0x00 引言
EM算法是什么?什么是E(Epectation)?什么是M(Maximization)?什么又是公式里面出现的Q函数?这些公式都是怎么推导的?Nature抛硬币的那个图怎么就看不懂嘞?为什么看了那么多文章之后还是不懂?公式的符号怎么又不一样呢?谁谁还说有九层塔?Emmm…interesting
下面,让我们走进科学。
0x10 直观理解
现在有一个随机变量数据集
D
D
,假设我们知道这个随机变量
X
X
服从某种分布(一般是高斯正规分布),我们的目的是想知道这个分布的参数
θ
θ
,可是随机变量
X
X
里面包含不可知的参数(也就是隐变量
z
z
)的时候,EM算法是在一边猜隐变量
z
z
一边更新
θ
θ
:
先蒙一下目标参数
θ o l d
θ
o
l
d
E步:利用测算的目标参数
θ o l d
θ
o
l
d
和数据集
D
D
猜隐变量
z
z
的分布
M步:利用上一步猜出来的隐变量
z
z
反思更新目标参数
θ n e w
θ
n
e
w
重复上面两步直到目标参数
θ
θ
收缩为止
再压缩成人话的话,数据集
D
D
是以
z
z
为比例而测出来的
X
X
,先用
θ
θ
蒙一个
z
z
,然后用
z
z
再算一个
θ
θ
,如此反复。
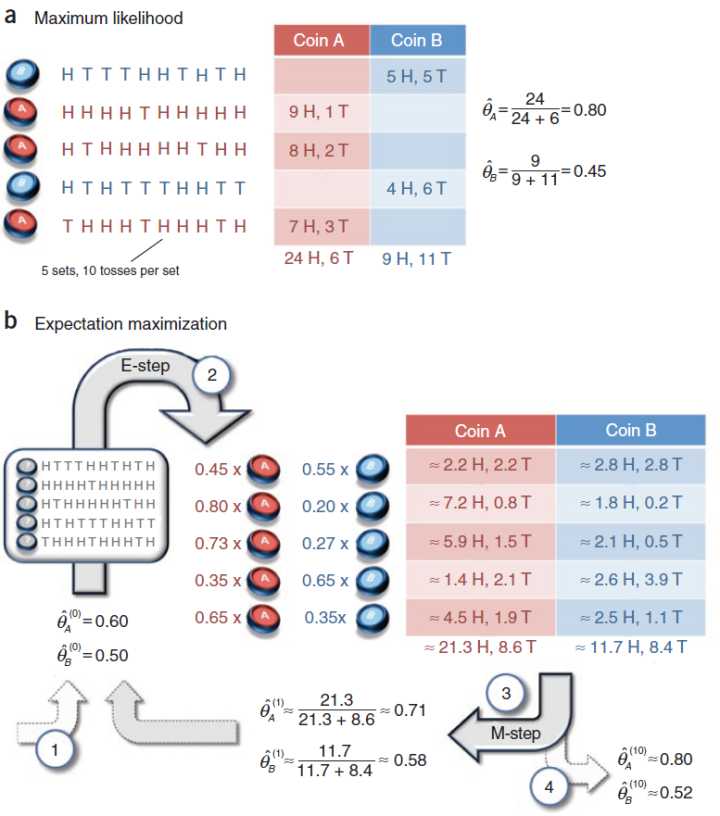
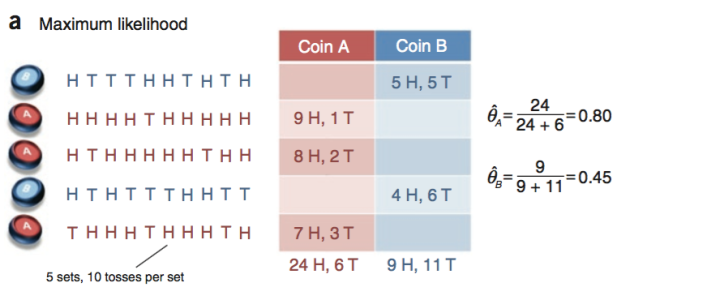
0x20 抛硬币的例子
来源:Do, C. B., & Batzoglou, S. (2008). What is the expectation maximization algorithm? Nature Biotechnology, 26(8), 897–899. https://doi.org/10.1038/nbt1406
上面这篇著名的EM入门论文里面有一张很好的图例,利用抛硬币来说明EM,可是对于某些初学者来讲缺乏解读可能还是有点难理解思路。
下面尝试拆解一下分步骤解读
0x21 问题定义
已知:
实验:
随机抛硬币十次为一组,记录正面朝上(H)和反面朝上(T)的数据
换硬币重复试验
问题:
分别求这两个硬币正面朝上的概率
θ A
θ
A
和
θ B
θ
B
0x22 完全信息 vs 包含隐函数的不完全信息
上图的实验过程中如果记录了当时抛的是A或者B哪种硬币,统计推断的时候知道了每一组是属于哪一种硬币的情况下那当然很好算,这种情况叫完全信息。
假如实验中根本不知道抛的时候究竟是哪一种硬币,或者就不告诉你的话,我们就没办法直接计算两种硬币正面朝上的概率了,这种情况叫不完全信息。
例如上图的数据是和完全信息的情况一样的,区别在于左边的标签是问号,不知道是什么硬币。
这个时候就用到了EM算法。
0x23 完全信息下的求解
每次抛硬币都是独立的,从二项分布的期望公式
E [ X ] = n p
E
[
X
]
=
n
p
可以推导出
p = E [ X ] n = n h e a d n
p
=
E
[
X
]
n
=
n
h
e
a
d
n
。
0x24 不完全信息下的初级EM求解
不完全信息情况呢?我们根本不知道每一组的结果是属于哪种硬币的,没办法用0x24的方法算。这个时候硬币是否属于A的隐变量
z n
z
n
是未知的。
(硬币的情况来说正常用二分法,
z n = { 1 , i f c o i n A 0 , i f c o i n B
z
n
=
{
1
,
i
f
c
o
i
n
A
0
,
i
f
c
o
i
n
B
,不过下面使用
z n
z
n
代表数据重新分割的时候属于A的比例。)
那怎么办?
