欢迎访问我的主页
本案例为通过csv文件中数据集,使用决策树方法对蘑菇是否有毒进行预测。
数据集网盘链接:https://pan.baidu.com/s/1AZR4EKFYjqsJ3hoTo34rTQ
提取码:v1oo
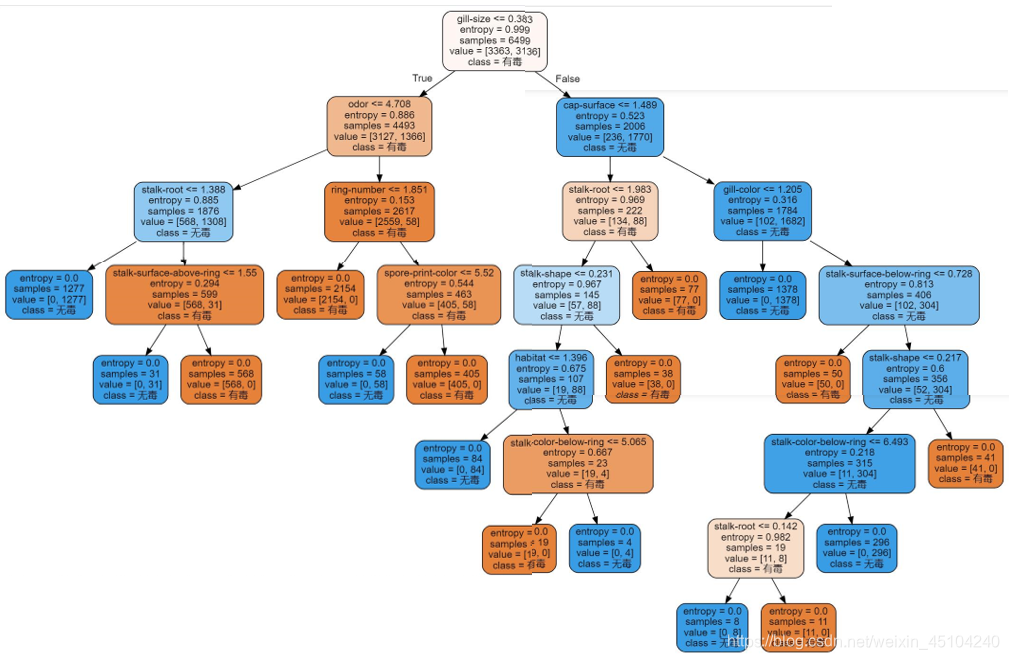
最终实现的树模型:
#导入相关库
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
#数据
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split #切分数据集,训练集和测试集
#导入CSV数据(关于蘑菇的各项特征数据表)
import csv
import pandas as pd
dpath = 'data/'
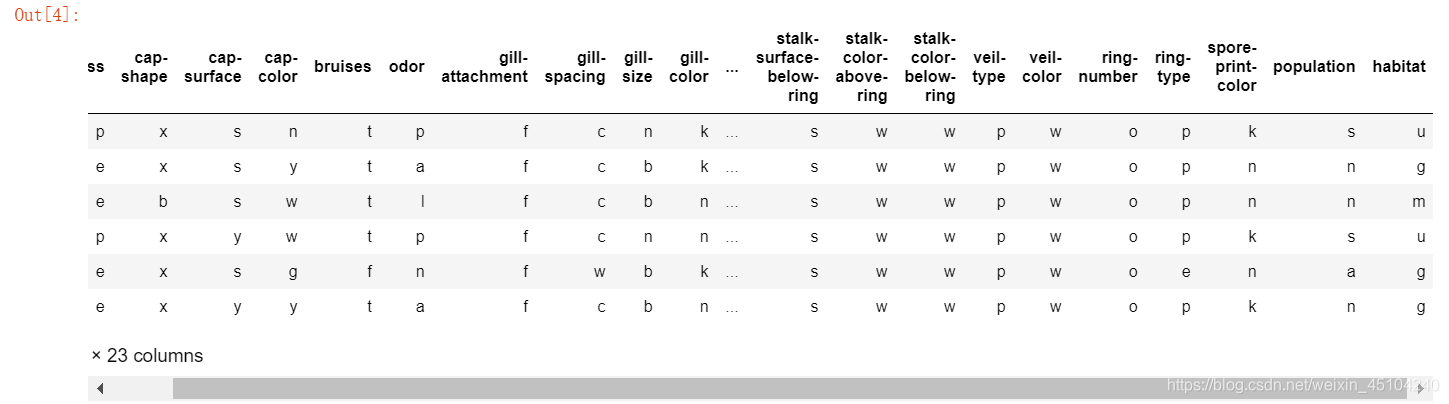
data = pd.read_csv("mushrooms.csv")
data.head(6)
wine=load_wine()
print(type(wine)) #--------------<class 'sklearn.utils.Bunch'>
wine
data.isnull().sum()#缺失值

data['class'].unique() #p有毒 e无毒
#unique的作用是从输入序列中“删除”所有相邻的重复元素
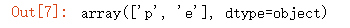
data.dtypes

