概率模型有时既含有观测变量(observable variable),又含有隐变量(latent variable)。如果概率模型的变量都是观测变量,那么给定数据,可以直接用极大似然估计或贝叶斯估计来计算模型参数。但是,当模型含有隐变量时,就不能简单地使用以上估计方法,而EM算法就是针对含有隐变量的概率模型参数的极大似然估计法。
一般地,用
X
表示可观测随机变量的数据,
Z
表示隐随机变量的数据,
X
和
Z
连在一起称为完全数据(complete-data),观测数据
X
又称为不完全数据(incomplete-data)。假设给定观测数据
X
,其概率分布是
P(X|θ)
,其中
θ
是需要估计的模型参数,那么不完全数据
X
的似然函数是
P(X|θ)
,对数似然函数
L(θ)=logP(X|θ)
;假设
X
和
Z
的联合概率分布是
P(X,Z|θ)
,那么完全数据的对数似然函数是
logP(X,Z|θ)
。对于不完全数据的统计估计问题,EM算法已经成为了一种通用的工具。
从掷硬币实验说起
给定两枚硬币
A
和
B
,它们出现正面的概率分别为
θA
和
θB
(未知),我们的目标是通过重复5次以下实验来估计
θ=(θA,θB)
。
选择一枚硬币,并且知道具体是哪一枚,然后用选中的硬币掷十次,记录结果。因此,总共进行了50次掷硬币的实验。如下图所示
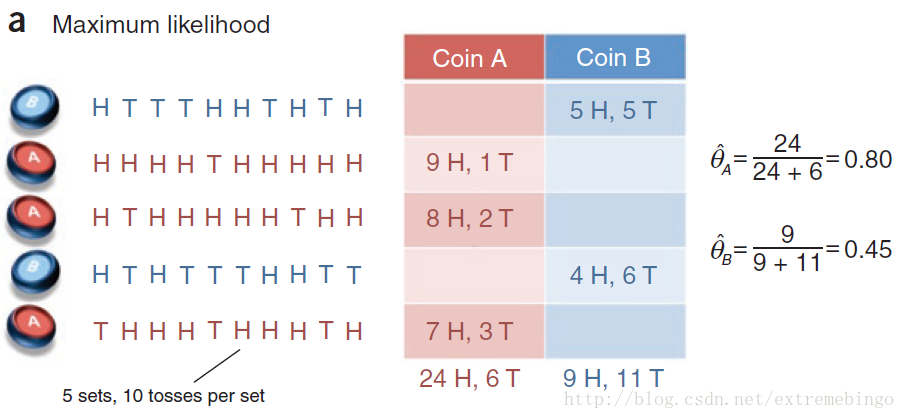
现在,引入两个随机变量
X={X1,X2,X3,X4,X5}
和
Z={Z1,Z2,Z3,Z4,Z5}
,其中
Xi∈{0,1,⋯,10}
表示第
i
次实验硬币正面朝上的次数,
Zi∈{A,B}
表示第
i
次实验所用的硬币。上述问题为完全数据的参数估计问题,可通过正面出现的比例进行估计
θA^=# of heads using coin Atotal # of flips using coin AθB^=# of heads using coin Btotal # of flips using coin B
事实上,上述的估计方式就是统计学上的最大似然估计。
现在考虑一个更有挑战性的参数估计问题。只给定硬币出现正面的次数,而不给定是由哪一枚硬币掷出的,即
Z
为隐含变量。因此,该问题就转化为不完全数据的参数估计问题。此时,由于不知道具体是哪一枚硬币,所以无法通过直接计算硬币出现正面的次数来估计
θ
。当概率模型存在隐变量时,不能简单地使用极大似然估计,需要采用下文的EM算法来计算模型参数。
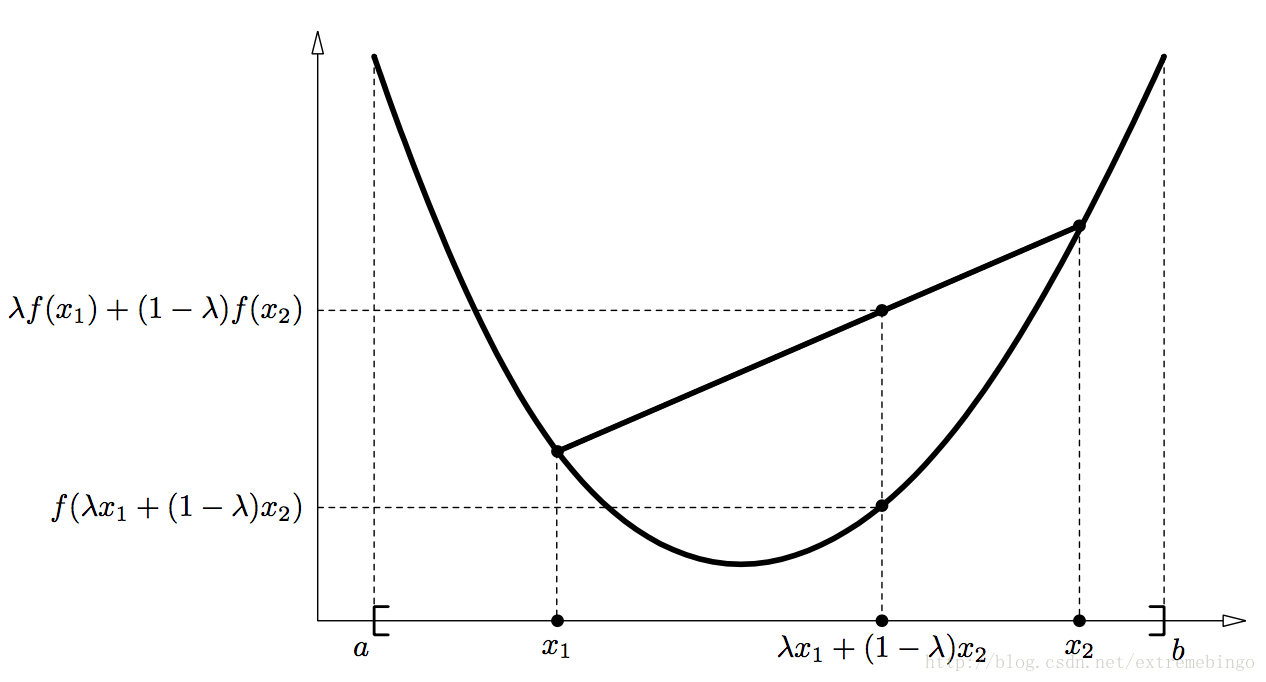
凸函数
定义1 定义在区间
I=[a,b]
上的实函数
f
,如果对于
∀x1,x2∈I,λ∈[0,1]
,函数
f
满足以下不等式
f(λx1+(1−λ)x2)≤λf(x1)+(1−λ)f(x2)(1)
则称函数
f
为凸函数。其几何解释如下图所示
定义2 如果函数
−f
