一、原理
期望极大算法(EM,Expectation Maximization)是一种能够得到极大似然参数估计的迭代方法。虽然EM算法在不同的领域被更早的提出,但它是由Dempster等人于1977年被正式命名并给出解释。
对于一个除了拥有未知参数和可观测变量外,还包含隐含变量的统计模型来说,是无法用极大似然方法直接得到参数的,这是因为我们不能像极大似然法那样,同时对未知参数和隐含变量求导来求解似然函数。但该模型可以应用EM算法得到,它是通过可观测变量分别求解两个方程,即把第一个方程的解代入第二个方程中,再把第二个方程的解代入第一个方程中,依次类推直到收敛为止。虽然EM算法不能保证得到全局极值点,但可以通过一些方法得到改善,如选取不同的初始值,比较最终的结果。
下面我们就来详细推导EM算法。
给定一组相互独立且同分布的训练样本X={x1,x2,…,xn},每个样本都是一个d维的向量,即每个样本都具有d个特征属性,xi∈Rd,设p(X|θ)为被参数θ控制的概率密度函数,如X服从高斯正态分布,则θ表示均值μ和标准差σ,即X~N(μ, σ2):
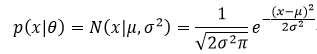
似然函数是一种关于统计模型中参数的函数,表示模型参数中的似然性,则参数θ在X下的似然函数为:
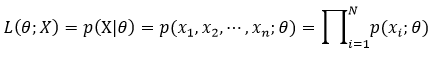
实际上为了便于计算,我们往往应用的是对数似然函数,即把式2写为:

该似然函数L(θ|X)反映了在基于可观测到的样本值X下,与真实统计模型相似程度的大小,因此我们有理由认为L(θ|X)的最大值所对应的参数θ*就是真实模型的参数,即

这种参数估计的方法就称为极大似然法,而参数θ*就是对L(θ|X)求一阶偏导为0时所对应的值。极大似然法对单一统计模型的参数估计简单实用,但它不适用对混合统计模型参数的估计。
设Z为某一样本数据,它除了有可观测的变量X={x1,x2,…,xn}外,还包含一个隐含变量Y={y1,y2,…,yn},Y可以看成是X的输出或类别标签,yi∈{1,…,K},K表示样本类别的数量,这意味着Z的统计模型是混合统计模型。我们把Z=(X, Y)称为完整数据,而把X称为不完整数据。无论样本是否包含隐含变量,参数的估计都是基于所观测到的数据的,所以我们要对Z的统计模型参数θ进行估计,应用的是基于所观测到的不完整数据X的似然函数:

式中,p(xi| θ)=∑jp(xi,yj|θ)表示观测到的变量xi的概率分布为所有类标签yi(i=1,…,K)下xi的概率之和。式5中包含了“和的对数(ln∑)”的形式,因此我们还是应用导数为0的方法求最大值就不那么容易了。
很明显,如果Y已知,则通过完整数据Z的似然函数——L(θ; X, Y)=ln p(X, Y| θ)可以很容易的得到参数θ。L(θ; X, Y)其实是一个X和θ是常数,Y是随机变量的函数。
基于引入的隐含变量,EM算法给出了一种非常有效的处理极大似然参数估计的迭代方法。每次迭代都包括两个步骤:期望步骤(E-Step)和极大步骤(M-Step)。
在E-Step中,需要计算在给定X和当前参数估计下,关于Y的完整数据的对数似然函数ln p(X, Y| θ)的期望值,其定义为:
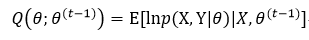
式中,θ(t-1)为当前的参数估计,我们用该参数来得到期望值,而θ是新的参数,我们用它来优化提高Q值。关于式6,我们需要明确的是X和θ(t-1)是常数,θ是我们希望调整的一般变量,而Y是基于分布函数p(Y| X, θ(t-1))的离散随机变量,则由数学期望的定义,lnp(X, Y| θ)的期望值表示为:

p(Y| X, θ(t-1))是依赖于可观测变量X和当前参数θ(t-1)的、未观测变量Y的边缘分布函数,ϒ表示yi的取值范围,即前面定义的{1,…,K}。
在M-Step中,最大化E-Step的期望值:

θ(t)为本次迭代得到估计参数,它被用于下次迭代的E-Step中。那么第一次迭代中E-Step所使用的θ(0)为任意选取的。
EM算法的精髓就是用完整数据的对数似然函数的期望值不断迭代,最终得到不完整数据的最大似然估计。我们分析一下为什么会有这样的结果。
由联合分布概率可知:
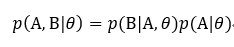
则X的对数似然函数为:

对上式两边同乘以p(yi | X, θ(t-1)),则

然后对上式两边在yi的取值范围ϒ内进行求和,因为
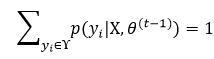
所以式11改写为:

上式第一项就是式7所定义的Q(θ; θ(t-1)),而第二项我们定义为H(θ;θ(t-1)),则
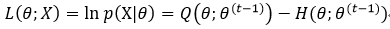
为什么我们仅仅通过迭代的方式不断找到能使Q(θ; θ(t-1))达到最大值的θ(t)就能保证此时的似然函数最大呢?即

式15表现的是EM算法的单调性。如果满足下列条件,式15就必然成立:
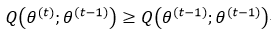
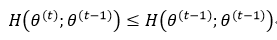
式16已经能够由EM算法中的M-Step得到保证(式8),所以关键就要证明式17成立。这里面我们要用到一个很重要的概念——Jensen不等式。
设f为定义在I=[a, b]的一个实数域函数,如果满足下列条件,则f称为凸函数:
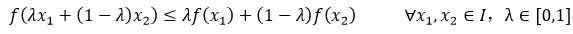
很显然,如果-f是凸函数,则f就是凹函数,ln(x)函数是凹函数。
如果f是定义在区间I上的凸函数,则满足:
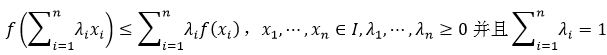
式19的证明会用到式18的结论,下面我们就给出式19的证明:
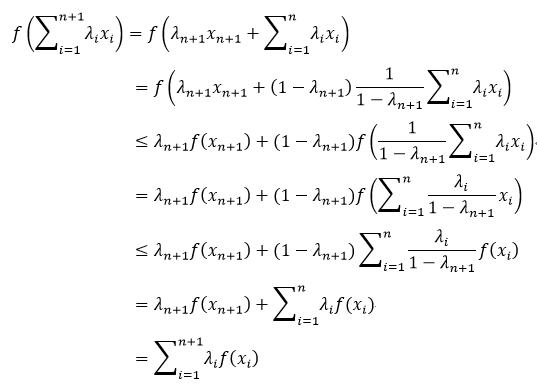
我们称式19所表示的不等式为Jensen不等式,而当λi=f(xi)时,

因为ln(x)函数是凹函数,所以有
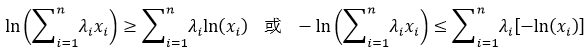
有了Jensen不等式的概念,我们再回到式17。要想使式17成立,只要证明下式即可:
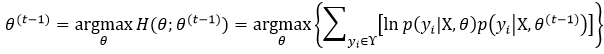
而对于任意θ来说,下式成立,则式23就成立:
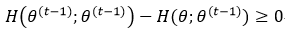
下面我们就来证明式24:

由于p(yi | X, θ(t-1))是概率分布,所以它满足Jensen不等式中对λi的条件(对比式12和式19中λi的条件),因此应用Jensen不等式,式25改写为:
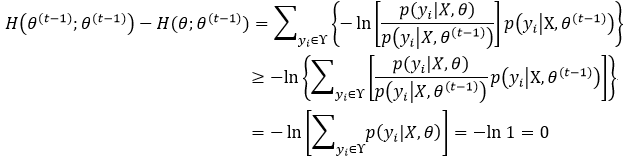
式24成立,则式17就成立,最终式15就成立,即不断迭代得到的完整数据的似然函数的期望值可以保证收敛于局部极值。
EM算法的原理部分就介绍到这里,下面我们以高斯混合模型(GMM)为例,具体讲解如何由EM算法得到该模型的参数。
设高斯混合模型由K个高斯分布模型(即K个高斯成分)构成:
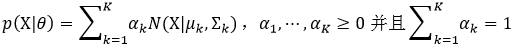
可以看出,高斯混合模型的参数θ不仅包含高斯参数:μ和∑,还包括每个高斯成分的权值因子αk,因此参数θ为:

样本X={x1,x2,…,xn},xi∈Rd,隐含变量Y={y1,y2,…,yn},yi表示xi属于K个高斯成分的哪一个。则式27可以进一步写为:
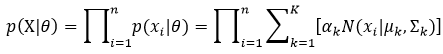
为了计算式6中的Q函数,我们还需要给出p(X, Y| θ)和p(Y| X, θ)。

式中,p(xi| yi,θ)表示yi所指向的高斯成分的概率分布模型,p(yi|θ)表示yi所指向的高斯成分的权值因子αk,因此p(X, Y|θ)又可写为
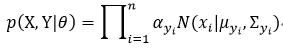
p(Y| X, θ)定义为
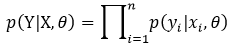
则式6中的Q函数表示为:
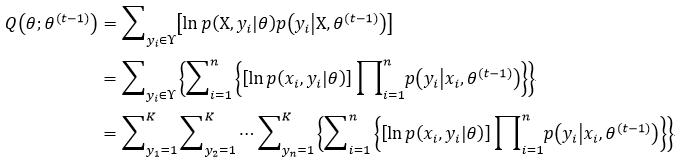
我们还需要对式33做进一步化简,此时我们用到了下面这个定理:
设p(Y)为联合概率分布:p(Y)=p(y1, y2,…,yn)= p1(y1)p2(y2)…pn(yn),F(Y)为一个线性函数,且F(Y)=f1(y1)+f2(y2)+…+fn(yn),则
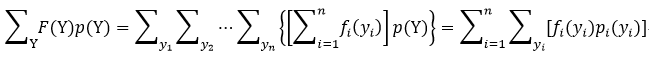
我们简单证明一下式34:
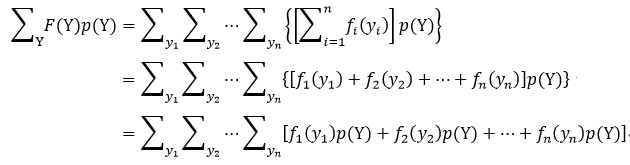
对式35中的累加和,我们仅拿出第一项来进行分析,即
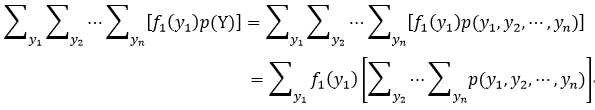
很显然,式36中方括号内的部分就是p1(y1)的边缘概率分布,所以

我们把式37的结论应用到式35中累加和的其他项,则就得到了式34

式33和式34相比较,可以看出,式33中的log p(xi, yi|θ)就相当于式34中的fi(yi),p(yi| xi,θ(t-1))就相当于pi(yi),所以Q函数又写为:
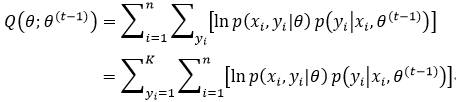
式39的第二个等式仅仅是交换了两个累加和的次序。我们用高斯模型分布代替p(xi, yi|θ),并用混合高斯模型代替隐含变量yi,则式39又写为:
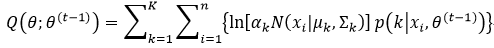
我们通过一步步的推导终于得到了高斯混合模型EM算法中E-Step所需的Q函数,下面就进入M-Step,计算Q函数的参数θ的最大值。由式28可知,参数θ包括αk,μk和∑k。我们再对式40进行分解:
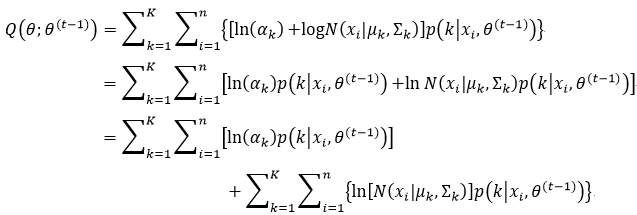
式41中的第一项仅仅含有参数αk,而第二项仅仅含有参数μk和∑k,因此我们可以分别独立的对这两项取最大值。在这里,需要再次强调的是,参数θ(t-1)是常数,不是未知变量。
首先我们利用第一项算式计算αk的最大值,这意味着:
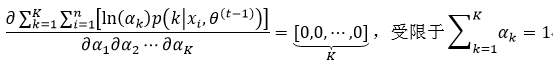
利用拉格朗日乘子,很容易得到式42的结果,即
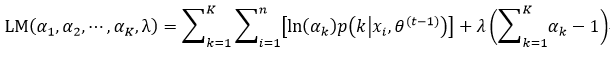
式中,λ即为引入的拉格朗日乘子,我们对式43求偏导,并使其为0:
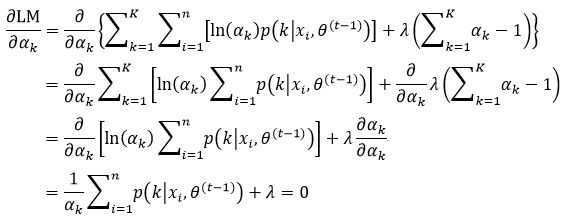
对式44整理,得到
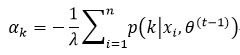
对式45等式两边以k为变量求和,即
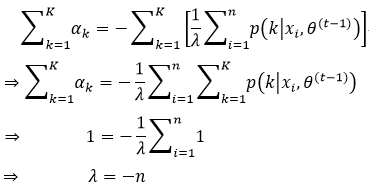
把式46的结果代入式45,得到

下面我们利用式41的第二项算式计算μk和∑k的最大值。设一个均值向量μk和协方差矩阵∑k的d维高斯成分分布的概率密度函数为:
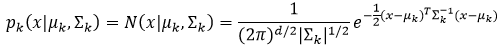
式中的下标k表示第k个高斯成分。要想利用该等式,我们需要回顾一些线性代数方面的知识。
方阵A的秩tr(A)等于A对角线上元素的和,而标量的秩就等于该标量。设A和B为同维数的方阵,x是与B同维数的列向量,且B=xxT,T表示转置,则由tr(A+B)=tr(A)+tr(B)和tr(AB)=tr(BA)可得:
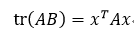
如果|A|表示矩阵行列式的值,则
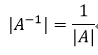
基于矩阵A的函数f(A)对A求导仍然是矩阵,该矩阵中(i, j)元素(第i行第j列的元素)为df(A)/dai,j,ai,j为矩阵A的(i,j)元素,向量也适用该结论。关于矩阵的导数,我们还需要用到下列关系式:

如果A是对称矩阵,则
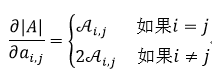
式中,Ai, j表示A的第(i, j)个余因子。利用式52,我们可以得到:
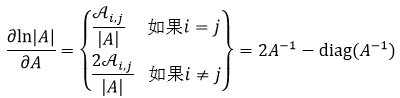
式中,diag(A)表示只取矩阵A的对角线上的元素。最后一个需要用到公式为:
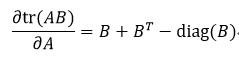
我们再回到式41,把式48带入到式41的第二项算式中:

我们需要μk和∑k的最大值,方法是求偏导,因此我们可以忽略常数项,则式55重新定义为:
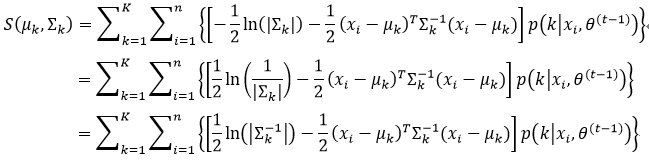
式56中最后一个等式的推导应用到了式50的结论。
我们先求S(μk, ∑k)的μk偏导:
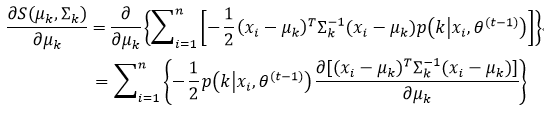
利用式51,并且已知∑是对称矩阵,因此∑-1=(∑-1)T,所以式57的结果为:
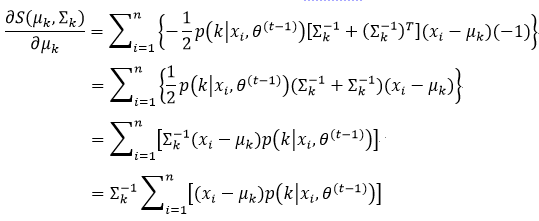
让式58为0,则μk为:

下面计算∑k的最大值,首先我们先对S(μk, ∑k)重新整理:
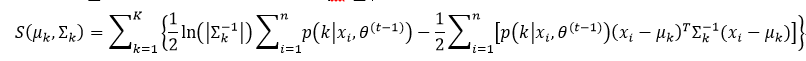
由式49,我们可以对式60进行化简:
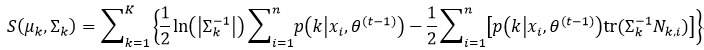
式中,Nk, i=(xi―μk)(xi―μk)T,Nk,i也是对称矩阵。这里需要注意的是,要想得到∑k的最大值,我们需要求S(μk,∑k)的∑k-1偏导,并且在求偏导的过程中,我们还要利用式53和式54:

式中,Mk, i=∑k-Nk,j,并且
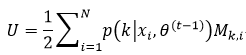
我们让式62等于0,即2U-diag(U)=0,则推出U=0,即
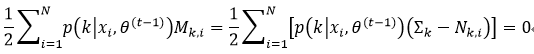
从而得到∑k:
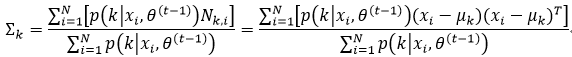
式中μk为式59。
至此,高斯混合模型参数θ中的αk,μk和∑k都已得到,它们作为本次迭代所得到参数,即
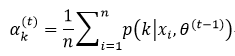

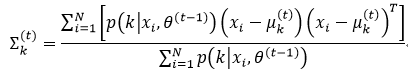
用式66~式68的结果再来求p(k|xi, θ(t-1))。p(k|xi,θ(t-1))表示高斯模型的后验概率,也是样本响应的边缘概率分布,它由贝叶斯规则可以得到,即:
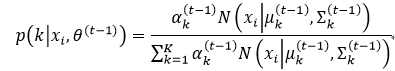
式69的结果再代入式66~式68,这样就实现了一次次迭代的过程。
在第一次迭代之前,我们需要初始化参数。这里有两种初始化参数的方法:第一种是只初始化p(k|xi,θ(0)),然后由式66~式68分别得到αk(1),μk(1)和∑k(1),也就是该种方法是从M-Step开始执行;第二种是初始化αk(0),μk(0)和∑k(0),然后由式69得到p(k|xi,θ(0)),也就是该种方法是从E-Step开始执行。这两种参数初始化的方法效果是相同的。当然在第二种方法中,αk(0),μk(0),和∑k(0)也可以由k-means算法估计得到。
有两种方法用来结束EM算法的迭代:一种是按照迭代的次数;另一种是判断迭代是否足够收敛,而收敛是通过两次迭代中对数似然函数是否足够接近来判断的,即两个对数似然函数之差小于某一极小值时,我们认为迭代收敛了,则EM算法结束。
下式为高斯混合模型的对数似然函数:
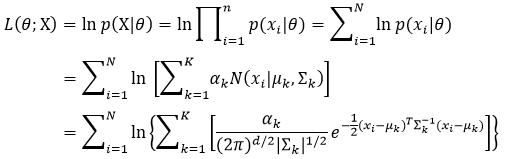
无论是式69还是式70,都需要计算αkN(xi|μk,∑k)。直接计算该部分略显繁琐,不如我们先对其取对数,然后把结果取指数,这样做要容易一些。设αkN(xi|μk,∑k)的对数为LNk,它表示为:
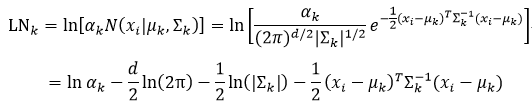
我们再把LNk代回到式70中,为了简单,这里我们只表示样本xi的对数似然,即
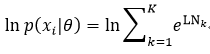
我们观察式72会发现,这里出现了“指数的和的对数”的形式,即
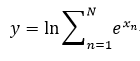
如果我们按正常的方法编写程序计算式73,由于精度的限制,很容易就会使结果上、下溢出,因此我们做适当的调整,把式73改写为:

式中,c为
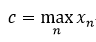
这么做的原理是移动指数部分的中心,迫使最大值为0,即使其他数值下溢出,我们也会得到一个合理的结果,这就是机器学习中经常会遇到的、被称为“log-sum-exp”技巧的算法。下面我们给出它的证明:

对于式69来说,没有对数运算,但如果我们还使用“log-sum-exp”技巧,即增加一个参数c,是否改变了后验概率的值?如果没有,则求后验概率和求对数似然函数就可以应用同一个程序一次完成,这样运行效率会更高。下面我们就来证明一下:


这里的c为:
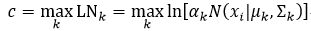
所以对于同一个样本xi来说,c在∑k中是常数,即c对于p(k|xi,θ(t-1))来说是常数,因此式78改写为
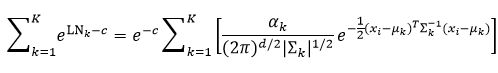
则
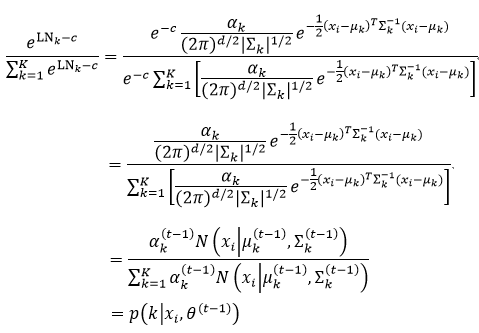
从式81的推导过程来看,即使增加了参数c,也不会改变后验概率的值。
我们再来分析式81或式69:

所以在计算后验概率的时候,可以不考虑(2π)d/2这一项,也就是说当把LNk应用到计算后验概率时,可以不用计算d[ln(2π)]/2。我们把去掉d[ln(2π)]/2项的LNk定义为LN’k,即
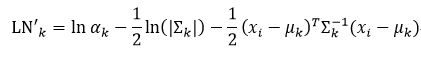
另外在涉及到协方差矩阵时,我们可以应用奇异值分解。由于协方差矩阵∑k是对称矩阵,所以它的奇异值分解为
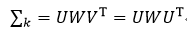
式中,W是由特征值组成的对角线矩阵,U是由特征向量组成的正交矩阵,具有U-1=UT的性质,则∑k的逆矩阵为
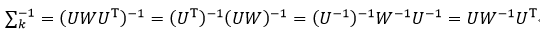
设D=x-μk,则(x-μk)T∑k-1(x-μk)为
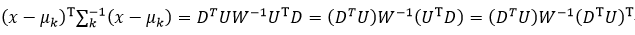
式中,DT是行向量,U是方阵,则DTU为行向量,设该行向量的元素为ai,(DTU)T则为列向量,因为W是对角线矩阵,设该矩阵对角线上的元素为wi,由矩阵的知识可知,W-1也是对角线矩阵,并且其对角线上的元素为1/wi,则式27改写为
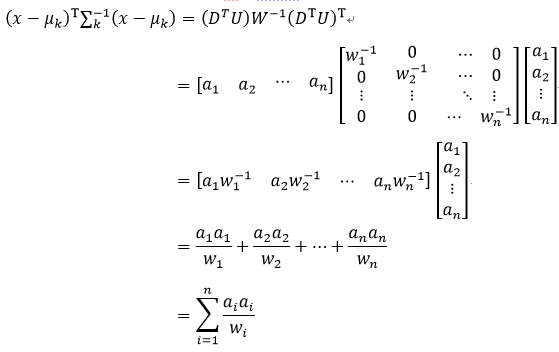
如果∑k就是一个对角矩阵,则∑k=W,此时式86改写为
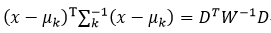
我们还注意到一个性质,那就是行列式的值等于该矩阵特征值的乘积,在前面我们已经得到了∑k的特征值为wi,则它的行列式值为:
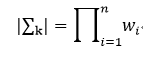
二、源码分析
OpenCV所实现的EM算法是对高斯混合模型的参数估计。与前面介绍过的其他的机器学习算法不同,EM算法是非监督的学习算法,它不需要样本的响应值(即类别标签或函数值)作为输入。相反,它计算的是高斯混合模型参数的极大似然估计。
EM类实现了EM算法,该类的构造函数为:
EM::EM (int nclusters = EM::DEFAULT_NCLUSTERS,
int covMatType = EM::COV_MAT_DIAGONAL,
const TermCriteria& termCrit = TermCriteria
(TermCriteria::COUNT+TermCriteria::EPS, EM::DEFAULT_MAX_ITERS, FLT_EPSILON)
)
nclusters表示高斯混合模型的高斯成分数量,即式27中的K,该参数的缺省值为EM::DEFAULT_NCLUSTERS=5,有些EM算法可以通过优化得到该值,但OpenCV没有实现该功能,所以只能事前确定该值。
covMatType表示对协方差矩阵的一种限制,也就是协方差矩阵的形式,可以选取下列三个值:EM::COV_MAT_SPHERICAL、EM::COV_MAT_DIAGONAL和EM::COV_MAT_GENERIC,其中EM::COV_MAT_DIAGONAL为缺省值。EM::COV_MAT_SPHERICAL表示协方差矩阵是一个标量乘以单位矩阵,即sk×I,所以对协方差矩阵的估计只需要确定sk即可;EM::COV_MAT_DIAGONAL表示协方差矩阵是一个对角线元素为正数的对角矩阵,这时只需要对d个参数进行估计即可,d为样本特征属性的数量;EM::COV_MAT_GENERIC表示协方差矩阵是一个对称的正数矩阵,很显然,此时需要估计d2/2个参数,除非样本数据庞大,否则不建议设置该参数。
termCrit表示EM算法迭代的终止条件,终止条件可以是依据迭代次数termCrit.maxCount,也可以依据对数似然函数值的变化量termCrit.epsilon,也可以两者结合。从输入样本中实现高斯混合模型参数估计的函数有三个,它们的原型分别为:
bool EM::train(InputArray samples, OutputArray logLikelihoods=noArray(), OutputArray labels=noArray(), OutputArray probs=noArray())
bool EM::trainE(InputArray samples, InputArray means0, InputArray covs0=noArray(), InputArray weights0=noArray(), OutputArray logLikelihoods=noArray(), OutputArray labels=noArray(), OutputArray probs=noArray())
bool EM::trainM(InputArray samples, InputArray probs0, OutputArray logLikelihoods=noArray(),OutputArray labels=noArray(), OutputArray probs=noArray())
train函数是从E-Step开始迭代,它所需要的初始参数——均值μk,权值因子αk和协方差矩阵∑k是由k-means算法估计得到。
trainE函数是从E-Step开始迭代,我们需要提供初始的高斯参数中的均值μk,而权值因子αk和协方差矩阵∑k可以不用初始化,也由k-means算法估计得到。
trainM函数是从M-Step开始迭代,我们需要提供初始的后验概率p(k|xi,θ(0))。
在这三个函数中,输入参数的含义分别为:
samples表示输入样本,我们从这些样本中估计出高斯混合模型的参数,该变量为单通道的矩阵形式,行代表一个样本,列代表特征属性,如果该矩阵的数据类型不是CV_64F,则程序内部会自动把它转换为该类型。
means0表示初始化的均值μk,它是单通道的矩阵形式,矩阵的大小为K×d,K为高斯混合成分数量,d为样本特征属性的数量,如果该矩阵的数据类型不是CV_64F,则程序内部会自动把它转换为该类型。
covs0表示初始化的协方差矩阵∑k,它是单通道的矩阵形式,矩阵的大小为d×d,如果该矩阵的数据类型不是CV_64F,则程序内部会自动把它转换为该类型。
weights0表示初始化的权值因子αk,它是单通道的浮点型矩阵形式,矩阵的大小可以是1×K,也可以是K×1。
probs0表示初始化的第i个样本属于第k个高斯成分的后验概率p(k|xi,θ(0)),它是单通道的浮点型矩阵形式,矩阵的大小为n×K,n为样本的数量。
logLikelihoods表示可选的输出矩阵,该矩阵包含每个样本的对数似然值,矩阵的大小为n×1,数据类型为CV_64FC1。
labels表示可选的输出变量,表示最终的每个样本的类别标签,即它最有可能属于的那个高斯成分的索引值,公式的表达形式为:labelsi= argmaxk p(k|xi,θ(t)),它是n×1的CV_32C1形式。
probs表示可选的输出矩阵,该矩阵为最终结果的后验概率p(k|xi, θ(t)),它是n×K的CV_32C1形式。
下面我们就分别给出这三个函数:
bool EM::trainE(InputArray samples,
InputArray _means0,
InputArray _covs0,
InputArray _weights0,
OutputArray logLikelihoods,
OutputArray labels,
OutputArray probs)
{
Mat samplesMat = samples.getMat(); //得到样本数据
vector<Mat> covs0; //协方差矩阵
_covs0.getMatVector(covs0);
//均值和权值因子
Mat means0 = _means0.getMat(), weights0 = _weights0.getMat();
//设置均值、权值因子、和协方差矩阵
setTrainData(START_E_STEP, samplesMat, 0, !_means0.empty() ? &means0 : 0,
!_covs0.empty() ? &covs0 : 0, !_weights0.empty() ? &weights0 : 0);
return doTrain(START_E_STEP, logLikelihoods, labels, probs); //进入EM算法
}
bool EM::trainM(InputArray samples,
InputArray _probs0,
OutputArray logLikelihoods,
OutputArray labels,
OutputArray probs)
{
Mat samplesMat = samples.getMat(); //得到样本数据
Mat probs0 = _probs0.getMat(); //得到后验概率
//设置后验概率
setTrainData(START_M_STEP, samplesMat, !_probs0.empty() ? &probs0 : 0, 0, 0, 0);
return doTrain(START_M_STEP, logLikelihoods, labels, probs); //进入EM算法
}
我们重点讲解train函数:
bool EM::train(InputArray samples,
OutputArray logLikelihoods,
OutputArray labels,
OutputArray probs)
{
Mat samplesMat = samples.getMat(); //得到样本矩阵
//调用setTrainData函数,设置训练用的数据,该函数在后面给出详细解释
//在train函数调用setTrainData函数,要设置第一个参数为START_AUTO_STEP,第二个参数为输入的样本矩阵,后四个参数probs0,means0,covs0和weights0,由于这四个参数在doTrain函数中是用k-means算法得到的,所以无需初始化,即设它们为0
setTrainData(START_AUTO_STEP, samplesMat, 0, 0, 0, 0);
//调用doTrain函数,进入EM算法的迭代过程中,该函数在后面给出详细解释
//doTrain函数的第一个参数的含义与前一个setTrainData函数相同
return doTrain(START_AUTO_STEP, logLikelihoods, labels, probs);
}
设置训练样本数据:
void EM::setTrainData(int startStep, const Mat& samples,
const Mat* probs0,
const Mat* means0,
const vector<Mat>* covs0,
const Mat* weights0)
//startStep表示EM算法迭代是从E-Step和M-Step中的哪一步开始迭代,该参数用于区分是train函数,trainE函数还是trainM函数调用的它,如果是train函数调用的它,则该参数为START_AUTO_STEP,如果是trainE函数调用的它,则该参数为EM::START_E_STEP,如果是trainM函数调用的它,则该参数为EM::START_M_STEP
//samples表示输入的样本
//probs0,means0,covs0和weights0分别为初始化的后验概率p(k|xi, θ(0)),均值μk,协方差矩阵∑k和权值因子αk
{
clear(); //清空一些全局变量
//检查样本数据和初始化参数是否正确