想一下就发现,一组抛多次,不同硬币的抛出不同结果的概率是相当不同的。比如说:
一个
θ = 0.3
θ
=
0.3
的硬币抛出4H6T的概率是
P ( 4 H 6 T | θ = 0.3 ) = ( 10 4 ) 0.3 4 ( 1 − 0.3 ) 6 = ( 10 4 ) 0.0009529569
P
(
4
H
6
T
|
θ
=
0.3
)
=
(
10
4
)
0.3
4
(
1
−
0.3
)
6
=
(
10
4
)
0.0009529569
而
θ = 0.4
θ
=
0.4
的硬币抛出4H6T的概率是
P ( 4 H 6 T | θ = 0.4 ) = ( 10 4 ) 0.4 4 ( 1 − 0.4 ) 6 = ( 10 4 ) 0.0011943936
P
(
4
H
6
T
|
θ
=
0.4
)
=
(
10
4
)
0.4
4
(
1
−
0.4
)
6
=
(
10
4
)
0.0011943936
也就是说,倒过来说,看到4H6T的结果的时候,这个硬币本身朝上的概率更有可能是
θ = 0.4
θ
=
0.4
而不是
θ = 0.3
θ
=
0.3
。
(注意有些文章里面的概率函数式子的写法用到了分号,
P ( θ ; X )
P
(
θ
;
X
)
,意思这是个以X为输入以
θ
θ
为变量的函数。为了方便,本文不使用;符号。)
所以说,已知
θ A
θ
A
和
θ B
θ
B
的话,我们可以通过观察抛出来的结果来推测原来硬币究竟是属于A还是B的!(这个做法叫做最大似然估计)
可是我们现在不知道
θ A
θ
A
和
θ B
θ
B
怎么办呢?这不是要求解的参数吗?
面对这个蛋生鸡还是鸡生蛋的cul-de-sac(死胡同),我们的做法是:先蒙一个!然后再不停互相更新修改。
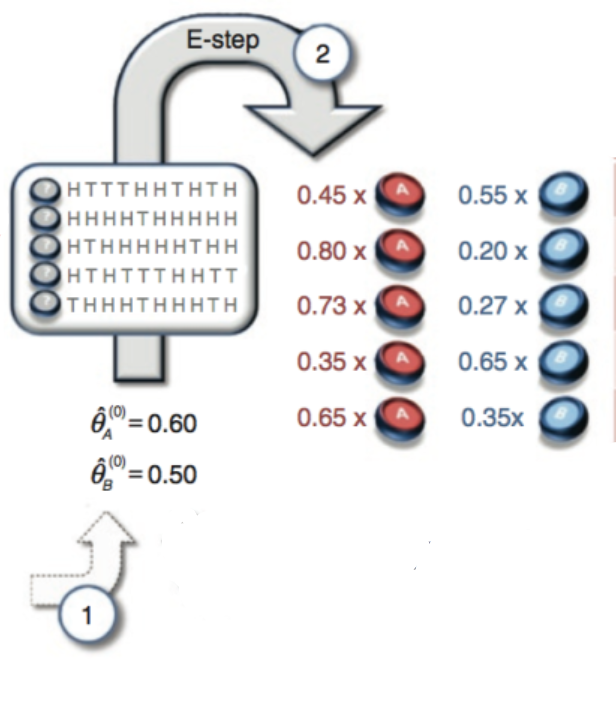
具体步骤
(1)先给
θ A
θ
A
和
θ B
θ
B
随便赋值。
θ ( 0 ) A = 0.60
θ
A
(
0
)
=
0.60
,
θ ( 0 ) B = 0.50
θ
B
(
0
)
=
0.50
。
(2)然后算出
A硬币抛出第一组的似然函数是
P ( 5 H 5 T | θ ( 0 ) A = 0.6 ) = ( 10 5 ) 0.6 5 ( 1 − 0.6 ) 5 = ( 10 5 ) 0.0007962624
P
(
5
H
5
T
|
θ
A
(
0
)
=
0.6
)
=
(
10
5
)
0.6
5
(
1
−
0.6
)
5
=
(
10
5
)
0.0007962624
。
B硬币抛出第一组的似然函数是
P ( 5 H 5 T | θ ( 0 ) B = 0.5 ) = ( 10 5 ) 0.5 5 ( 1 − 0.5 ) 5 = ( 10 5 ) 0.0009765625
P
(
5
H
5
T
|
θ
B
(
0
)
=
0.5
)
=
(
10
5
)
0.5
5
(
1
−
0.5
)