是凸函数,则函数
f
是凹函数。
定理1 如果函数
f
在区间
[a,b]
上二阶可导,并且
f′′(x)≥0
,则
f
在区间
[a,b]
上为凸函数。
定理2(Jensen inequality)
f
为区间
[a,b]
上的凸函数,若
x1,x2,⋯,xn∈I
,并且
λ1,λ2,⋯,λn≥0,∑ni=1=1
,则以下不等式成立
f(∑i=1nλixi)≤∑i=1nλif(xi)(2)
证明: 使用数学归纳法证明
- 当
n=1
时,(2)式显然成立,并取得等号。
- 当
n=2
时,即为凸函数的定义。
- 假设当
n=n
时(2)式成立,则
f(∑i=1n+1λixi)=f(λn+1xn+1+∑i=1nλixi)=f(λn+1xn+1+(1−λn+1)11−λn+1∑i=1nλixi)≤λn+1f(xn+1)+(1−λn+1)f(11−λn+1∑i=1nλixi))=λn+1f(xn+1)+(1−λn+1)f(∑i=1nλi1−λn+1xi))≤λn+1f(xn+1)+(1−λn+1)∑i=1nλi1−λn+1f(xi)=λn+1f(xn+1)+∑i=1nλif(xi)=∑i=1n+1λif(xi)
得证。
因为
λ1,λ2,⋯,λn≥0,∑ni=1=1
,所以当
X
为随机变量时,Jensen inequality可以写成
Ef(X)≥f(EX)(3)
图形表示为
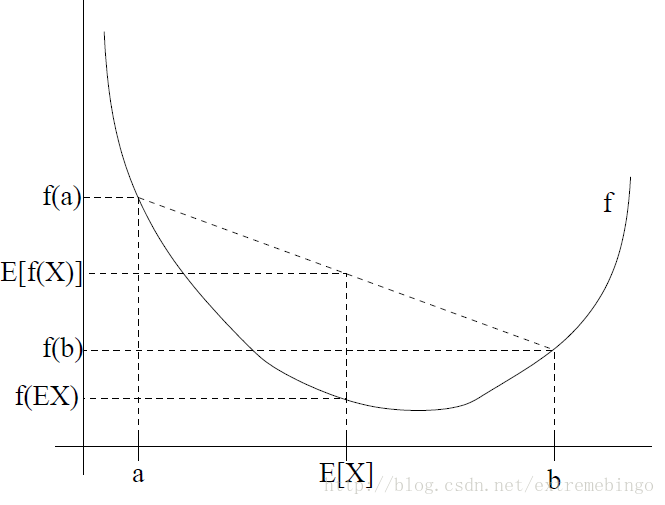
EM算法
对于含有隐含变量的数据,EM算法是一个用于计算最大概率的高效的迭代过程,我们希望通过估计得到的模型参数可以使得观测到的数据出现的可能性最大。
EM算法的导出
对于一个含有隐含变量
Z
的概率模型,假设有
m
个样本
{x(1),x(2),⋯,x(m)}
,目标是极大化观测数据(不完全数据)
X
关于参数
θ
的对数似然函数,即极大化
l(θ)=∑i=1mlogp(x;θ)=∑i=1mlog∑Zp(x,z;θ)(4)
极大化的主要困难在于上式中存在隐变量。最大化的
l(θ)
很难求得,但是我们可以构造
l(θ)
的下边界(E-step),然后优化该下边界(M-step),不断重复以上过程。
令
Qi
表示
z
的分布,满足条件
∑zQi(z)=1,Qi(z)≥0
∑ilogp(x(i);θ)=∑ilog∑z(i)p(x(i),z(i);θ)=∑ilog∑z(i)Qi(z(i))p(x(i),z(i);θ)Qi(z(i))≥∑i∑z(i)Qi(z(i))logp(x(i),z(i);θ)Qi(z(i))(5)
最后一步是由Jensen inequality得到的。并且,
∑z(i)Qi(z(i))logp(x(i),z(i);θ)Qi(z(i))
为
p(x(i),z(i);θ)Qi(z(i))
关于
z(i)
的期望。
对于任意的分布
Qi
,(5)式给出了
l(θ)
的下边界。现在的问题是如何选择
Qi
。