checkTrainData(startStep, samples, nclusters, covMatType, probs0, means0, covs0, weights0);
//当startStep为START_AUTO_STEP,或者startStep为START_E_STEP并且没有初始化covs0或weights0时,isKMeansInit置1,表示需要用到k-means算法估计相应的初始化参数
bool isKMeansInit = (startStep == EM::START_AUTO_STEP) || (startStep == EM::START_E_STEP && (covs0 == 0 || weights0 == 0));
// Set checked data
//把samples复制为trainSamples,并根据isKMeansInit设置trainSamples的数据类型
preprocessSampleData(samples, trainSamples, isKMeansInit ? CV_32FC1 : CV_64FC1, false);
// set probs
//当初始化了probs0,并且startStep为EM::START_M_STEP时,需要设置probs参数
if(probs0 && startStep == EM::START_M_STEP)
{
//把probs0复制为trainProbs,并使trainProbs的数据类型为CV_64FC1
preprocessSampleData(*probs0, trainProbs, CV_64FC1, true);
//预处理初始化的后验概率值,使其归一化
preprocessProbability(trainProbs);
}
// set weights
//当初始化了weights0,并且startStep为EM::START_E_STEP且初始化了covs0时,需要设置weights0参数
if(weights0 && (startStep == EM::START_E_STEP && covs0))
{
//转换数据类型为CV_64FC1
weights0->convertTo(weights, CV_64FC1);
//把矩阵weights转换为1×K的形式
weights.reshape(1,1);
//预处理初始化的权值因子,使其归一化
preprocessProbability(weights);
}
// set means
//当初始化了means0,并且startStep为EM::START_E_STEP时,把means0复制为means,并根据isKMeansInit设置means的数据类型
if(means0 && (startStep == EM::START_E_STEP/* || startStep == EM::START_AUTO_STEP*/))
means0->convertTo(means, isKMeansInit ? CV_32FC1 : CV_64FC1);
// set covs
//当初始化了covs0,并且startStep为EM::START_E_STEP且初始化了weights0时,需要设置covs
if(covs0 && (startStep == EM::START_E_STEP && weights0))
{
//covs为全局变量,被定义为vector<Mat>类型,用于表示不同高斯成分的协方差矩阵的向量集,即K×d×d
covs.resize(nclusters); //设置covs的向量大小为K
//复制,并且转换数据类型为CV_64FC1
for(size_t i = 0; i < covs0->size(); i++)
(*covs0)[i].convertTo(covs[i], CV_64FC1);
}
}
执行EM算法迭代:
bool EM::doTrain(int startStep, OutputArray logLikelihoods, OutputArray labels, OutputArray probs)
//startStep表示EM算法迭代是从E-Step和M-Step中的哪一步开始迭代,该参数用于区分是train函数,trainE函数还是trainM函数调用的它,如果是train函数调用的它,则该参数为START_AUTO_STEP,如果是trainE函数调用的它,则该参数为EM::START_E_STEP,如果是trainM函数调用的它,则该参数为EM::START_M_STEP
//logLikelihoods,labels,和probs分别为训练结束后输出得到的对数似然函数,类别标签和后验概率
{
int dim = trainSamples.cols; //得到样本特征属性的数量
// Precompute the empty initial train data in the cases of EM::START_E_STEP and START_AUTO_STEP
//如果为EM::START_E_STEP或START_AUTO_STEP,并且在没有定义协方差矩阵的情况下,所需的初始化参数可以由k-means算法估计得到
if(startStep != EM::START_M_STEP)
{
//确保在没有给出协方差矩阵covs的情况下,调用clusterTrainSamples函数,进行相关参数的k-means算法估计
if(covs.empty())
{
CV_Assert(weights.empty()); //确保weights有值
clusterTrainSamples(); //该函数在后面给出详细的介绍
}
}
//在前面的clusterTrainSamples函数内,会调用decomposeCovs函数,下面if语句的作用是在前面没有执行clusterTrainSamples函数的情况下,调用decomposeCovs函数,也就是保证decomposeCovs函数一定要被调用一次,且只能是一次
if(!covs.empty() && covsEigenValues.empty() )
{
CV_Assert(invCovsEigenValues.empty());
decomposeCovs(); //该函数在后面给出详细的介绍
}
//如果是EM::START_M_STEP,需要先执行一次M-Step,由p(k|xi, θ(0))得到αk(1),μk(1)和∑k(1),
if(startStep == EM::START_M_STEP)
mStep(); //该函数在后面给出详细的介绍
// trainLogLikelihood和prevTrainLogLikelihood分别表示对数似然函数值和前一次迭代的对数似然函数值
double trainLogLikelihood, prevTrainLogLikelihood = 0.;
for(int iter = 0; ; iter++) //进入EM算法的迭代
{
eStep(); //执行E-Step,该函数在后面给出详细的介绍
//得到该次迭代后的对数似然函数值
trainLogLikelihood = sum(trainLogLikelihoods)[0];
//如果超出了最大迭代次数,则退出EM算法的迭代
if(iter >= maxIters - 1)
break;
//计算前后两次的对数似然函数值的差
double trainLogLikelihoodDelta = trainLogLikelihood - prevTrainLogLikelihood;
//如果这个差值太小,说明已收敛,则退出EM迭代
if( iter != 0 &&
(trainLogLikelihoodDelta < -DBL_EPSILON ||
trainLogLikelihoodDelta < epsilon * std::fabs(trainLogLikelihood)))
break;
mStep(); //执行M-Step,该函数在后面给出详细的介绍
prevTrainLogLikelihood = trainLogLikelihood; //更新上一次对数似然函数值
}
//如果对数似然函数是一个比较大的负数,说明EM算法计算不对,则退出函数
if( trainLogLikelihood <= -DBL_MAX/10000. )
{
clear();
return false;
}
// postprocess covs
//后处理协方差矩阵,因为对于EM::COV_MAT_SPHERICAL和EM::COV_MAT_DIAGONAL类型,我们并没有真正得到协方差矩阵,而仅仅得到了它们的特征值,现在我们需要从特征值还原回协方差矩阵,它们的协方差矩阵都是对角线矩阵
covs.resize(nclusters); //定义大小
for(int clusterIndex = 0; clusterIndex < nclusters; clusterIndex++) //遍历高斯成分
{
//EM::COV_MAT_SPHERICAL类型
if(covMatType == EM::COV_MAT_SPHERICAL)
{
covs[clusterIndex].create(dim, dim, CV_64FC1); //定义大小
//设置单位矩阵,即sk×I,sk为covsEigenValues[clusterIndex].at<double>(0)
setIdentity(covs[clusterIndex], Scalar(covsEigenValues[clusterIndex].at<double>(0)));
}
//EM::COV_MAT_DIAGONAL类型
else if(covMatType == EM::COV_MAT_DIAGONAL)
{
//设置对角线矩阵,对角线上的元素为特征值
covs[clusterIndex] = Mat::diag(covsEigenValues[clusterIndex]);
}
}
//如果我们需要EM算法迭代后的类别标签、后验概率、对数似然函数,则复制相应的值
if(labels.needed())
trainLabels.copyTo(labels);
if(probs.needed())
trainProbs.copyTo(probs);
if(logLikelihoods.needed())
trainLogLikelihoods.copyTo(logLikelihoods);
//释放内存
trainSamples.release();
trainProbs.release();
trainLabels.release();
trainLogLikelihoods.release();
return true; //返回
}
执行k-means算法的参数估计:
void EM::clusterTrainSamples()
{
int nsamples = trainSamples.rows; //得到样本的数量
// Cluster samples, compute/update means
// Convert samples and means to 32F, because kmeans requires this type.
//把样本和均值的数据类型转换为32F型
Mat trainSamplesFlt, meansFlt;
if(trainSamples.type() != CV_32FC1)
trainSamples.convertTo(trainSamplesFlt, CV_32FC1);
