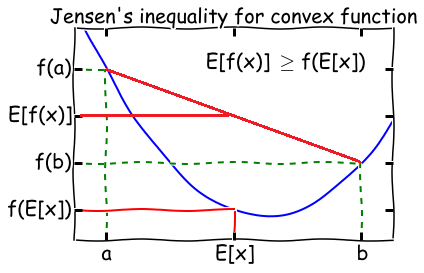
Theorem: Let f be a convex function, and let X be a random variable. Then:
E[f(X)]≥f(E[X])
Moreover, if f is strictly convex, then E[f(X)]=f(E[X]) holds true if and only if X is a constant.
Later in the post we are going to use the following fact from the Jensen’s inequality: Suppose λj≥0 for all j and ∑jλj=1, then
logj∑λjyj≥j∑λjlogyj
where the log function is concave.
Overview of Expectation–Maximization (EM) algorithm
In this post, let Y be a set of observed data, Z a set of unobserved latent data, and θ the unknown parameters.
(After this post, you will be comfortable with the following description about the EM algorithm.)
Expectation–Maximization (EM) algorithm is an iterative method to find (local) maximum likelihood estimation (MLE) of L(θ)=p(Y∣θ), where the model depends on unobserved latent variablesZ.
Algorithm:
Initialize peremeters θ0.
Iterate between steps 2 and 3 until convergence:
an expectation (E) step, which creates a function Q(θ,θi) for the expectation of the log-likelihood logp(Y,Z∣θ) evaluated using the current conditional distribution of Z given Y and the current estimate of the parameters θi, where
A maximization (M) step, which computes parameters maximizing the expected log-likelihood Q(θ,θi) found on the E step and then update parameters to θi+1.
These parameter-estimates are then used to determine the distribution of the latent variables in the next E step. We say it converges if the increase in successive iterations is smaller than some tolerance parameter.
In general, multiple maxima may occur, with no guarantee that the global maximum will be found.
Intuition: Why we need EM algorithm
Sometimes maximizing the likelihood ℓ(θ) explicitly might be difficult since there are some unknown latent variables. In such a setting, the EM algorithm gives an efficient method for maximum likelihood estimation.
Complete Case v.s. Incomplete Case
Complete case
(Y,Z) is observable, and the log likelihood can be written as
We subdivide our task of maximizing ℓ(θ) into two sub-tasks. Note that in both logp(Z∣θ) and logp(Y∣Z,θ), the only unknown parameter is θ. They are just two standard MLE problems which could be easily solved by methods such as gradient descent.
Incomplete case
(Y) is observable, but (Z) is unknown. We need to introduce the marginal distribution of variable Z:
Here we have a summation inside the log, so it’s hard to use optimization methods or take derivatives. This is the case where EM algorithm comes into aid.
EM Algorithm Derivation (Using MLE)
Given the observed data Y, we want to maximize the likelihood ℓ(θ)=p(Y∣θ), and it’s the same as maximizing the log-likelihood logp(Y∣θ). Therefore, from now on we will try to maximize the likelihood
ℓ(θ)=logp(Y∣θ)
by taking the unknown variable Z into account, we rewrite the objective function as
Note that in the last step, the log is outside of the ∑, which is hard to compute and optimize. Check out my previous post to know why we prefer to have log inside of ∑, instead of outside. So later we would find a way to approximate it (Jensen’s inequality).
Suppose we follow the iteration step 2 (E) and 3 (M) repeatedly, and have updated parameters to θi, then the difference between ℓ(θ) and our estimate ℓ(θi) is ℓ(θ)−ℓ(θi). You can think of this difference as the improvement that later estimate of θ tries to achieve. So our next step is to find θi+1 such that it improves the difference the most. That is, to make the difference ℓ(θ)−ℓ(θi) as large as possible. So we want our next estimate θi+1 to be
θi+1=θargmaxℓ(θ)−ℓ(θi)
Note that we know the value of θi, so as ℓ(θi). And
which implies that B(θ,θi) is a lower bound of ℓ(θ) for all i. Therefore our next step is to maximize the lower bound B(θ,θi) and make it as tight as possible. In the M step, we define
(4)→(5) since logP(Z∣Y,θi)⋅p(Y∣θi) does not contain θ.
(6)→(7) we define Q(θ,θi)=∑ZP(Z∣Y,θi)⋅logp(Y,Z∣θ).
since both Y and θi are known, we have the distribution of Z∼p(Z∣Y,θi). Therefore, the only unknown parameter is θ, which means this is now a complete case I mentioned early in the post. So this is now a MLE problem.
summary
θi+1=θargmaxℓ(θ)−ℓ(θi)=θargmaxQ(θ,θi). This implies that maximizing ℓ(θ)−ℓ(θi) is the same as maximizing Q(θ,θi).
Note that Q(θ,θi)=∑ZP(Z∣Y,θi)⋅logp(Y,Z∣θ) is just the expectation of logp(Y,Z∣θ), where Z is drawn from the current conditional distribution P(Z∣Y,θi). Therefore we have Q(θ,θi)=EZ∼p(Z∣Y,θi)[logp(Y,Z∣θ)] That’s why it’s called the Expectation step. In E step, we are actually trying to calculate the expectation of the term logp(Y,Z∣θ), where unknown variable Z follows the current conditional distribution given by Y and θi. Then in the Maximazation step, we are trying to maximize this expectation. That’s why it’s called the M step.
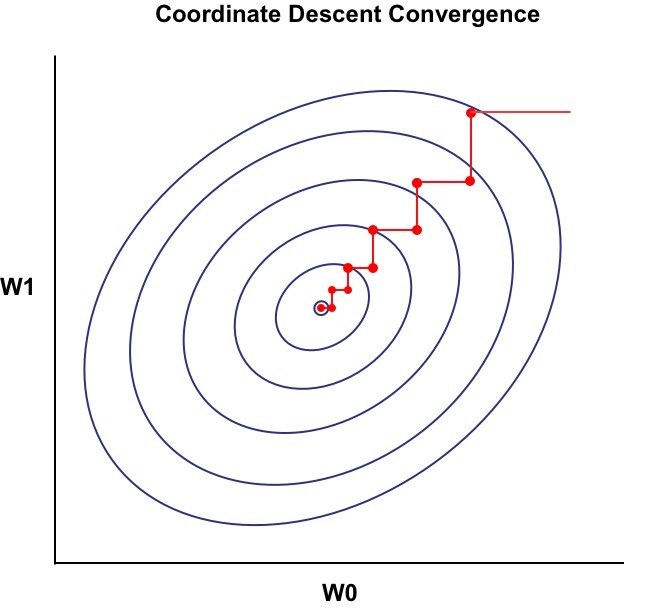
Coordinate Ascent/ descent - view EM from a different prospect
In the Expectation Step, we actually fixed θi, and tried to optimize Q(θ,θi).
In the Maximization step, we actually fixed Q(θ,θi), and tried to optimize θ to get θi+1.
Every time we only optimize one variable and fix the rest. Therefore, from the graph above we see that in every iteration the gradient changes either vertically or horizontally.
To see how to perform the coordinate descent, check out my previous post.
Convergence of EM algorithm
By following the algorithm, we keep updating parameter θi and calculating approximated log-likelihood ℓ(θi). But do we actually keep ℓ(θi) getting closer to l(θ) as we do more iterations? Keep in mind that in MLE our final goal is to maximize ℓ(θ).
Suppose θi and θi+1 are the parameters from two successive iterations of EM. We will now prove that ℓ(θi)≤ℓ(θi+1), which shows EM always monotonically improves the log-likelihood.