最直接的想法是,对于特定的
θ
,使得下边界尽可能地靠近
l(θ)
,即选择合适的
Qi
,使得(5)式的等号成立。由Jensen inequality可知,若要使得等号成立,需满足以下条件
p(x(i),z(i);θ)Qi(z(i))=c
其中
c
不依赖于
z(i)
。因此,只要使得
Qi(z(i))∝p(x(i),z(i);θ)
因为
Qi
需满足
∑zQi(z(i))=1
,因此可以取
Qi(z(i))=p(x(i),z(i);θ)∑zp(x(i),z;θ)=p(x(i),z(i);θ)p(x(i);θ)=p(z(i)|x(i);θ)(6)(7)
(6)式等号右边对
z(i)
求和可以保证为1。
现在,通过将
Qi
设置为(7)式,我们得到了(5)式的最大化下边界,这就是E-step。在M-step中,求得一个新的
θ
,使得(5)式最大化。即
Repeat until convergence {(E−step) For each i, set Qi(z(i)):=p(z(i)|x(i);θ).(M−step) Set θ:=argmaxθ∑i∑z(i)Qi(z(i))logp(x(i),z(i);θ)Qi(z(i))}
下图为迭代过程的图形化表示
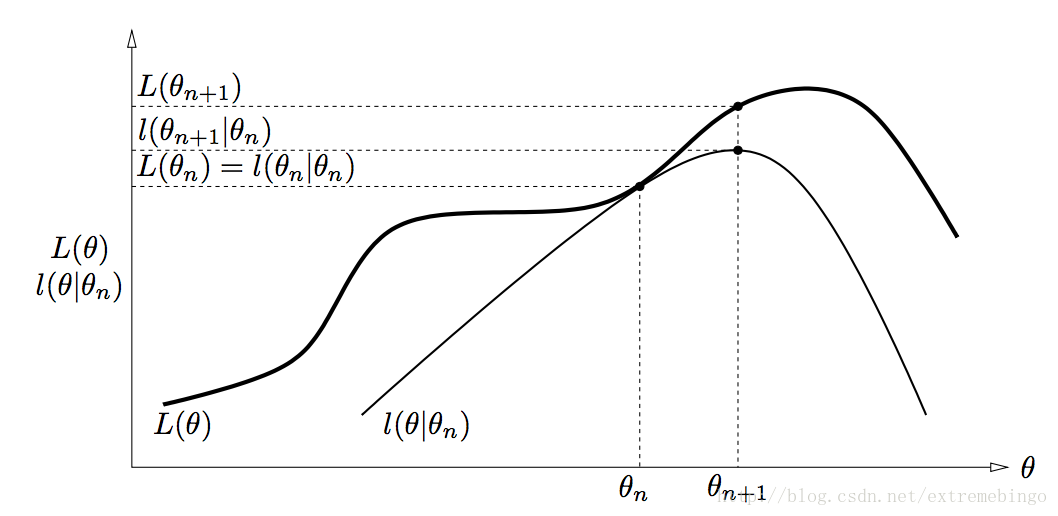
收敛性
假设参数
θ(t)
和
θ(t+1)
是由两个连续的迭代过程求得的,下面来证明EM算法的每一次迭代都会改善似然函数,即
l(θ(t))≤l(θ(t+1))
。这个过程依赖
Qi
的选择,当给定参数
θ(t)
时,设置
Qi
为
Q(t)i:=p(z(i)|x(i);θ(t))
,由此可通过(5)式得到
l(θ(t))=∑i∑z(i)Q(t)i(z(i))logp(x(i),z(i);θ(t))Qi(z(i))(8)
同样由式(5)可得
l(θ(t+1))≥∑i∑z(i)Q(t)i(z(i))logp(x(i),z(i);θ(t+1))Q(t)i(z(i))≥∑i∑z(i)Q(t)i(z(i))logp(x(i),z(i);θ(t))Q(t)i(z(i))=l(θ(t))(9)
式(9)是因为
θ(t+1)
是由下式迭代得到的
argmaxθ∑i∑z(i)Qi(z(i))logp(x(i),z(i);θ)Qi(z(i))
综上所述,
l(θ)
单调递增。可以将在连续的两次迭代中,
l(θ)
值的变化小于某一阈值作为停止迭代的条件。
note: EM算法只能保证参数估计序列收敛到对数似然函数序列的极大值点,不能保证收敛到最大值点。所以在应用中,初值的选择变得非常重要,常用的方法是选取几个不同的初值进行迭代,然后对得到的各个估计值加以比较,从中选择最好的。
再看掷硬币问题
其中一种迭代方式入下:

从理论公式推导高斯混合模型
随机变量
X
是由
k
个高斯分布混合而成,取得各个高斯分布的概率为
ϕ1,ϕ2,⋯,ϕk
,第
i
个高斯分布的均值为
μi
,方差为
