前言
上一节我们简单的介绍了决策树的基本原理与使用,现在我们将会详细的通过实战案例介绍决策树
一、回归决策树可视化图构建
这次我们用房屋数据集去构建
- 导包数据集准备
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
import warnings
warnings.filterwarnings('ignore')
#%%
from sklearn.datasets._california_housing import fetch_california_housing
housing=fetch_california_housing(as_frame=True)
-查看数据情况
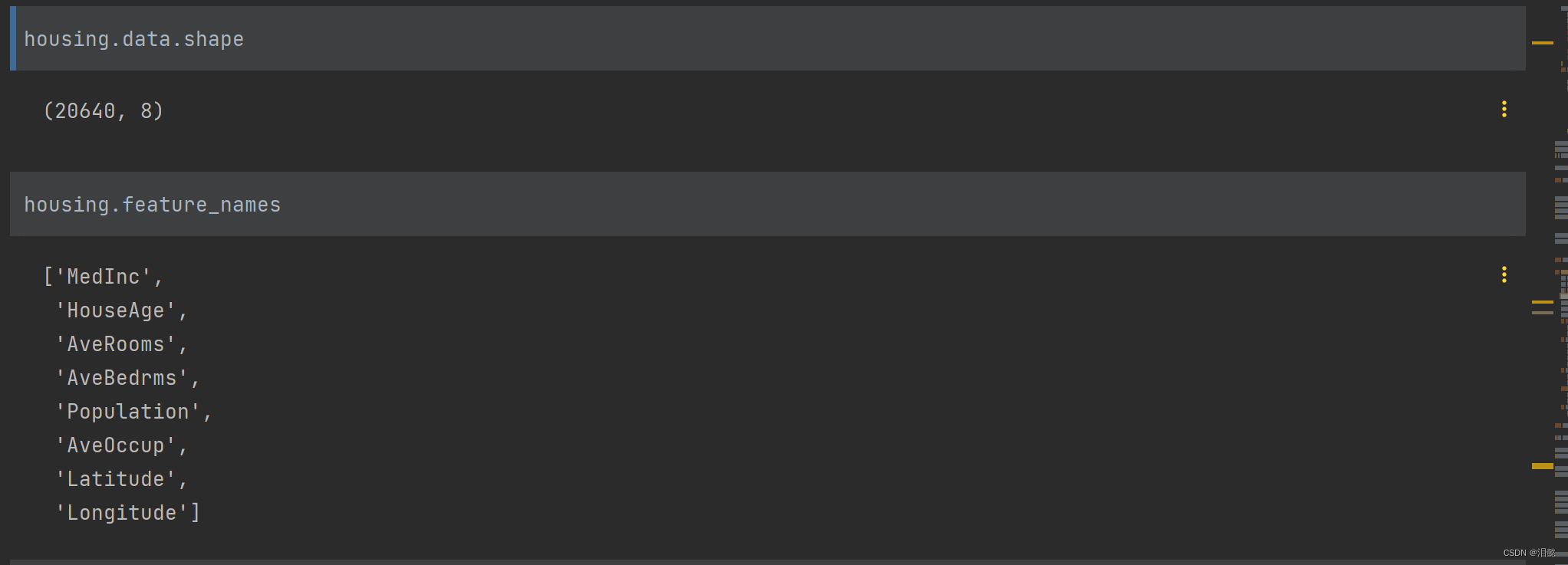
共有20640个数据,以及8个特征值,我们选择所有个特征值进行回归任务
from sklearn import tree
dtr=tree.DecisionTreeRegressor(max_depth=2)
dtr.fit(housing.data,housing.target)
构造决策可视化树图,大家需要下载graphviz(可自行网上搜索教程下载),为了简单,直接用sklearn中的可视化绘图工具
from sklearn.tree import plot_tree
plot_tree(dtr,filled=True)
plt.show()
二、分类器构建
这里我们还是用鸢尾花数据集,有4个特征值,我们将四个特征值两两分为6组,不同的组合,看哪两个特征值构建的分类器最好
- 导入数据
from sklearn.datasets import load_iris
iris=load_iris()
from sklearn.tree import DecisionTreeClassifier
from sklearn.inspection import DecisionBoundaryDisplay