from sklearn.preprocessing import LabelEncoder
labelencoder=LabelEncoder()
for col in data.columns:
data[col] = labelencoder.fit_transform(data[col])
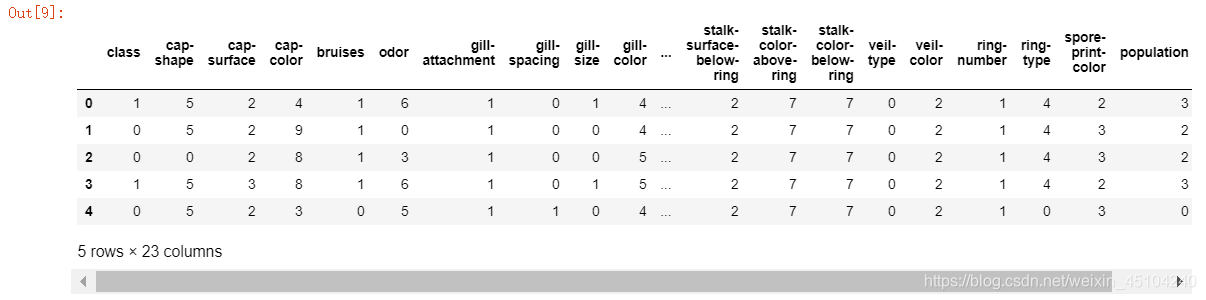
data.head()#-----------<class 'pandas.core.frame.DataFrame'>
X = data.iloc[:,1:23] # 所有行、所有功能和无标签
y = data.iloc[:,0] # 所有行,仅标签
X.head()
y.head()

#将数据剪切成训练和测试数据集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=4)
X_train.shape
# X_test.shape
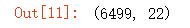
clf=tree.DecisionTreeClassifier(criterion='entropy')
clf=clf.fit(X_train,y_train)
score=clf.score(X_test,y_test)
score

clf.feature_importances_ #

data.dtypes
print(type(data.dtypes))
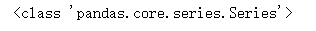
# data.dtypes
feature_name=['cap-shape','cap-surface','cap-color','bruises','odor','gill-attachment','gill-spacing','gill-size','gill-color','stalk-shape'
,'stalk-root','stalk-surface-above-ring','stalk-surface-below-ring','stalk-color-above-ring','stalk-color-below-ring','veil-type'
,'veil-color','ring-number','ring-type','spore-print-color','population','habitat']
print(len(feature_name))
# feature_name=[]
# for i in range(len(data.dtypes)):
# feature_name.append()
[*zip(feature_name,clf.feature_importances_)]
clf=tree.DecisionTreeClassifier(criterion='entropy',random_state=30)
clf=clf.fit(X_train,y_train)
score=clf.score(X_test,y_test)
score
clf=tree.DecisionTreeClassifier(criterion='entropy' #优化!
,random_state=30
,splitter='random')
clf=clf.fit(X_train,y_train)
score=clf.score(X_test,y_test)
score
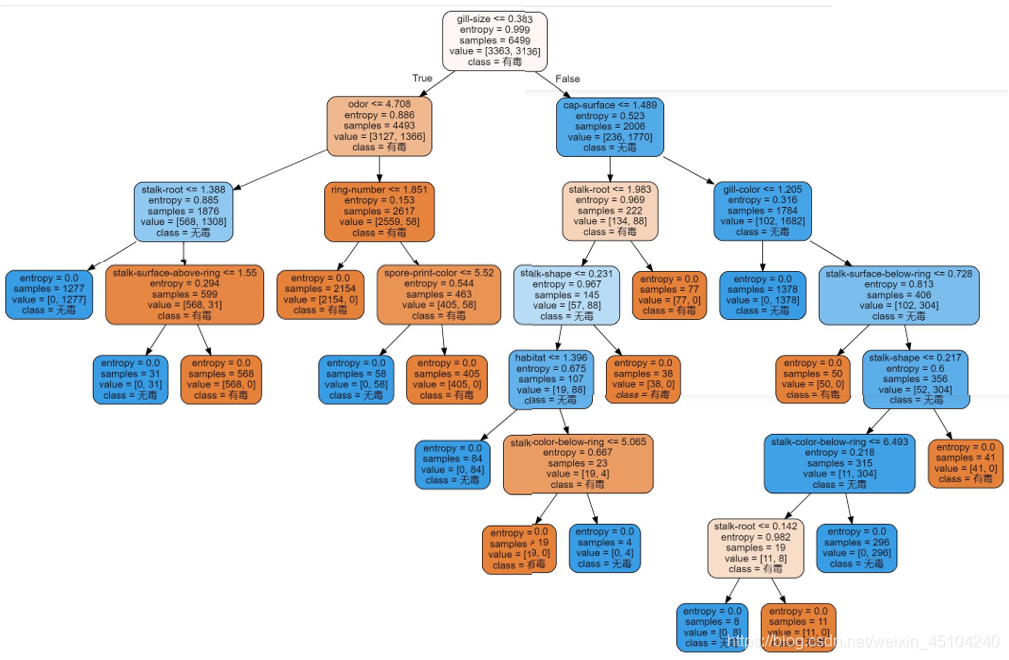
import graphviz
dot_data=tree.export_graphviz(clf
,feature_names=feature_name
,class_names=['有毒','无毒']
,filled=True
,rounded=True)
graph=graphviz.Source(dot_data)
graph
clf.apply(X_test)
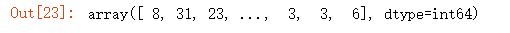
clf.predict(X_test)
print(clf.predict(X_test))
print(len(clf.predict(X_test)))
# for i in range(len(clf.predict(X_test))):
# print(clf.predict(X_test)[i]) #p 1 有毒 e 0 无毒
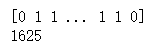
score=clf.score(X_test,y_test)
score
print(X_test)