else
trainSamplesFlt = trainSamples;
if(!means.empty())
{
if(means.type() != CV_32FC1)
means.convertTo(meansFlt, CV_32FC1);
else
meansFlt = means;
}
Mat labels; //表示样本的分类标签
//调用kmeans函数,执行k-means算法
kmeans(trainSamplesFlt, nclusters, labels, TermCriteria(TermCriteria::COUNT, means.empty() ? 10 : 1, 0.5), 10, KMEANS_PP_CENTERS, meansFlt);
// Convert samples and means back to 64F.
//再次把样本和均值的数据类型转换回64F型
CV_Assert(meansFlt.type() == CV_32FC1);
if(trainSamples.type() != CV_64FC1)
{
Mat trainSamplesBuffer;
trainSamplesFlt.convertTo(trainSamplesBuffer, CV_64FC1);
trainSamples = trainSamplesBuffer;
}
meansFlt.convertTo(means, CV_64FC1);
// Compute weights and covs
//定义权值因子weights的矩阵形式,大小为1×K,数据类型为CV_64FC1,初始化为0
weights = Mat(1, nclusters, CV_64FC1, Scalar(0));
covs.resize(nclusters); //covs的向量大小为K
for(int clusterIndex = 0; clusterIndex < nclusters; clusterIndex++) //遍历所有高斯成分
{
Mat clusterSamples; //表示某一高斯成分的样本
//遍历所有样本,对样本进行分类
for(int sampleIndex = 0; sampleIndex < nsamples; sampleIndex++)
{
//如果当前样本属于当前的高斯成分
if(labels.at<int>(sampleIndex) == clusterIndex)
{
const Mat sample = trainSamples.row(sampleIndex); //提取当前样本数据
clusterSamples.push_back(sample); //把当前样本放入clusterSamples中
}
}
CV_Assert(!clusterSamples.empty()); //确保当前高斯成分中有样本
//调用calcCovarMatrix函数,计算当前高斯成分的协方差矩阵和均值
calcCovarMatrix(clusterSamples, covs[clusterIndex], means.row(clusterIndex),
CV_COVAR_NORMAL + CV_COVAR_ROWS + CV_COVAR_USE_AVG + CV_COVAR_SCALE, CV_64FC1);
//计算当前高斯成分的权值因子,等于当前高斯成分的样本数除以全部样本数
weights.at<double>(clusterIndex) = static_cast<double>(clusterSamples.rows)/static_cast<double>(nsamples);
}
//奇异值分解协方差矩阵,该函数在后面给出详细的介绍
decomposeCovs();
}
奇异值分解协方差矩阵,得到特征值,和特征向量:
void EM::decomposeCovs()
{
//covs为全局变量,数据类型为vector<Mat>,表示不同高斯成分的协方差矩阵的向量集,
CV_Assert(!covs.empty()); //确保covs不能为空
//covsEigenValues为全局变量,数据类型为vector<Mat>,表示不同高斯成分的协方差矩阵的特征值矩阵(即式84中的W)的向量集,定义该向量集的大小为K
covsEigenValues.resize(nclusters);
//如果covMatType为EM::COV_MAT_GENERIC,则协方差矩阵的奇异值分解是用式84,它需要特征向量矩阵U
if(covMatType == EM::COV_MAT_GENERIC)
// covsRotateMats为全局变量,数据类型为vector<Mat>,表示不同高斯成分的协方差矩阵的特征向量矩阵的向量集,定义该向量集的大小为K
covsRotateMats.resize(nclusters);
//invCovsEigenValues为全局变量,数据类型为vector<Mat>,表示covsEigenValues的逆矩阵(即式85中的W-1)的向量集,定义该向量集的大小为K
invCovsEigenValues.resize(nclusters);
//遍历所有的高斯成分,计算每个高斯成分中协方差矩阵的特征值和特征向量
for(int clusterIndex = 0; clusterIndex < nclusters; clusterIndex++)
{
CV_Assert(!covs[clusterIndex].empty()); //确保当前高斯成分的协方差矩阵有值
//执行SVD类,对当前高斯成分的协方差矩阵进行奇异值分解
SVD svd(covs[clusterIndex], SVD::MODIFY_A + SVD::FULL_UV);
//如果covMatType为EM::COV_MAT_SPHERICAL
if(covMatType == EM::COV_MAT_SPHERICAL)
{
//得到协方差矩阵的最大特征值
double maxSingularVal = svd.w.at<double>(0);
//在COV_MAT_SPHERICAL下,covsEigenValues大小为K×1×1,covsEigenValues[clusterIndex]存储最大特征值,即COV_MAT_SPHERICAL所需的标量sk
covsEigenValues[clusterIndex] = Mat(1, 1, CV_64FC1, Scalar(maxSingularVal));
}
//如果covMatType为EM:: COV_MAT_DIAGONAL
else if(covMatType == EM::COV_MAT_DIAGONAL)
{
covsEigenValues[clusterIndex] = svd.w; //协方差矩阵的特征值矩阵
}
//如果covMatType为EM::COV_MAT_GENERIC
else //EM::COV_MAT_GENERIC
{
covsEigenValues[clusterIndex] = svd.w; //协方差矩阵的特征值矩阵
covsRotateMats[clusterIndex] = svd.u; //协方差矩阵的特征向量矩阵
}
//该语句的作用是避免特征值过小
max(covsEigenValues[clusterIndex], minEigenValue, covsEigenValues[clusterIndex]);
//得到invCovsEigenValues
invCovsEigenValues[clusterIndex] = 1./covsEigenValues[clusterIndex];
}
}
执行EM算法的E-Step,由αk(t),μk(t)和∑k(t),得到p(k|xi,θ(t)):
void EM::eStep()
{
// Compute probs_ik from means_k, covs_k and weights_k.
//创建trainProbs,trainLabels和trainLogLikelihoods的大小,分别为n×K,n×1,n×1,它们的含义分别为训练过程中得到后验概率、样本的类别标签和对数似然函数
trainProbs.create(trainSamples.rows, nclusters, CV_64FC1);
trainLabels.create(trainSamples.rows, 1, CV_32SC1);
trainLogLikelihoods.create(trainSamples.rows, 1, CV_64FC1);
//得到式83中的lnαk-ln(|∑k|)/2,该函数在后面给出详细的介绍
computeLogWeightDivDet();
//确保trainSamples和means的数据类型为CV_64FC1
CV_DbgAssert(trainSamples.type() == CV_64FC1);
CV_DbgAssert(means.type() == CV_64FC1);
//遍历所有样本
for(int sampleIndex = 0; sampleIndex < trainSamples.rows; sampleIndex++)
{
//定义当前样本的后验概率,并指向trainProbs的相应位置
Mat sampleProbs = trainProbs.row(sampleIndex);
//调用computeProbabilities函数,计算后验概率,该函数在后面给出了详细介绍
Vec2d res = computeProbabilities(trainSamples.row(sampleIndex), &sampleProbs);
//得到当前样本的对数似然函数
trainLogLikelihoods.at<double>(sampleIndex) = res[0];
//得到最大后验概率所对应的类别标签
trainLabels.at<int>(sampleIndex) = static_cast<int>(res[1]);
}
}
执行EM算法的M-Step,由p(k|xi, θ(t))得到αk(t+1),μk(t+1)和∑k(t+1):
void EM::mStep()
{
// Update means_k, covs_k and weights_k from probs_ik
int dim = trainSamples.cols; //得到特征属性的数量d
// Update weights
// not normalized first
//得到权值因子,式66,但这里得到weights并没有按照式66那样还除以n
//该语句的作用是把矩阵trainProbs简化为相量weights,weights的值为矩阵trainProbs每行求和的结果,即式66中∑求和的部分
reduce(trainProbs, weights, 0, CV_REDUCE_SUM);
// Update means
//重新创建means变量,大小为K×d的矩阵,数据类型为CV_64FC1
means.create(nclusters, dim, CV_64FC1);
means = Scalar(0); //初始化为0
const double minPosWeight = trainSamples.rows * DBL_EPSILON; //得到一个很小的值
double minWeight = DBL_MAX; //一个很大的值
int minWeightClusterIndex = -1;