5
=
(
10
5
)
0.0009765625
。
由此可以看到这组比较有可能是属于A。这个例子先按照比例来把第一组数据划分给A和B。
划分给A的比例是
z 1 = P ( 5 H 5 T | θ ( 0 ) A ) P ( 5 H 5 T | θ ( 0 ) A ) + P ( 5 H 5 T | θ ( 0 ) B ) ≈ 0.45
z
1
=
P
(
5
H
5
T
|
θ
A
(
0
)
)
P
(
5
H
5
T
|
θ
A
(
0
)
)
+
P
(
5
H
5
T
|
θ
B
(
0
)
)
≈
0.45
。
同理划分给B的比例是
1 − z 1 = P ( 5 H 5 T | θ ( 0 ) B ) P ( 5 H 5 T | θ ( 0 ) A ) + P ( 5 H 5 T | θ ( 0 ) B ) ≈ 0.55
1
−
z
1
=
P
(
5
H
5
T
|
θ
B
(
0
)
)
P
(
5
H
5
T
|
θ
A
(
0
)
)
+
P
(
5
H
5
T
|
θ
B
(
0
)
)
≈
0.55
。
对其他组也进行推算,得到
z 2 ≈ 0.80
z
2
≈
0.80
,
z 3 ≈ 0.73
z
3
≈
0.73
,
z 4 ≈ 0.35
z
4
≈
0.35
,
z 5 ≈ 0.65
z
5
≈
0.65
。
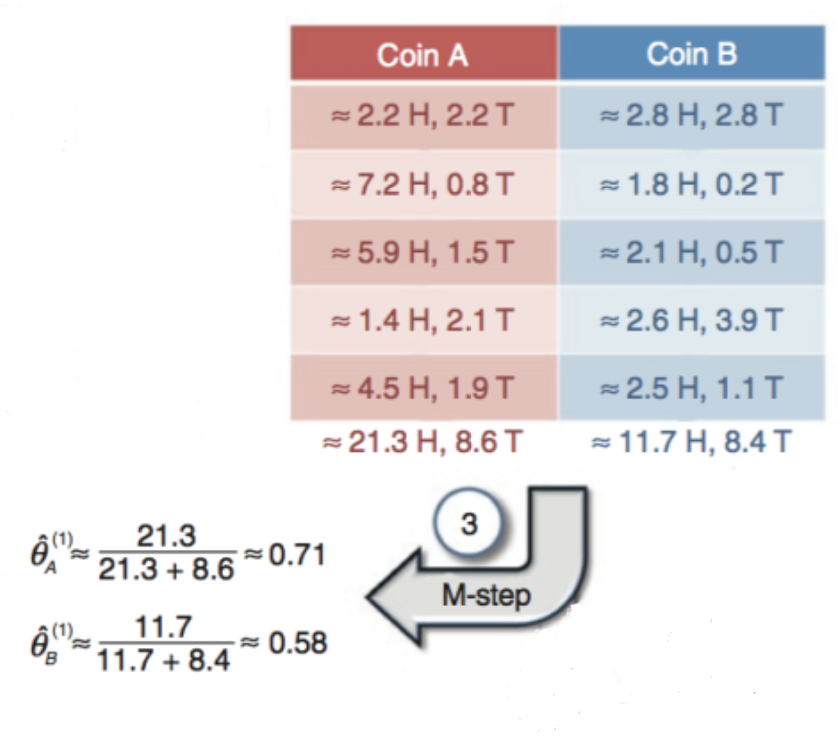
(3)接下来得到了新的划分后的数据,可以更新参数了
对于A来说,一共有21.3次向上8.6次向下,那么A硬币朝上的概率是
θ ̂ ( 1 ) A = 21.3 21.3 + 8.6 ≈ 0.71
θ
^
A
(
1
)
=
21.3
21.3
+
8.6
≈
0.71
。
对于B来说,一共有11.7次向上8.4次向下,那么B硬币朝上的概率是
θ ̂ ( 1 ) B = 11.7 11.7 + 8.4 ≈ 0.58
θ
^
B
(
1
)
=
11.7
11.7
+
8.4
≈
0.58
。
(4)重复步骤(2)和(3),直到收敛,可以算得第十次循环之后
θ ̂ ( 10 ) A ≈ 0.80
θ
^
A
(
10
)
≈
0.80
,
θ ̂ ( 10 ) B ≈ 0.52
θ
^
B
(
10
)
≈
0.52
。
可以看到这个结果也跟之前完全信息算出来的比较接近。
0x30 EM算法的公式推导
0x31 定义
m个互相独立的样本组成的数据集
X = ( x ( 1 ) , x ( 2 ) , . . . x ( m ) )
X
=
(
x
(
1
)
,
x
(
2
)
,
.
.
.
x
(
m
)
)
(这里每个
x ( k )
x
(
k
)
对应硬币例子里面的一组共抛十次的数据,不知道每组属于哪种)
相对应的隐参数
z = ( z ( 1 ) , z ( 2 ) , . . . z ( m ) )
z
=
(
z
(
1
)
,
z
(
2
)
,
.
.
.