Σi
。若观测到随机变量
X
的一系列样本
{x(1),x(2),⋯,x(m)}
,试估计参数
ϕ,μ,Σ
。
E-step
w(i)j=Qi(z(i)=j)=p(z(i)=j|x(i);ϕ,μ,Σ)
w(i)j
表示第i个样本
x(i)
属于第
j
个分模型的概率。
M-step
将多项分布和高斯分布的参数代入,并求解
ϕ,μ,Σ
使得式(5)取最大值,即
∑i=1m∑z(i)Qi(z(i))logp(x(i),z(i);ϕ,μ,Σ)Qi(z(i))=∑i=1m∑j=1kQi(z(i)=j)logp(x(i)|z(i)=j;μ,Σ)p(z(i)=j;ϕ)Qi(z(i)=j)=∑i=1m∑j=1kw(i)jlog1(2π)n/2|Σj|1/2exp(−12(x(i))−μj)TΣ−1j(x(i))−μj)⋅ϕjw(i)j(10)
对高斯分布的均值
μl
求偏导
∇μl∑i=1m∑j=1kw(i)jlog1(2π)n/2|Σj|1/2exp(−12(x(i)−μj)TΣ−1j(x(i)−μj)⋅ϕjw(i)j=−∇μl∑i=1m∑j=1kw(i)j12(x(i)−μj)TΣ−1j(x(i)−μj)=12∑i=1mw(i)j∇μl2(μTlΣ−1lx(i)−μTlΣ−1lμl)=∑i=1mw(i)j(Σ−1lx(i)−Σ−1lμl)
令其等于0可得
μl:=∑mi=1w(i)lx(i)∑mi=1w(i)l(11)
同理,对高斯分布的方差求偏导可得
Σj:=∑mi=1w(i)j(x(i)−μj)(x(i)−μj)T∑mi=1w(i)j(12)
求多项分布的参数
ϕ
,删除(10)式中的常数项,得
∑i=1m∑j=1kw(i)jlogϕjs.t. ∑j=1kϕj=1
由于
log(⋅)
已经约束了
ϕj>0
,所以约束条件中没有该约束。
建立拉格朗日方程
L(ϕ)=∑i=1m∑j=1kw(i)jlogϕj+β(∑j=1kϕj−1)(13)
对
ϕj
求偏导,并令其等于0
∂L(ϕ)∂ϕj=∑i=1mw(i)jϕj+β−β=∑i=1m∑j=1kw(i)j=∑i=1m1=mϕj=1m∑i=1mw(i)j(14)
至此,由EM算法求解出了高斯混合模型的所有参数(11)(12)(14)。
参考文献
[1] 李航. 统计学习方法[M]. 清华大学出版社, 2012
[2] Borman S. The expectation maximization algorithm-a short tutorial[J]. Submitted for publication, 2004: 1-9.
[3] Do C B. What is the expectation maximization algorithm?[J]. Nature Biotechnology, 2008, 26(8):897-9.
[4] Andrew Ng. CS229 Lecture notes: The EM algorithm.