import matplotlib.style as ms
import matplotlib
import matplotlib.pyplot as plt
matplotlib.use('TkAgg')
import numpy as np
DecisionBoundaryDisplay 是 scikit-learn 库中 sklearn.inspection 模块中的一个类。它用于可视化机器学习模型的决策边界。
DecisionBoundaryDisplay 类提供了一种方便的方法,可以在数据点旁边绘制分类器的决策边界。它接受一个分类器作为输入,并可以显示分类器在给定数据集上的预测结果。
- 模型训练以及绘图
n_cluser=3
plot_step=0.02
ms.use('seaborn-bright')
for index,pari in enumerate([[0, 1], [0, 2], [0, 3], [1, 2], [1, 3], [2, 3]]):
X=iris.data[:,pari]
y=iris.target
clf=DecisionTreeClassifier().fit(X,y)
ax=plt.subplot(2,3,index+1)
plt.tight_layout(h_pad=0.5,w_pad=0.5,pad=2.0)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method='predict',
ax=ax,
xlabel=iris.feature_names[pari[0]],
ylabel=iris.feature_names[pari[1]],
)
for i,color in zip(range(n_cluser),'rbg'):
idx=np.where(y==i)
plt.scatter(
X[idx,0],
X[idx,1],
c=color,
label=iris.target_names[i],
edgecolors='black',
s=12
)