z
(
m
)
)
(每组数据属于哪种硬币的标记)
样本本身的模型参数
θ
θ
(硬币例子就是
θ = ( θ A , θ B )
θ
=
(
θ
A
,
θ
B
)
)
对应似然函数为
观察到
x ( k )
x
(
k
)
的似然函数为
P ( x ( k ) | θ )
P
(
x
(
k
)
|
θ
)
(例如硬币例子的
P ( 4 H 6 T | θ = 0.3 )
P
(
4
H
6
T
|
θ
=
0.3
)
)
完全信息情况下的似然函数则是
P ( x ( k ) , z ( k ) | θ )
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
(例如硬币例子的
P ( 4 H 6 T , z = 1 | θ 1 = 0.3 , θ 2 = 0.4 )
P
(
4
H
6
T
,
z
=
1
|
θ
1
=
0.3
,
θ
2
=
0.4
)
。)
0x32 最大似然估计
那么为了求模型参数
θ
θ
,将
θ
θ
看成是参数,求解让各个样本的似然函数的乘积
L ( θ )
L
(
θ
)
最大即可。
也就是
θ = arg max θ L ( θ ) = arg max θ ∏ m k = 1 P ( x ( k ) | θ ) = arg max θ ∑ m k = 1 log P ( x ( k ) | θ )
θ
=
arg
max
θ
L
(
θ
)
=
arg
max
θ
∏
k
=
1
m
P
(
x
(
k
)
|
θ
)
=
arg
max
θ
∑
k
=
1
m
log
P
(
x
(
k
)
|
θ
)
,让
L ( θ )
L
(
θ
)
对
θ
θ
求导为零容易算出
θ
θ
如果有隐函数的话则是
θ , z = arg max θ , z L ( θ , z ) = arg max θ , z ∑ m k = 1 log ∑ z P ( x ( k ) , z ( k ) | θ )
θ
,
z
=
arg
max
θ
,
z
L
(
θ
,
z
)
=
arg
max
θ
,
z
∑
k
=
1
m
log
∑
z
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
,由于包含了
log ∑ z P ( x ( k ) , z ( k ) | θ )
log
∑
z
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
这个时候求导的计算量就很繁杂了
解决思路是利用Jensen不等式
E [ f ( x ) ] ≥ f ( E ( x ) )
E
[
f
(
x
)
]
≥
f
(
E
(
x
)
)
,
将
log ∑ z P ( x ( k ) , z ( k ) | θ )
log
∑
z
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
变成
∑ z log P ( x ( k ) , z ( k ) | θ )
∑
z
log
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
,即是下面的(1)到(2),同时对P乘以了
q ( z ( k ) ) q ( z ( k ) ) = 1
q
(
z
(
k
)
)
q
(
z
(
k
)
)
=
1
。
因此,
