也可以一步上二阶。
编一个程序,计算共有多少种不同的走法。 -
输入格式
一个数字,楼梯数。
-
输出格式
输出走的方式总数。
-
输入输出样例
输入
4
输出
5 -
说明/提示
对于 60% 的数据,N ≤ 50;
对于 100% 的数据,N ≤ 5000。
(1) 正向递归
-
递归式:
上n级台阶的方法 = 上n-1级台阶的方法(这次上1级) + 上n-2级台阶的方法(这次上2级) -
递归边界:
已经上到第n级了 -
示例代码
#include <iostream> #include <stdio.h> #include <string> #include <algorithm> using namespace std; int N; long long ans=0; // 统计从第depth级开始爬楼梯的走法 void fun(int depth) { // 退出边界 if(depth>N) return; if(depth==N) { ans++; return; } fun(depth+1); // 这次上1级,统计从第depth+1级开始爬楼梯的走法 fun(depth+2); // 这次上2级,统计从第depth+2级开始爬楼梯的走法 } int main() { scanf("%d",&N); if(N<=0) cout<<0<<endl; else { fun(0); //从第0级开始爬楼梯 cout<<ans; } return 0; }
(2) 反向递归
- 递归式:
离目标还有n级台阶时的走法 = 离目标还有n-1级台阶的方法(这次上1级) + 离目标还有n-2级台阶的方法(这次上2级) - 递归边界:
离目标只差1级或2级了 - 示例代码
#include <iostream> #include <stdio.h> #include <string> #include <algorithm> using namespace std; int N; long long ans=0; // 统计离目标还有depth级时的走法 void fun2(int depth) { // 退出边界 if(depth<1) // 非法退出边界 return; if(depth==1) // 差1级就到了 { ans++; return; } if(depth==2) // 差2级就到了,可以一次跨2级,也可以分两步走 { ans+=2; return; } fun2(depth-1); // 统计离目标还有depth-1级时的走法 (这次走1级) fun2(depth-2); // 统计离目标还有depth-2级时的走法 (这次走2级) } int main() { scanf("%d",&N); fun2(N); // 初始时离目标还有N级 cout<<ans<<endl; return 0; }
(3)递推写法
-
上面两种递归写法都很简洁,但是不管哪种,都会超时 !! 问题就在于上面斐波那契那个示例中分析的,冗余计算太多,函数调用太多。为了解决这个问题,我们可以把递归转递推来做。
-
分析这个题,递归公式本质上也是
f(n) = f(n-1)+f(n-2),和斐波那契数列相同,稍微修改一下递推形式的斐波那契数列算法,得出递推解如下#include <iostream> #include <stdio.h> #include <string> #include <algorithm> using namespace std; int fun(int n) { if(n<=0) return 0; if(n==1) return 1; if(n==2) return 2; int x1 = 1; int x2 = 2; int res; for(int i=3;i<=n;i++) { res = x1+x2; x1 = x2; x2 = res; } return res; } int main() { int N; scanf("%d",&N); int ans = fun(i); cout<<ans<<" "; return 0; } -
可惜,这个解法依然只有50分,如果用
long long可以60,这是因为当N很大时可行的走法太多了,超出数据表述范围。要想满分,还需要做高精度加法。如下#include <iostream> #include <stdio.h> #include <string> #include <algorithm> using namespace std; //大数加法 string add(string a,string b) { string res; //短的数补0,方便计算 int t = a.length()-b.length(); if(t>0) b.insert(0,t,'0'); else a.insert(0,-t,'0'); //模拟竖式加法 int ta,tb,tsum,tres,tc=0; for(int i=a.length()-1;i>=0;i--) { ta = a[i]-'0'; tb = b[i]-'0'; tsum = ta+tb+tc; tres = tsum%10; //本位和 tc = tsum/10; //进位 res.insert(0,1,tres+'0'); } if(tc!=0) res.insert(0,1,tc+'0'); //最高位进位 //去除多余前导0 int i=0; while(res[i]=='0') i++; res = res.substr(i) == "" ? "0" : res.substr(i); return res; } string fun(int n) { if(n<=0) return "0"; if(n==1) return "1"; if(n==2) return "2"; string x1 = "1"; string x2 = "2"; string res; for(int i=3;i<=n;i++) { res = add(x1,x2); x1 = x2; x2 = res; } return res; } int main() { int N; scanf("%d",&N); string ans = fun(N); cout<<ans<<" "; return 0; } -
可见,递归也不是万能的