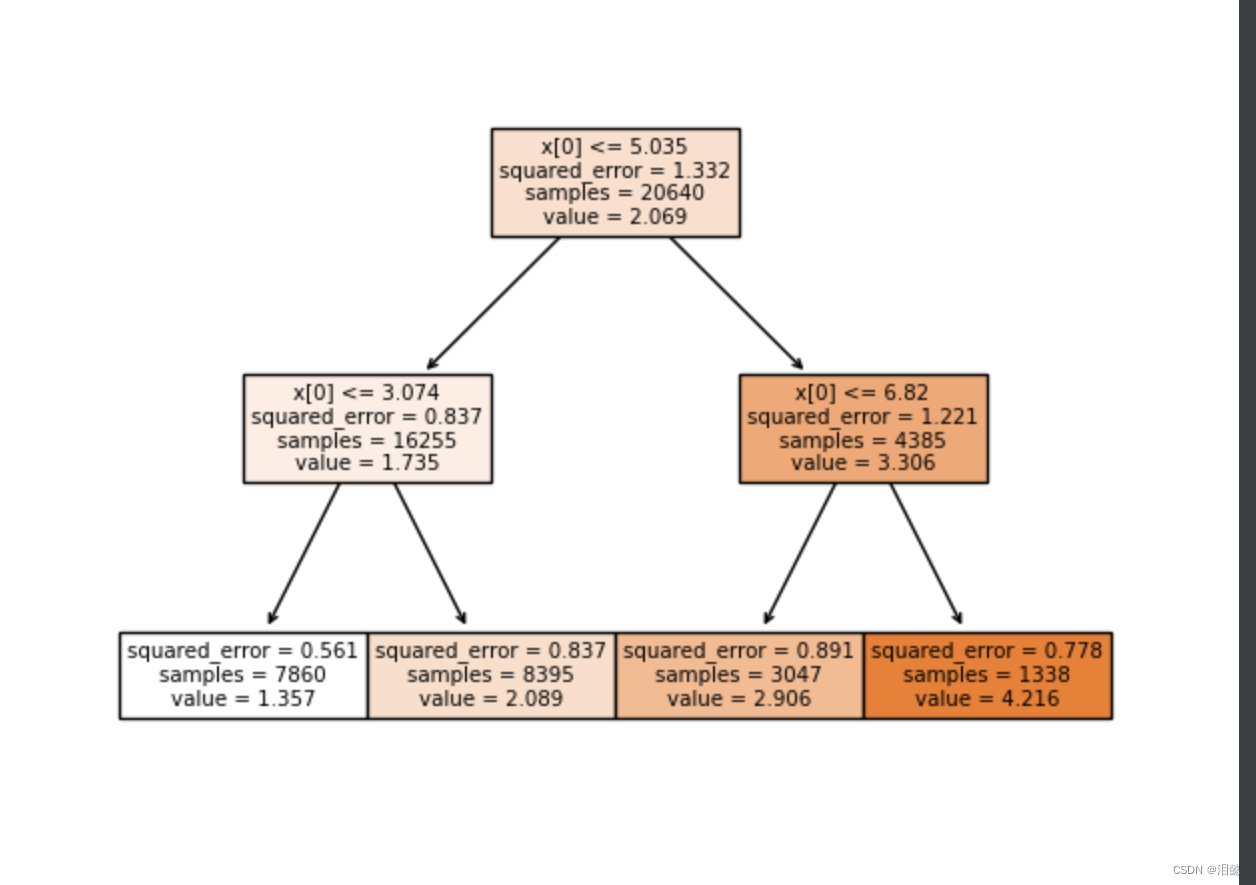
plt.suptitle("Decision surface of decision trees trained on pairs of features")
plt.legend()
plt.show()
可以看到总的来说,我们用petal width和petal length作为特征值是比较容易分类的
我们拿这两个特征值,构建决策树看一下
#%%
from sklearn.tree import plot_tree
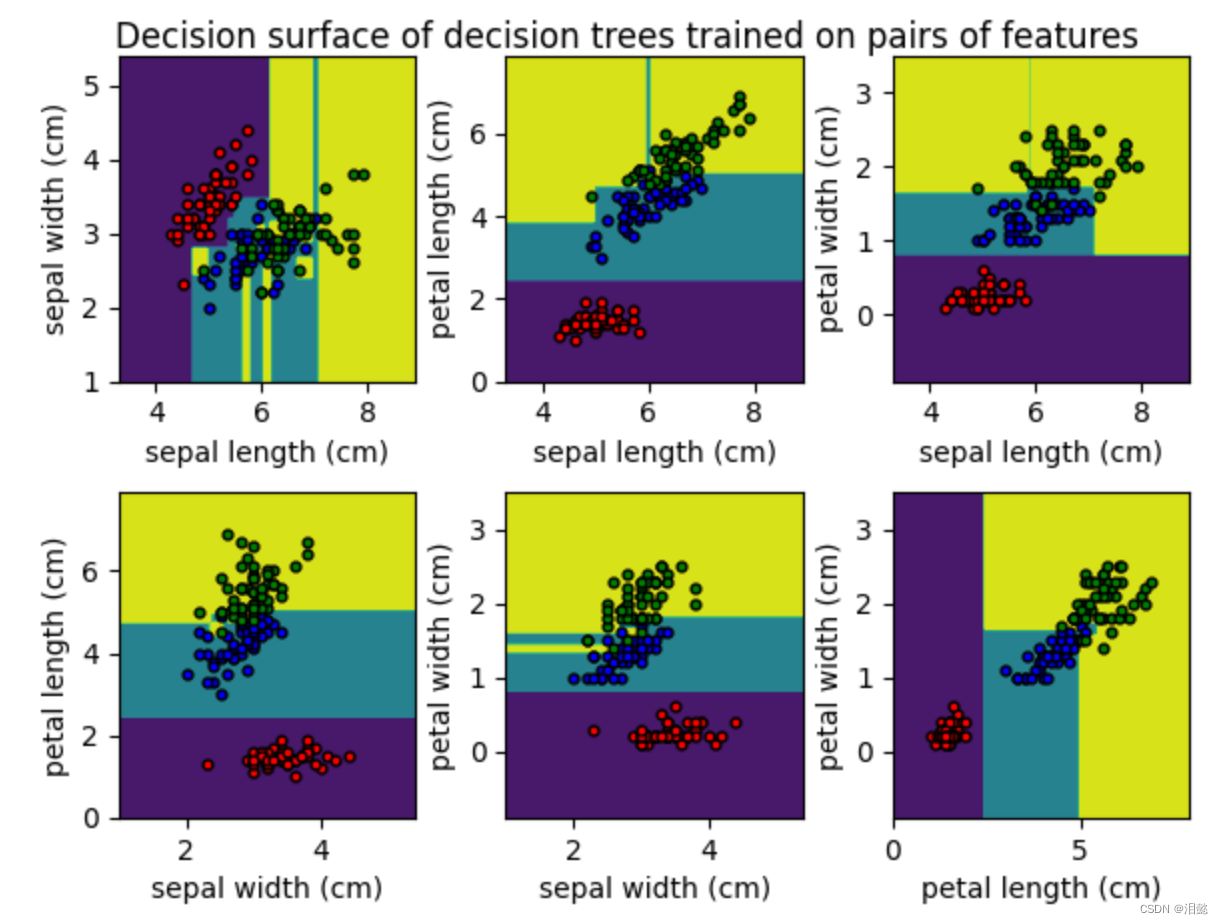
clf=DecisionTreeClassifier(max_depth=2).fit(iris.data[:,2:4],iris.target)
plot_tree(clf,filled=True, class_names=iris.target_names,)
plt.title("Decision tree trained on all the iris features")
plt.show()
 可以看到是通过基尼系数进行分类的,最大深度为2就将类别分类出来,当然这个是特征值比较少的情况下,特征值比较多,相应树的深度也会加大。
可以看到是通过基尼系数进行分类的,最大深度为2就将类别分类出来,当然这个是特征值比较少的情况下,特征值比较多,相应树的深度也会加大。
- 概率估计
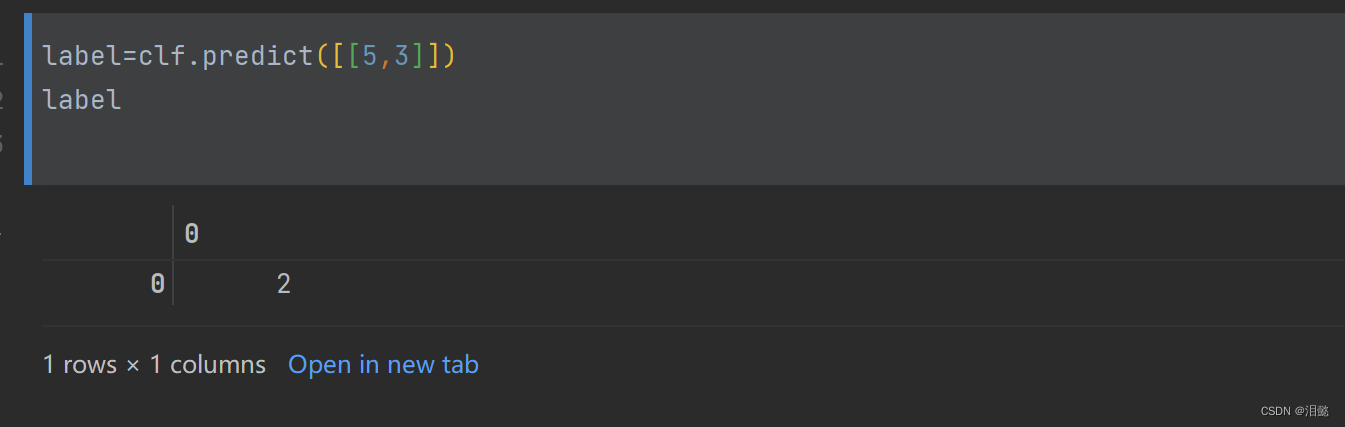 当特征值为[5,3]时候,模型划分为第3中类别
当特征值为[5,3]时候,模型划分为第3中类别
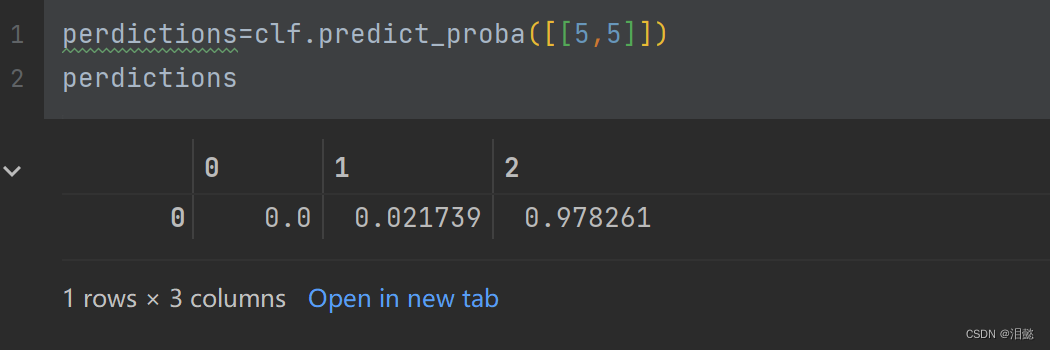
通过这样操作也能观察该特征值为[5,3]属于各类别的概率,选择概率最大的
三、数据敏感性的决策树模型构造影响
- 构建数据集
np.random.seed(6)
Xs = np.random.rand(100, 2) - 0.5