∑ k = 1 m log ∑ z P ( x ( k ) , z ( k ) | θ ) = ∑ k = 1 m log ∑ z q ( z ( k ) ) P ( x ( k ) , z ( k ) | θ ) q ( z ( k ) ) ( 1 ) ≥ ∑ k = 1 m ∑ z q ( z ( k ) ) log P ( x ( k ) , z ( k ) | θ ) q ( z ( k ) ) ( 2 ) → ∑ k = 1 m ∑ z q ( z ( k ) | x ( k ) , θ o l d ) log P ( x ( k ) , z ( k ) | θ ) q ( z ( k ) | x ( k ) , θ o l d ) ( 3 ) = ∑ k = 1 m ∑ z q ( z ( k ) | x ( k ) , θ o l d ) log P ( x ( k ) , z ( k ) | θ ) − ∑ k = 1 m ∑ z q ( z ( k ) | x ( k ) , θ o l d ) log q ( z ( k ) | x ( k ) , θ o l d ) ( 4 ) = Q ( θ , θ o l d ) + c o n s t a n t ( 5 )
∑
k
=
1
m
log
∑
z
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
=
∑
k
=
1
m
log
∑
z
q
(
z
(
k
)
)
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
q
(
z
(
k
)
)
(
1
)
≥
∑
k
=
1
m
∑
z
q
(
z
(
k
)
)
log
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
q
(
z
(
k
)
)
(
2
)
→
∑
k
=
1
m
∑
z
q
(
z
(
k
)
|
x
(
k
)
,
θ
o
l
d
)
log
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
q
(
z
(
k
)
|
x
(
k
)
,
θ
o
l
d
)
(
3
)
=
∑
k
=
1
m
∑
z
q
(
z
(
k
)
|
x
(
k
)
,
θ
o
l
d
)
log
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
−
∑
k
=
1
m
∑
z
q
(
z
(
k
)
|
x
(
k
)
,
θ
o
l
d
)
log
q
(
z
(
k
)
|
x
(
k
)
,
θ
o
l
d
)
(
4
)
=
Q
(
θ
,
θ
o
l
d
)
+
c
o
n
s
t
a
n
t
(
5
)
上面出来传说中的Q辅助函数,让Q最大化得出新的
θ
θ
就是所谓的M步。从(2)到(3)步其实是E步。
所以EM算法就是上面推导公式的(3)(4)(5)之间不断循环直到收敛。
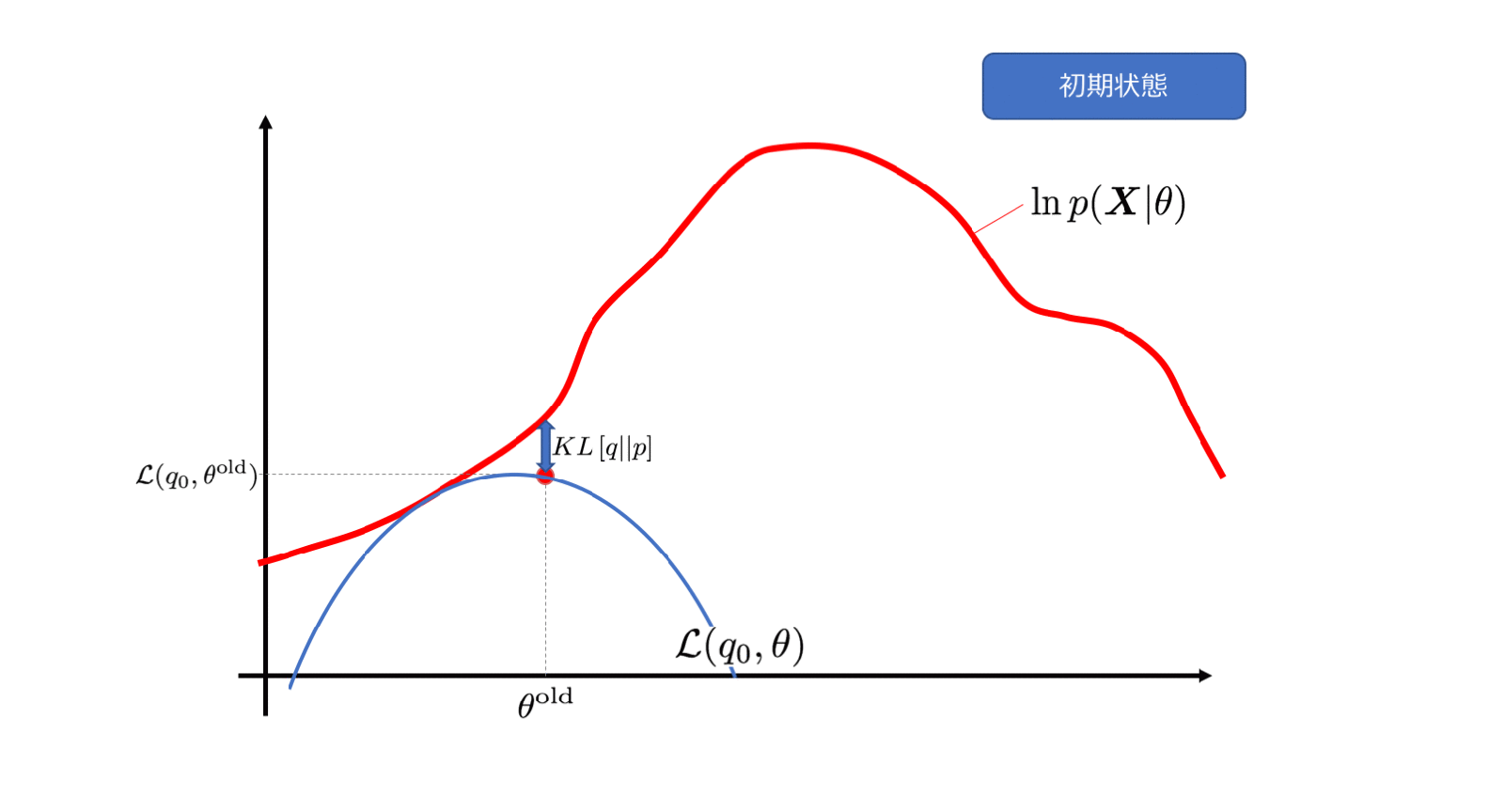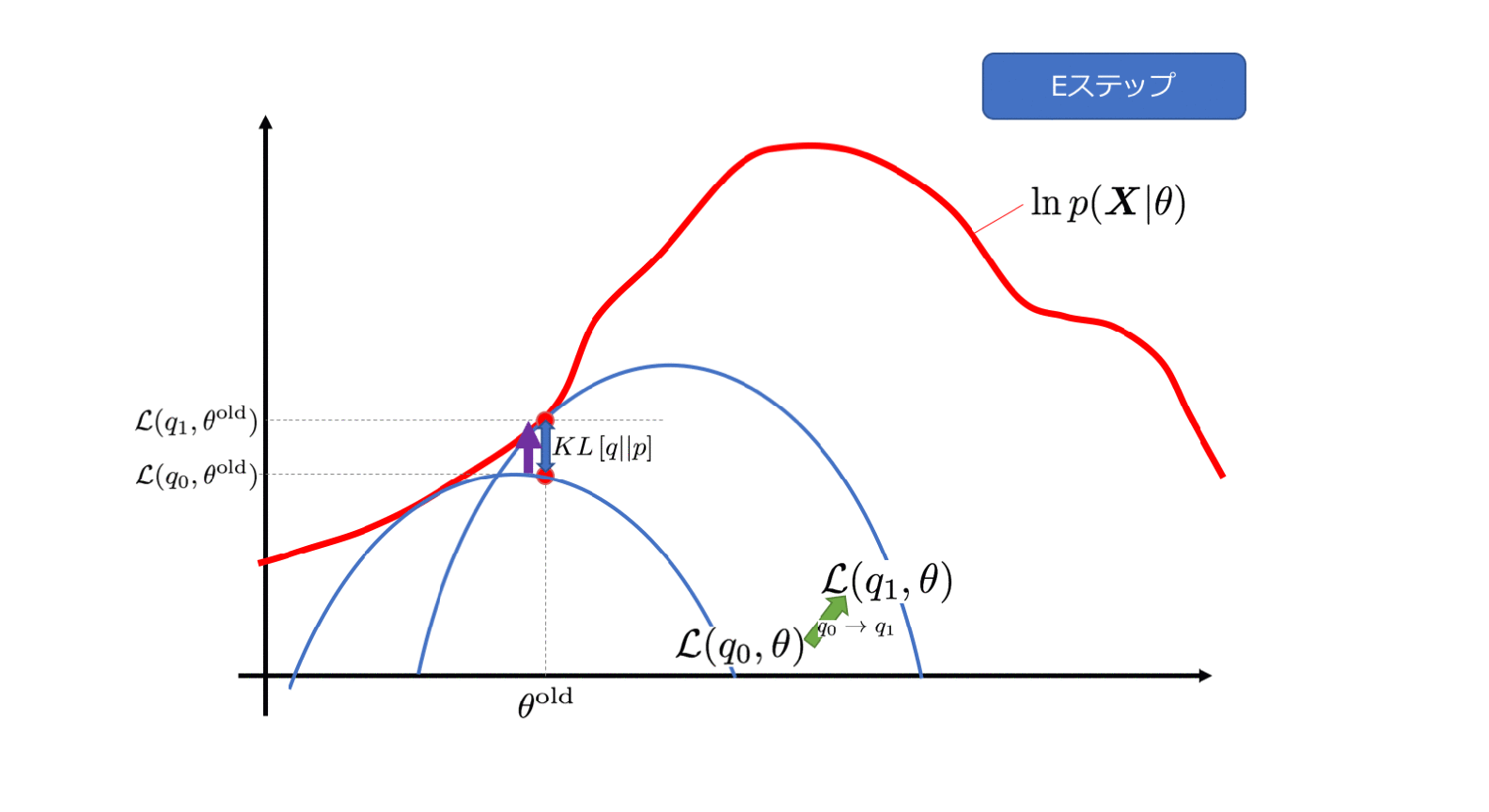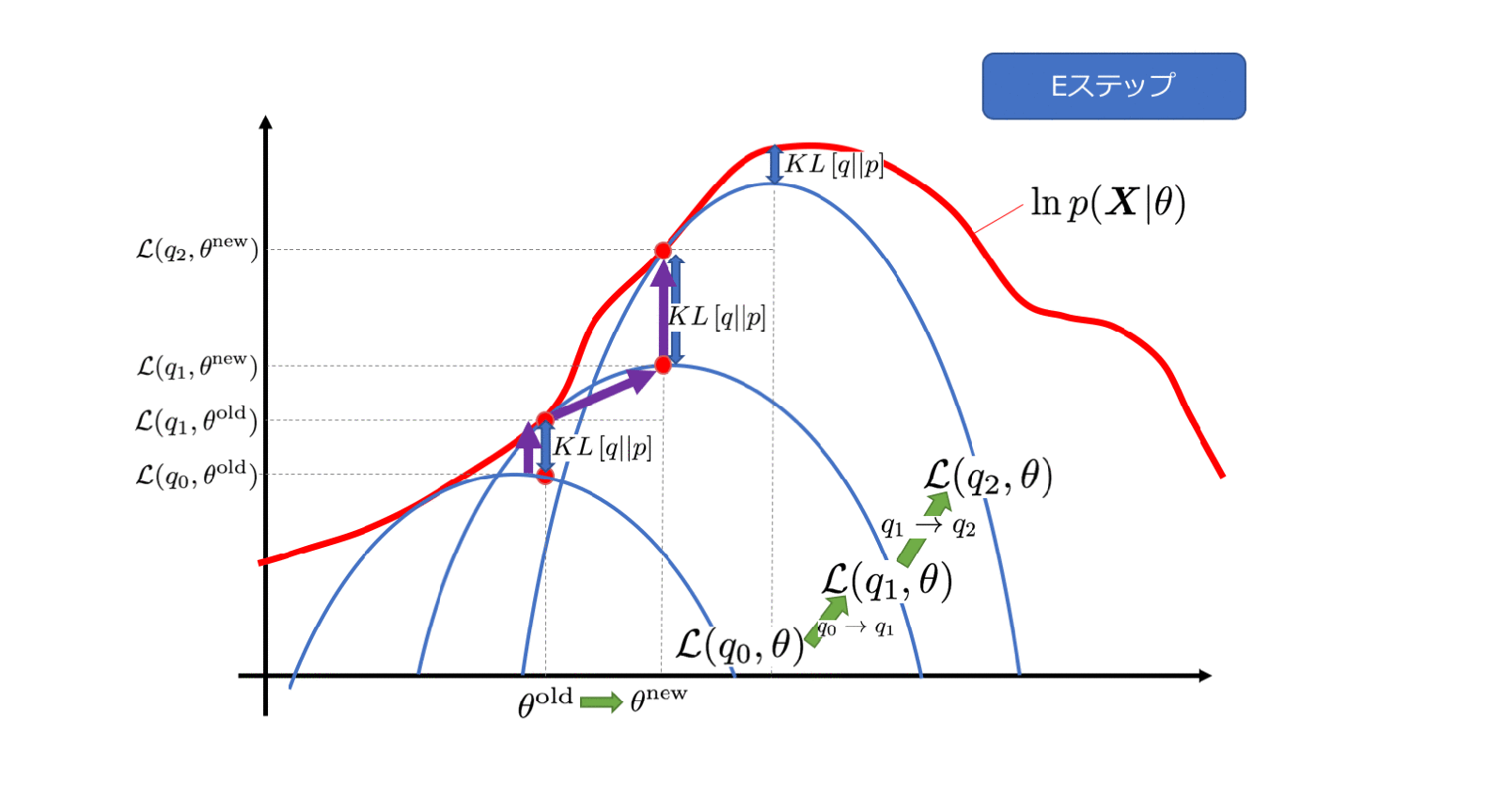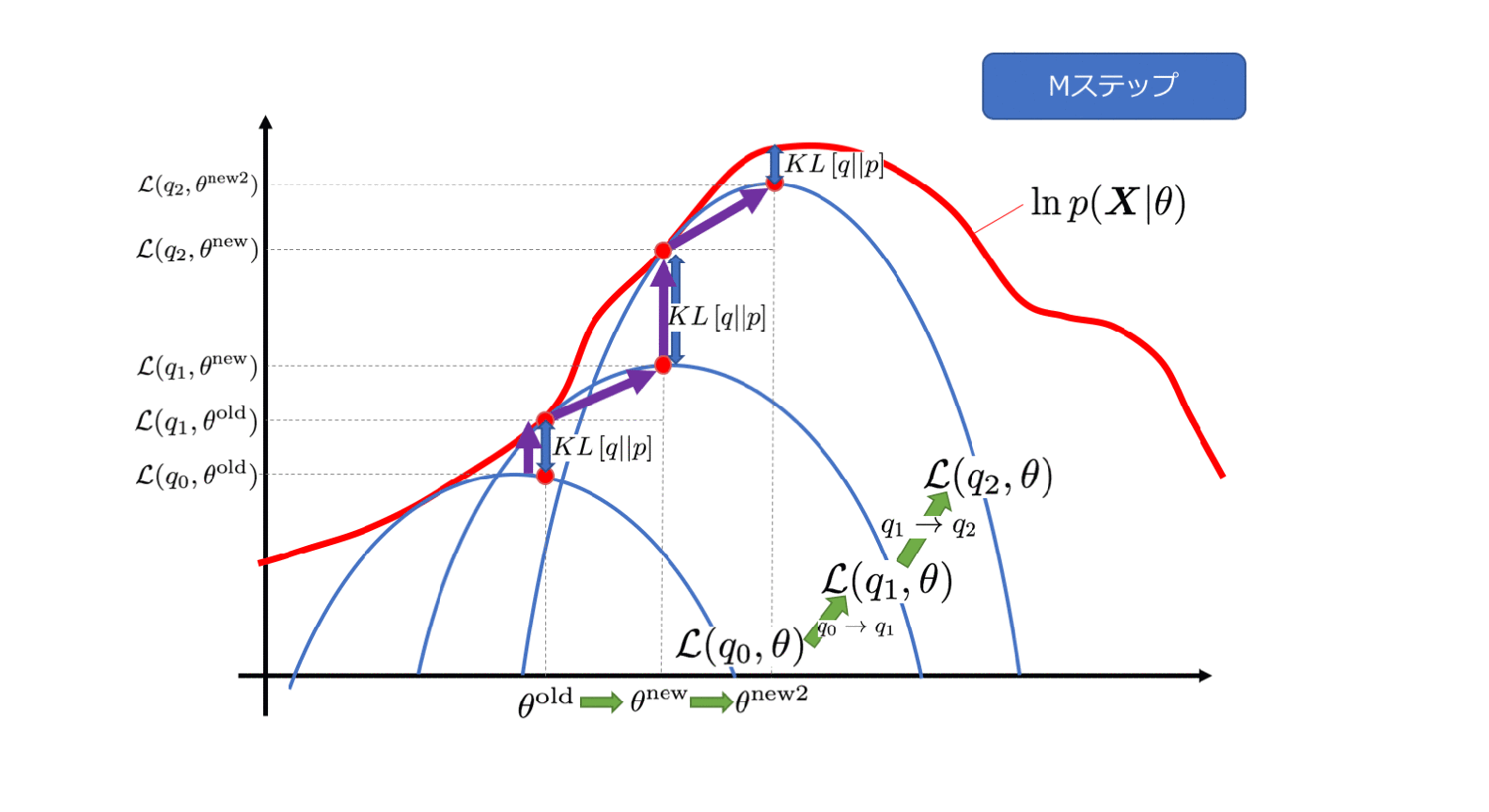