for(int clusterIndex = 0; clusterIndex < nclusters; clusterIndex++) //遍历所有高斯成分
{
//如果式67中分母的值太小,则继续下一个高斯成分的计算
if(weights.at<double>(clusterIndex) <= minPosWeight)
continue;
//如果式67中分母的值小于某个很大的值
if(weights.at<double>(clusterIndex) < minWeight)
{
minWeight = weights.at<double>(clusterIndex); //得到式67中分母
minWeightClusterIndex = clusterIndex; //记录下当前高斯成分的索引
}
Mat clusterMean = means.row(clusterIndex); //指向均值矩阵的地址指针
//遍历所有样本
for(int sampleIndex = 0; sampleIndex < trainSamples.rows; sampleIndex++)
clusterMean += trainProbs.at<double>(sampleIndex, clusterIndex) * trainSamples.row(sampleIndex); //得到式67的分子部分
clusterMean /= weights.at<double>(clusterIndex); //式67
}
// Update covsEigenValues and invCovsEigenValues
//计算协方差
//定义covs的大小为K×1,它表示协方差矩阵
covs.resize(nclusters);
//定义covsEigenValues的大小为K,它表示协方差矩阵的特征值
covsEigenValues.resize(nclusters);
// EM::COV_MAT_GENERIC类型需要covsRotateMats,它表示特征向量矩阵
if(covMatType == EM::COV_MAT_GENERIC)
covsRotateMats.resize(nclusters); //定义大小为K
//定义invCovsEigenValues的大小为K,它表示协方差矩阵的特征值的倒数
invCovsEigenValues.resize(nclusters);
//遍历所有的高斯成分
for(int clusterIndex = 0; clusterIndex < nclusters; clusterIndex++)
{
//如果式68的分母太小,则继续下一个高斯成分的计算
if(weights.at<double>(clusterIndex) <= minPosWeight)
continue;
//得到当前高斯成分的协方差矩阵的特征值
if(covMatType != EM::COV_MAT_SPHERICAL)
covsEigenValues[clusterIndex].create(1, dim, CV_64FC1);
else
covsEigenValues[clusterIndex].create(1, 1, CV_64FC1);
//如果为EM::COV_MAT_GENERIC类型,则定义covs[clusterIndex]的大小为d×d
if(covMatType == EM::COV_MAT_GENERIC)
covs[clusterIndex].create(dim, dim, CV_64FC1);
// clusterCov代表当前高斯成分的协方差矩阵,根据不同的类型,clusterCov矩阵指针被指向不同的矩阵首地址,因为如果不是EM::COV_MAT_GENERIC类型,则协方差矩阵仅仅是对角线矩阵,它的计算要简单一些
//在计算后验概率时,如果协方差是对角线矩阵时,由式88可知,我们只需要知道协方差矩阵的特征值即可,所以当不是EM::COV_MAT_GENERIC类型时,其实clusterCov表示的是协方差矩阵的特征值
Mat clusterCov = covMatType != EM::COV_MAT_GENERIC ?
covsEigenValues[clusterIndex] : covs[clusterIndex];
clusterCov = Scalar(0); //初始化为0
Mat centeredSample; //表示式68的xi-μk
//遍历所有的样本
for(int sampleIndex = 0; sampleIndex < trainSamples.rows; sampleIndex++)
{
//计算xi-μk
centeredSample = trainSamples.row(sampleIndex) - means.row(clusterIndex);
//计算式68的分子部分
//如果是EM::COV_MAT_GENERIC类型,直接按照公式计算即可
if(covMatType == EM::COV_MAT_GENERIC)
clusterCov += trainProbs.at<double>(sampleIndex, clusterIndex) * centeredSample.t() * centeredSample;
//如果是EM::COV_MAT_SPHERICAL或EM::COV_MAT_DIAGONAL类型
else
{
//p为当前样本下当前高斯成分的后验概率,即求p(k|xi, θ)
double p = trainProbs.at<double>(sampleIndex, clusterIndex);
for(int di = 0; di < dim; di++ ) //遍历所有的特征属性
{
//val为xi-μk向量下,第di个元素的值
double val = centeredSample.at<double>(di);
//只需计算矩阵对角线上的元素即可
clusterCov.at<double>(covMatType != EM::COV_MAT_SPHERICAL ? di : 0) += p*val*val;
}
}
}
//如果是EM::COV_MAT_SPHERICAL类型,特征值需要除以d
if(covMatType == EM::COV_MAT_SPHERICAL)
clusterCov /= dim;
//如果是EM::COV_MAT_SPHERICAL或EM::COV_MAT_DIAGONAL类型,clusterCov为协方差矩阵的特征值,如果是EM::COV_MAT_GENERIC,clusterCov为协方差矩阵
clusterCov /= weights.at<double>(clusterIndex); //式68的结果
// Update covsRotateMats for EM::COV_MAT_GENERIC only
//如果是EM::COV_MAT_GENERIC类型,还需要对协方差矩阵进行奇异值分解,得到特征值和特征向量,因为在计算后验概率时,我们用到的是这两个变量
if(covMatType == EM::COV_MAT_GENERIC)
{
SVD svd(covs[clusterIndex], SVD::MODIFY_A + SVD::FULL_UV); //奇异值分解
covsEigenValues[clusterIndex] = svd.w; //特征值
covsRotateMats[clusterIndex] = svd.u; //特征向量
}
//防止协方差矩阵的特征值(covsEigenValues)过小
max(covsEigenValues[clusterIndex], minEigenValue, covsEigenValues[clusterIndex]);
// update invCovsEigenValues
//得到协方差矩阵特征值的倒数
invCovsEigenValues[clusterIndex] = 1./covsEigenValues[clusterIndex];
}
//遍历所有的高斯成分
for(int clusterIndex = 0; clusterIndex < nclusters; clusterIndex++)
{
//在前面计算均值和协方差时,没有考虑权值因子很小这种情况,下面就来计算这种情况下的相应值
if(weights.at<double>(clusterIndex) <= minPosWeight)
{
//clusterMean指向当前高斯成分的均值向量
Mat clusterMean = means.row(clusterIndex);
//用第minWeightClusterIndex个高斯成分的均值、协方差矩阵、特征值、特征向量和特征值的倒数代替这种情况下的均值、协方差矩阵、特征值、特征向量和特征值的倒数
means.row(minWeightClusterIndex).copyTo(clusterMean);
covs[minWeightClusterIndex].copyTo(covs[clusterIndex]);
covsEigenValues[minWeightClusterIndex].copyTo(covsEigenValues[clusterIndex]);
if(covMatType == EM::COV_MAT_GENERIC)
covsRotateMats[minWeightClusterIndex].copyTo(covsRotateMats[clusterIndex]);
invCovsEigenValues[minWeightClusterIndex].copyTo(invCovsEigenValues[clusterIndex]);
}
}
// Normalize weights
//前面计算的权值因子(式66)没有除以n,因为前面会反复用到没有除以n的权值因子,现在除以n
weights /= trainSamples.rows;
}
计算式83中的lnαk-ln(|∑k|)/2:
void EM::computeLogWeightDivDet()
{
CV_Assert(!covsEigenValues.empty()); //确保covsEigenValues有值
Mat logWeights; //表示权值因子的对数
cv::max(weights, DBL_MIN, weights); //确保权值因子不能过小
log(weights, logWeights); //得到权值因子的对数,即lnαk
//logWeightDivDet为全局变量,数据类型为Mat,定义该变量的大小为1×K
//logWeightDivDet=lnαk-ln(|∑k|)/2
logWeightDivDet.create(1, nclusters, CV_64FC1);
// note: logWeightDivDet = log(weight_k) - 0.5 * log(|det(cov_k)|)
//遍历所有的高斯成分
for(int clusterIndex = 0; clusterIndex < nclusters; clusterIndex++)
{
double logDetCov = 0.; //表示ln(|∑k|)
//得到当前高斯成分的协方差矩阵的特征值的总数
const int evalCount = static_cast<int>(covsEigenValues[clusterIndex].total());
//计算ln(|∑k|),即式88再取对数ln(|∑k|)=∑iln(wi)