ys = (Xs[:, 0] > 0).astype(np.float32) * 2
angle = np.pi / 4
rotation_matrix = np.array([[np.cos(angle), -np.sin(angle)], [np.sin(angle), np.cos(angle)]])
Xsr = Xs.dot(rotation_matrix)
Xsr
Xs是一个包含100个样本的二维数组,每个样本有两个特征,生成的方式是从均匀分布中随机采样,然后减去0.5,范围变为[-0.5, 0.5]。ys是对Xs的第一个特征进行二分类的标签,当第一个特征大于0时,标签为2,否则为0。然后后定义一个旋转角度angle,并将它转换为旋转矩阵rotation_matrix。通过使用dot()函数将Xs矩阵与旋转矩阵相乘,生成一个新的矩阵Xsr,它是Xs经过旋转后的结果。
因此,这段代码的作用是生成一个二维数据集Xs,并在该数据集上进行了一个旋转操作,生成了一个新的数据集Xsr,用于后续的实验比较。
- 比较
def plot_show(clf,X,ax):
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method='predict',
ax=ax,
)
plt.scatter(X[:,0],X[:,1],c=ys,edgecolors='black')
from sklearn.inspection import DecisionBoundaryDisplay
tree_clf_s = DecisionTreeClassifier(random_state=42)
tree_clf_s.fit(Xs, ys)
tree_clf_sr = DecisionTreeClassifier(random_state=42)
tree_clf_sr.fit(Xsr, ys)
plt.figure(figsize=(11, 4))
ax=plt.subplot(121)