0x33 意义解读
E步来看,
(以下参考了人人都懂EM算法 ,略有修改)
(1)右边乘以了
q ( z ( k ) ) q ( z ( k ) ) = 1
q
(
z
(
k
)
)
q
(
z
(
k
)
)
=
1
,而引进的未知分布q满足
∑ z q ( z ( k ) ) = 1
∑
z
q
(
z
(
k
)
)
=
1
(2)里面的
∑ z q ( z ( k ) ) log P ( x ( k ) , z ( k ) | θ ) q ( z ( k ) )
∑
z
q
(
z
(
k
)
)
log
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
q
(
z
(
k
)
)
其实是对
log P ( x ( k ) , z ( k ) | θ ) q ( z ( k ) )
log
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
q
(
z
(
k
)
)
求加权平均,也就是求它的数学期望(Expectation):
E ( log P ( x ( k ) , z ( k ) | θ ) q ( z ( k ) ) )
E
(
log
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
q
(
z
(
k
)
)
)
,这也是E步的名字来源。
为了让(2)能够取等号,也就是让
L ( θ , z )
L
(
θ
,
z
)
取一个下限,Jensen不等式告诉我们上面的数学期望里面的变量需要是一个常数,即
log P ( x ( k ) , z ( k ) | θ ) q ( z ( k ) ) = c
log
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
q
(
z
(
k
)
)
=
c
去掉log之后有
P ( x ( k ) , z ( k ) | θ ) = c q ( z ( k ) )
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
=
c
q
(
z
(
k
)
)
累加后
∑ z P ( x ( k ) , z ( k ) | θ ) = c ∑ z q ( z ( k ) ) = c
∑
z
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
=
c
∑
z
q
(
z
(
k
)
)
=
c
所以即
q ( z ( k ) ) = P ( x ( k ) , z ( k ) | θ ) c = P ( x ( k ) , z ( k ) | θ ) ∑ z P ( x ( k ) , z ( k ) | θ ) = P ( x ( k ) , z ( k ) | θ ) P ( x ( k ) | θ ) = P ( z ( k ) | x ( k ) , θ )
q
(
z
(
k
)
)
=
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
c
=
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
∑
z
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