for(int di = 0; di < evalCount; di++)
logDetCov += std::log(covsEigenValues[clusterIndex].at<double>(covMatType != EM::COV_MAT_SPHERICAL ? di : 0));
//计算logWeightDivDet,即lnαk-ln(|∑k|)/2
logWeightDivDet.at<double>(clusterIndex) = logWeights.at<double>(clusterIndex) - 0.5 * logDetCov;
}
}
计算训练过程中,每次迭代以后的每个样本的后验概率,即式69,在预测时,也调用了该函数:
Vec2d EM::computeProbabilities(const Mat& sample, Mat* probs) const
//sample表示需要计算的后验概率的样本
//probs表示样本sample的后验概率
//该函数返回含两个值的相量,一个是该次迭代后样本sample的对数似然函数值,另一个是最大后验概率所对应的类别标签,即最有可能属于的高斯成分的索引
{
// L_ik = log(weight_k) - 0.5 * log(|det(cov_k)|) - 0.5 *(x_i - mean_k)' cov_k^(-1) (x_i - mean_k)]
// q = arg(max_k(L_ik))
// probs_ik = exp(L_ik - L_iq) / (1 + sum_j!=q (exp(L_ij - L_iq))
// see Alex Smola's blog http://blog.smola.org/page/2 for
// details on the log-sum-exp trick
//确保means和sample变量的相关类型的正确
CV_Assert(!means.empty());
CV_Assert(sample.type() == CV_64FC1);
CV_Assert(sample.rows == 1);
CV_Assert(sample.cols == means.cols);
int dim = sample.cols; //得到特征属性的数量
//定义矩阵L,大小为1×K,该变量表示式83的LN’k
Mat L(1, nclusters, CV_64FC1);
//label表示当前样本的所有高斯成分中,LN’k最大值所对应的类别标签
int label = 0;
//遍历所有的高斯成分
for(int clusterIndex = 0; clusterIndex < nclusters; clusterIndex++)
{
//计算xi-μk,即式86中的D
const Mat centeredSample = sample - means.row(clusterIndex);
//如果是EM::COV_MAT_GENERIC类型,则应用式86,即rotatedCenteredSample等于DUT;如果是其他类型,则应用式88,即rotatedCenteredSample就等于D
Mat rotatedCenteredSample = covMatType != EM::COV_MAT_GENERIC ?
centeredSample : centeredSample * covsRotateMats[clusterIndex];
//Lval表示(x-μk)T∑k-1(x-μk)
double Lval = 0;
for(int di = 0; di < dim; di++) //遍历所有的特征属性
{
//得到当前特征属性的协方差矩阵的特征值的倒数,即式87的1/wi
double w = invCovsEigenValues[clusterIndex].at<double>(covMatType != EM::COV_MAT_SPHERICAL ? di : 0);
double val = rotatedCenteredSample.at<double>(di); //表示式87中ai
Lval += w * val * val; //式87
}
CV_DbgAssert(!logWeightDivDet.empty()); //确保logWeightDivDet有值
//式83
L.at<double>(clusterIndex) = logWeightDivDet.at<double>(clusterIndex) - 0.5 * Lval;
//得到最大值的LN’k的类别标签
if(L.at<double>(clusterIndex) > L.at<double>(label))
label = clusterIndex;
}
//得到最大值LN’k值,即“log-sum-exp”技巧中的c(式75)
double maxLVal = L.at<double>(label);
//定义expL_Lmax,大小与L相同,它表示式77
Mat expL_Lmax = L; // exp(L_ij - L_iq)
//遍历所有高斯成分,计算式77
for(int i = 0; i < L.cols; i++)
expL_Lmax.at<double>(i) = std::exp(L.at<double>(i) - maxLVal);
//得到式78
double expDiffSum = sum(expL_Lmax)[0]; // sum_j(exp(L_ij - L_iq))
//计算后验概率
if(probs)
{
probs->create(1, nclusters, CV_64FC1); //定义probs的大小,为1×K
double factor = 1./expDiffSum; //式81的分母
expL_Lmax *= factor; //计算式81,最终得到当前样本的后验概率
expL_Lmax.copyTo(*probs); //复制
}
Vec2d res; //函数返回值变量
//式71,但这里还含有“log-sum-exp”技巧
res[0] = std::log(expDiffSum) + maxLVal - 0.5 * dim * CV_LOG2PI;
res[1] = label; //最大后验概率所对应的类别标签
return res; //函数返回值
}
EM算法的训练过程就介绍到这里,下面是EM算法的预测,它可以得到预测样本的后验概率,对数似然值,以及它最有可能属于的高斯成分的索引。
Vec2d EM::predict(InputArray _sample, OutputArray _probs) const
//_sample表示待预测的一个样本,它必须是单通道的1×d或d×1的矩阵
//_probs表示得到的预测样本的后验概率
//该函数返回一个包含两个元素的向量,第一个元素是预测样本的对数似然值,第二个元素是预测样本最有可能属于的高斯成分的索引
{
Mat sample = _sample.getMat(); //得到预测样本数据
CV_Assert(isTrained()); //确保在预测前已完成了EM算法
CV_Assert(!sample.empty()); //确保预测样本有值
//使预测样本的数据类型为CV_64FC1
if(sample.type() != CV_64FC1)
{
Mat tmp;
sample.convertTo(tmp, CV_64FC1);
sample = tmp;
}
sample.reshape(1, 1); //使样本为单通道,1×d的形式
Mat probs; //表示样本的后验概率
//如果需要计算后验概率,则设置正确的格式
if( _probs.needed() )
{
_probs.create(1, nclusters, CV_64FC1);
probs = _probs.getMat();
}
//调用computeProbabilities函数,得到后验概率,对数似然值和索引值
return computeProbabilities(sample, !probs.empty() ? &probs : 0);
}
三、应用实例
EM是一种无监督的机器学习方法,它还可以用于聚类处理上。下面的应用实例是用EM算法对图像进行分割,它只是对图像数据进行聚类计算,而无需对新的数据进行预测。对于三通道的彩色图像而言,每个像素就是一个样本数据,而每个样本包括三个特征属性,也就是红、绿、蓝三个通道的强度值。
#include "opencv2/core/core.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/legacy/legacy.hpp"
#include <iostream>
using namespace cv;
using namespace std;
int main( int argc, char** argv )
{
Mat src = imread("MyDaughter.jpg"); //读取图像
namedWindow( "my daughter", WINDOW_AUTOSIZE );
imshow( "my daughter", src); //显示原始图像
//data为样本数据,labels为样本数据的类别标签
Mat data, labels;
//由彩色图像转换为EM算法所需的样本数据
for (int i = 0; i < src.rows; i++)
{
for (int j = 0; j < src.cols; j++)
{
Vec3b point = src.at<Vec3b>(i, j); //提取出当前像素的彩色值
//三个颜色强度值转换为一个样本数据
Mat tmp = (Mat_<float>(1, 3) << point[0], point[1], point[2]);
data.push_back(tmp); //存储当前样本
}
}
int clusters = 4; //表示要分割的数量,即一共分4个类
EM em = EM(clusters); //实例化EM
//训练样本,得到样本的类别标签labels
em.train(data, noArray(), labels, noArray());
//不同的类用不同的颜色代替
Vec3b colorTab[] =
{
Vec3b(0, 0, 255),
Vec3b(0, 255, 0),
Vec3b(255, 100, 100),
Vec3b(255, 0, 255),
Vec3b(0, 255, 255)
};
int n = 0; //样本数据的索引
for (int i = 0; i < src.rows; i++)
{
for (int j = 0; j < src.cols; j++)
{
int clusterIdx = labels.at<int>(n); //得到当前像素的类别标签
src.at<Vec3b>(i, j) = colorTab[clusterIdx]; //赋上相应的颜色值
n++;
}
}
namedWindow( "EM", WINDOW_AUTOSIZE );
imshow( "EM", src); //显示分割结果
waitKey(0);
return 0;
}

原图
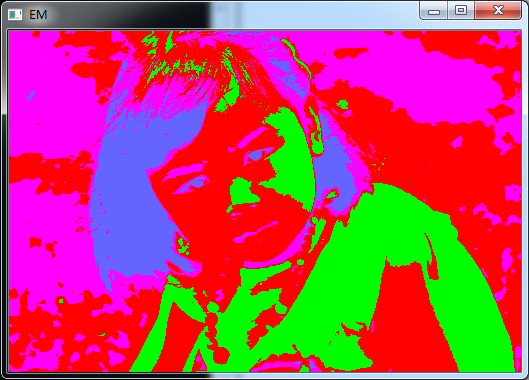
分割结果
需要说明的是,在i5-4690k处理器、16G内存、64位win7环境下,这幅图像EM分割共用时4分钟。