plot_show(tree_clf_s,Xs,ax)
plt.title('Sensitivity to training set rotation')
ax=plt.subplot(122)
plot_show(tree_clf_sr,Xsr,ax)
plt.title('Sensitivity to training set rotation')
plt.show()
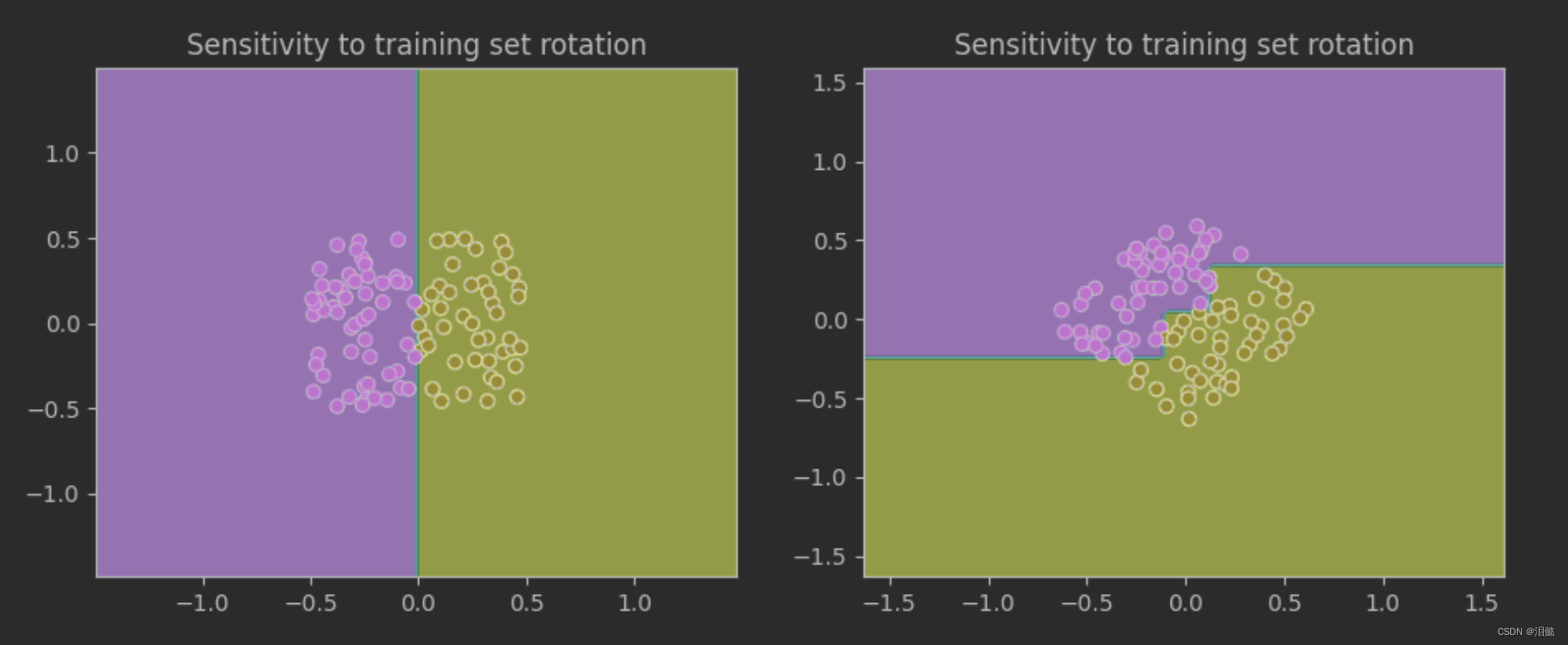 我们可以发现,决策树对于数据的旋转非常敏感,即使是轻微的旋转也可能导致模型的性能下降。这是因为决策树通过轴对齐的方式将特征空间划分为矩形区域,而数据旋转会导致这些矩形的形状和位置发生变化,从而影响模型的性能。这也说明了在实际应用中,我们应该尽量保证数据的原始方向,或者使用不受数据方向影响的模型,比如支持向量机(SVM)。
我们可以发现,决策树对于数据的旋转非常敏感,即使是轻微的旋转也可能导致模型的性能下降。这是因为决策树通过轴对齐的方式将特征空间划分为矩形区域,而数据旋转会导致这些矩形的形状和位置发生变化,从而影响模型的性能。这也说明了在实际应用中,我们应该尽量保证数据的原始方向,或者使用不受数据方向影响的模型,比如支持向量机(SVM)。
四、回归模型构建
- 数据集构建
import numpy as np
from sklearn.tree import DecisionTreeRegressor
np.random.seed(42)
X = np.sort(5 * np.random.rand(80, 1), axis=0)
y = np.sin(X).ravel()
y[::5] += 2 * (0.5 - np.random.rand(16))
plt.scatter(X,y,c='r',edgecolor="black")
plt.show()
我们在这些数据中加了一些噪声
我们可视化一下看我们的数据集
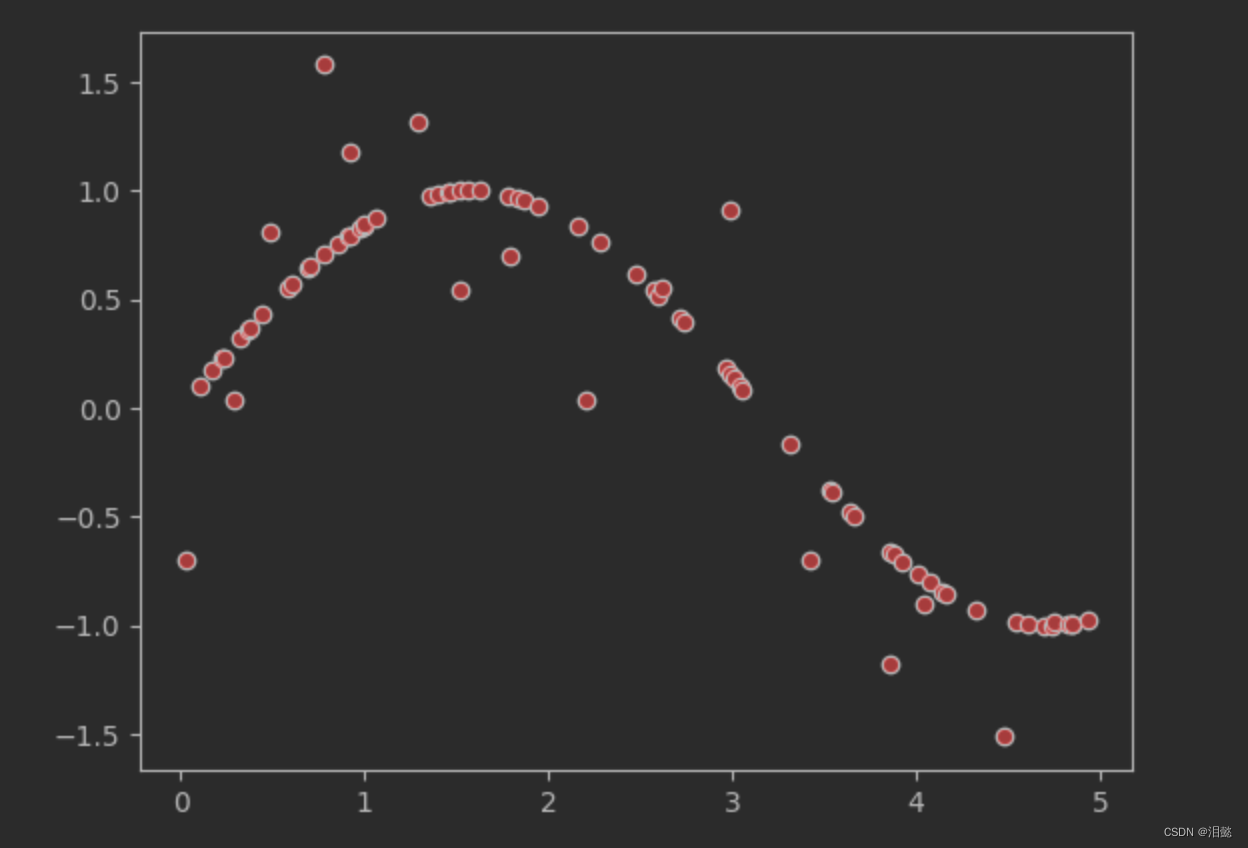