=
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
P
(
x
(
k
)
|
θ
)
=
P
(
z
(
k
)
|
x
(
k
)
,
θ
)
q也就是已知
θ
θ
和
x ( k )
x
(
k
)
情况下求隐变量
z ( k )
z
(
k
)
的分布,也就是隐变量的后验概率。然后我们才能继续算下面M步需要用到的
Q ( θ , θ o l d )
Q
(
θ
,
θ
o
l
d
)
θ
θ
不是未知数么?说得好,所以(3)里面代入了上次迭代算出的模型参数
θ o l d
θ
o
l
d
。
Q ( θ , θ o l d ) = E z | X , θ o l d ( log L ( X , Z | θ ) )
Q
(
θ
,
θ
o
l
d
)
=
E
z
|
X
,
θ
o
l
d
(
log
L
(
X
,
Z
|
θ
)
)
以上是E步。
M步来看,
最大化
Q ( θ , θ o l d )
Q
(
θ
,
θ
o
l
d
)
更新
θ
θ
。((5)右边的constant可以忽略,不影响最大化似然函数的操作)
也就是
θ = arg max θ Q ( θ , θ o l d ) = arg max θ ∑ m k = 1 ∑ z q ( z ( k ) | x ( k ) , θ o l d ) log P ( x ( k ) , z ( k ) | θ )
θ
=
arg
max
θ
Q
(
θ
,
θ
o
l
d
)
=
arg
max
θ
∑
k
=
1
m
∑
z
q
(
z
(
k
)
|
x
(
k
)
,
θ
o
l
d
)
log
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
以上是M步。
另一个角度来看,
∑ k = 1 m log P ( x ( k ) | θ ) = ∑ k = 1 m ∑ z q ( z ( k ) ) log P ( x ( k ) | θ ) P ( z ( k ) | x ( k ) , θ ) P ( z ( k ) | x ( k ) , θ ) ( 6 ) = ∑ k = 1 m ∑ z q ( z ( k ) ) log P ( x ( k ) , z ( k ) | θ ) P ( z ( k ) | x ( k ) , θ ) ( 7 ) = ∑ k = 1 m ∑ z q ( z ( k ) ) { log P ( x ( k ) , z ( k ) | θ ) q ( z ( k ) ) − log P ( z ( k ) | x ( k ) , θ ) q ( z ( k ) ) } ( 8 ) = ∑ k = 1 m ∑ z q ( z ( k ) ) log P ( x ( k ) , z ( k ) | θ ) q ( z ( k ) ) − ∑ k = 1 m ∑ z q ( z ( k ) ) log P ( z ( k ) | x ( k ) , θ ) q ( z ( k ) ) ( 9 ) = L ( θ , z ) + K L [ q ( z ) | | P ( z | x , θ ) ] ( 10 )
∑
k
=
1
m
log
P
(
x
(
k
)
|
θ
)
=
∑
k
=
1
m
∑
z
q
(
z
(
k
)
)
log
P
(
x
(
k
)
|
θ
)
P
(
z
(
k
)
|
x
(
k
)
,
θ
)
P
(
z
(
k
)
|
x
(
k
)
,
θ
)
(
6
)
=
∑
k
=
1
m
∑
z
q
(
z
(
k
)
)
log
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
P
(
z
(
k
)
|
x
(
k
)
,
θ
)
(
7
)
=
∑
k
=
1
m
∑
z
q
(
z
(
k
)
)
{
log
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
q
(
z
(
k
)
)
−
log
P
(
z
(
k
)
|
x
(
k
)
,
θ
)
q
(
z
(
k
)
)
}
(
8
)
=
∑
k
=
1
m
∑
z
q
(
z
(
k
)
)
log
P
(
x
(
k
)
,
z
(
k
)
|
θ
)
q
(
z
(
k
)
)
−
∑
k
=
1
m
∑
z
q
(
z
(
k
)
)
log
P
(
z
(
k
)
|
x
(
k
)
,
θ
)
q
(
z
(
k
)
)
(
9
)
=
L
(
θ
,
z
)
+
K
L
[
q
(
z
)
|
|
P
(
z
|
x
,
θ
)
]
(
10
)
(6)引入了隐函数后,(7)通过条件概率公式变换概率函数,然后就可以得到(10)。这里可以看出,我们是在构造一个隐函数的分布q。因为我们想让似然函数最大,那就是说(10)第二项的KL散度尽可能小,也就是要让构造出来的q尽可能和真实的隐函数分布接近,这时候
q ( z ) = P ( z | x , θ )
q
(
z
)
=
P
(
z
|
x
,
θ
)
,KL散度为零。
同时可以看出来刚才的(2)步的让Jensen不等式取等号的操作也是在让KL散度为零构造下限,也就是让
q ( z ) = P ( z | x , θ )
q
(
z
)
=
P
(
z
|
x
,
θ
)
取q分布的期望(Expectation)当做隐函数分布的估算。
然后利用q分布再对对数似然函数最大化(Maximization)更新
θ
θ
。
这个也是所谓的九层境界里面的第二层。(EM算法的九层境界:Hinton和Jordan理解的EM算法 )
0x40 GMM混合高斯分布的例子
有空再更新
其他
参考及延伸
[1] PRML
[2] 知乎: 怎么通俗易懂地解释EM算法并且举个例子? :彭一洋的回答有概括性的数学公式
[3] Do, C. B., & Batzoglou, S. (2008). What is the expectation maximization algorithm? Nature Biotechnology, 26(8), 897–899. https://doi.org/10.1038/nbt1406
[4] https://ibug.doc.ic.ac.uk/media/uploads/documents/expectation_maximization-1.pdf
[5] 如何感性地理解EM算法?(抛硬币的详解)
[6] EMアルゴリズム徹底解説
[7] EM算法的九层境界:Hinton和Jordan理解的EM算法
[8] 机器学习系列-强填EM算法在理论与工程之间的鸿沟(上)
[9] 机器学习系列-强填EM算法在理论与工程之间的鸿沟(下)
վ HᴗP ի