我们这里测试不同树深度对模型性能的影响,
树的深度从2到10,进行比较
max_depath=[i for i in range(2,11)]
plt.tight_layout(h_pad=0.5,w_pad=0.5,pad=2.0)
plt.figure(figsize=(10,8))
for depath in max_depath:
regr=DecisionTreeRegressor(max_depth=depath)
regr.fit(X,y)
x_test=np.arange(0.0,5.0,0.01)[:,np.newaxis]
y_petect=regr.predict(x_test)
plt.subplot(331+depath-2)
plt.scatter(X,y,s=15,edgecolors='black',c='r',label='data')
plt.plot(x_test,y_petect, color="cornflowerblue",
label=f"max_depth={
depath}")
plt.title(f"max_depth={
depath}")
plt.axis('off')
# plt.legend()
plt.show()
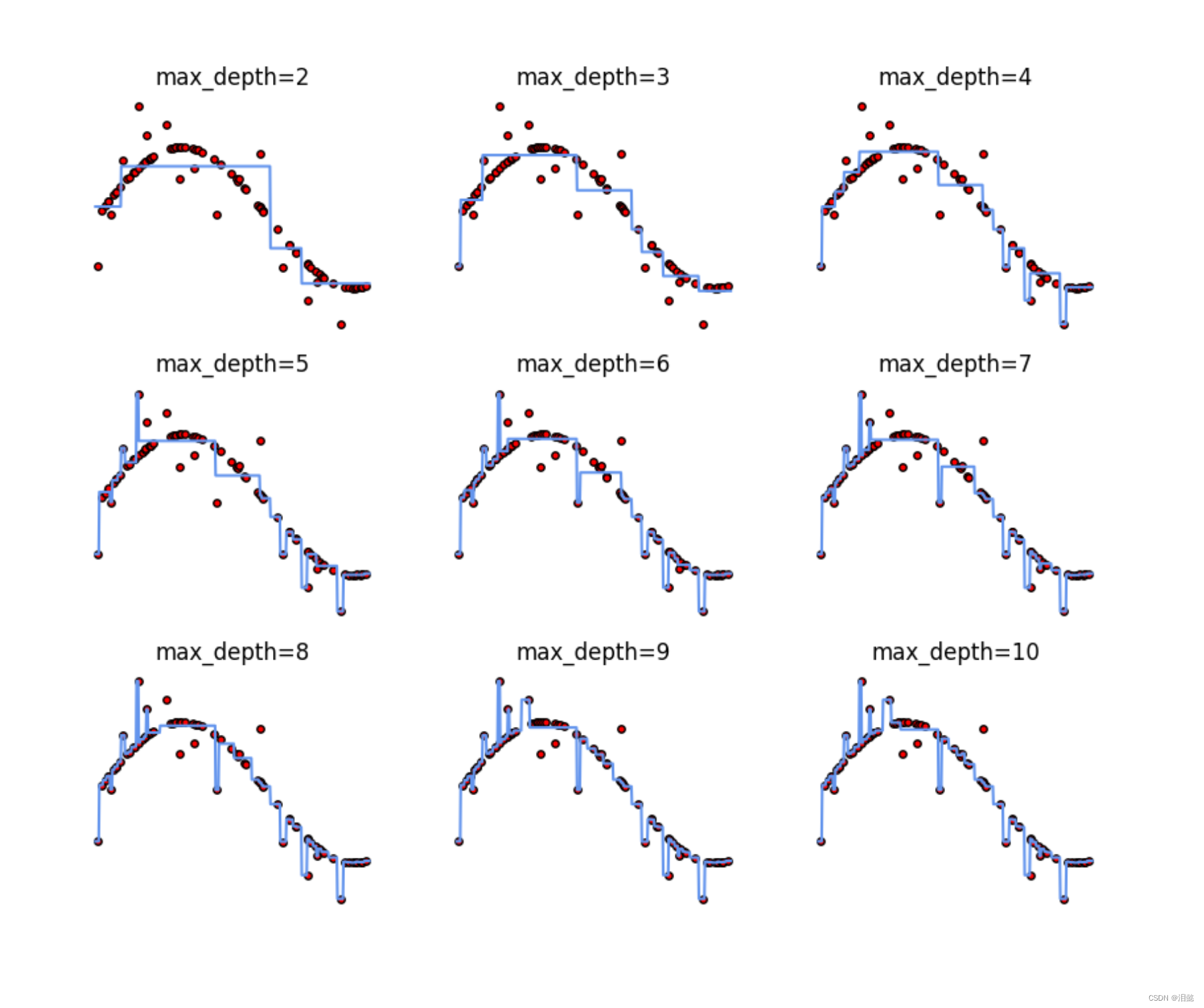 从图中我们发现,树的深度越深,就越会过度学习噪声,使得模型较差,无法获得正真的规律。
从图中我们发现,树的深度越深,就越会过度学习噪声,使得模型较差,无法获得正真的规律。
在回归问题中,决策树的深度越深,通常会导致以下影响:
过拟合:当决策树的深度很大时,决策树将变得非常复杂,容易过拟合训练数据,导致模型在新数据上表现较差。这是因为模型过度学习了训练数据中的噪声,而不是捕获其真实的规律。
偏差:当决策树的深度不足时,模型可能无法捕获输入特征和输出之间的非线性关系,从而导致偏差较高,模型在训练集和测试集上的表现都会较差。
计算开销:当决策树深度增加时,树的大小和计算开销也会增加。这会导致需要更长的时间来训练和测试模型,并且需要更多的计算资源。
- 不但但树的深度可能会对我们的回归模型有影响,包括最小树节点样本数也可能会有影响
依旧构造一份回归数据
np.random.seed(42)
m=200
X=np.random.rand(m,1)
y = 3*(X-0.4)**2
y = y + np.random.randn(m,1)/10
训练两个模型,一个是默认没有min_samples_leaf,一个是min_samples_leaf=10,我们观察有什么不同
tree_reg1 = DecisionTreeRegressor(random_state=42)
tree_reg2 = DecisionTreeRegressor(random_state=42, min_samples_leaf=10)
tree_reg1.fit(X, y)
tree_reg2.fit(X, y)
然后我们构造一份新的数据去预测结果
x1 = np.linspace(0, 1, 600).reshape(-1, 1)
y_pred1 = tree_reg1.predict(x1)
y_pred2 = tree_reg2.predict(x1)
plt.figure(figsize=(10, 4))
plt.subplot(121)
plt.plot(X, y, "r.")
plt.plot(x1, y_pred1, "g.-", linewidth=2, label=r"$\hat{y}$")
plt.axis([0, 1, -0.2, 1.1])
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", fontsize=18, rotation=0)
plt.legend(loc="upper center", fontsize=18)
plt.title("No restrictions", fontsize=14)
plt.subplot(122)
plt.plot(X, y, "r.")
plt.plot(x1, y_pred2, "b.-", linewidth=2, label=r"$\hat{y}$")
plt.axis([0, 1, -0.2, 1.1])
plt.xlabel("$x_1$", fontsize=18)
plt.title("min_samples_leaf={}".format(tree_reg2.min_samples_leaf), fontsize=14)
plt.show()
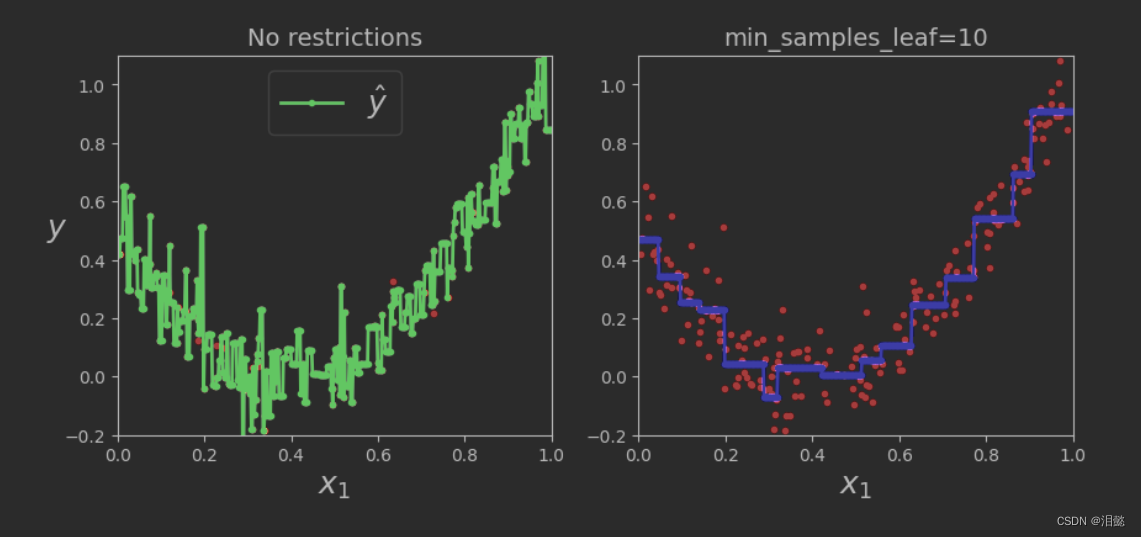 可以看到,当我们没有设置min_samples_leaf最小节点样本数的时候,预测模型结果就会过拟合
可以看到,当我们没有设置min_samples_leaf最小节点样本数的时候,预测模型结果就会过拟合
决策树算法中,min_samples_leaf参数用于控制叶子节点上最少的样本数。它的取值越小,决策树越容易过拟合,因为节点变得更加细分,更可能捕捉到训练数据中的噪声。相反,当取值较大时,决策树会趋向于更简单的模型,但会失去一些细节信息。
具体而言,当min_samples_leaf取值较小时,每个叶子节点上的样本数会减少,可能导致一些不重要的特征被选择,并因此出现过拟合。反之,当min_samples_leaf取值较大时,模型会趋于简单,过度拟合的可能性会降低,但模型的准确性和泛化能力也会降低。
因此,调整min_samples_leaf参数可以控制决策树的复杂度,并影响模型的准确性和泛化能力。在实际应用中,可以通过交叉验证等方法来确定最优的min_samples_leaf参数取值。
总结
本文简单介绍了决策树在分类和回归中的案例,我们应当注意以下一些问题
- 数据预处理:决策树对于缺失值的处理能力较强,但是对于异常值和噪声数据会影响模型的预测能力。因此,在训练模型前,需要进行数据清洗和预处理,去除异常值和噪声数据,以提高模型的准确性。
- 特征选择:特征选择是构建决策树模型的重要步骤。在特征选择时,应该选择与目标变量相关性较高的特征,以提高模型的准确性。
- 模型评估:评估模型的好坏,可以采用交叉验证的方法,如k折交叉验证,以保证模型的泛化能力。
- 参数设置:决策树模型中有许多参数需要设置,如决策树的深度、分裂节点的最小样本数等。在实战中需要根据数据集的特点,调整这些参数,以提高模型的准确性和泛化能力。
在参数设置方面,常见的参数包括:
criterion:分裂节点的评价标准,常用的有基尼系数和信息熵。
max_depth:决策树的最大深度,控制决策树的复杂度。
min_samples_split:分裂节点的最小样本数,如果节点样本数小于该值,则不进行分裂。
min_samples_leaf:叶子节点的最小样本数,如果叶子节点样本数小于该值,则不进行分裂。
max_leaf_nodes:叶子节点的最大数量,控制决策树的复杂度。
random_state:随机数种子,控制每次运行的结果一致。- 防止过拟合:决策树模型容易出现过拟合的问题,因此需要采取措施防止过拟合,如剪枝、设置叶子节点最小样本数等。
- 可视化:决策树模型具有很好的可解释性,在实战中,通过可视化决策树模型可以更加直观地了解模型的决策过程。
关于数据预处理,模型评估可以参考往期文章
由于本人能力有限,上述有任何错误欢迎指正
希望多多支持,一起努力