声明
在参加大数据竞赛的过程中发现用到的算法都是基于树模型的,想着将所有的树模型算法全部归纳总结一下,形成自己的知识体系,本文是机器学习树模型系列文章中的第一篇,讲解最基础的决策树模型,本人不是什么大牛,文章也是自己对于树模型的理解,如果有什么不正确的地方还望指出,欢迎留言讨论,共同进步!
正文
对决策树定义的理解
顾名思义,树模型因为包含多个分支,像大树一样不断的分散开来所以得名树模型,常用于分类和回归问题,其优点为具有可读性,分类速度快。在实际中具有很强的实战性,现在比较火的Xgboost,LightGBM都是基于树模型建立的。对于一棵树,我们能够想到有树干,分支以及树叶,决策树也由这三部分构成,对于一个现有的数据集而言,我们可以首先把它作为一个整体,进行特征提取后他们相当于由一个个特征(设为f1,f2,f3....fn)集合而成,之后我们选择一种规则,我们利用这种规则来选择特征,首先选出来的特征(假设为fx)就作为这棵树的树干,然后将数据集在特征为fx时切割成两个部分,这两个部分就分别叫做一个分支,之后这两个分支再按照相同的规则选取最合适的特征进行切割,直到不能分割为止,最后不能分割的分支就叫做树叶,一个决策树分类过程就完成了。所以可以看出,一棵树的分类过程至少需要包含这几个部分:特征选择,规则的制订,树的分割。之后为了防止树的过拟合,还需要加上剪支的环节。那根据规则的不同我们主要有ID3,C4.5以及CART等算法,下面将详细解释。
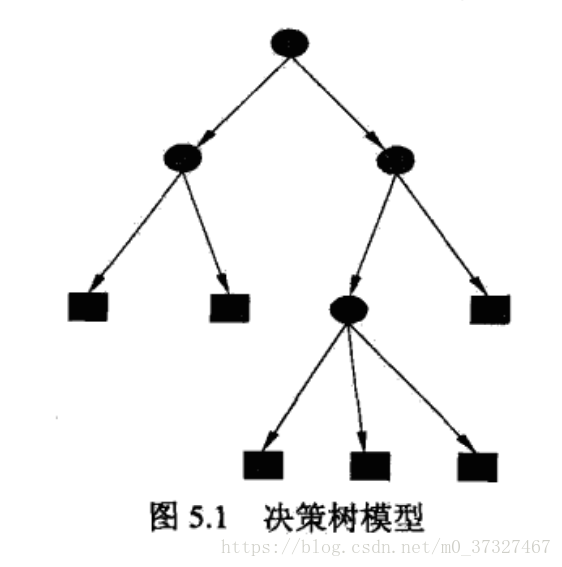
决策树特征划分选择
前面讲到了决策树的划分是将特征按照某种规则进行分割,那具体是哪种规则呢?ID3算法按照的是信息增益,C4.5是按照信息增益比,CART对分类树用基尼指数、回归树用平方误差最小化准则对特征进行分割。下面将一一详解。
ID3算法
ID3算法是利用信息增益来进行特征分割的,什么叫做信息增益,在李航的《统计学习方法》中有定义:


可能看定义比较抽象,不是很理解,没关系,在书中还有专门的例子:

如表5.1所示是一个二分类问题,上面给的例子相当于是一个训练集,有年龄,有工作,有自己房子,信贷情况这四个特征,我们分别按照信息增益的公式算法每个特征的信息增益
首先计算经验熵H(D):这里因为有15个样本,所以分母是15,其中类别为是的有9个,作为正样本,6个否的作为负样本。
其次将年龄,有工作,有自己的房子,信贷情况分别记为A1,A2,A3,A4,根据公式(5.8)分别计算信息增益:
A1:年龄有3中情况,所以式子中的n为3,青年,中年,老年各位5个,所以等于5/15, 其中青年5个中类别为否的有3个,是的有2个,中年5个中类别为否的有2个,是的有3个,老年5个类别为否的有1个,是的有4个,所以计算的公式为:
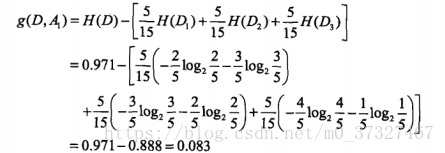
同理A2,A3,A4分别为:

可以发现A3的信息增益是最大的,所以我们应该首先将A3设为整棵树的树干,A3分为是和否两类,其中是这一列类别全部为是,不用再进行分类了,否这一列再从年龄(A1),有工作(A2),信贷情况(A3)这三个中按照前面的方法再进行挑选。
如A1,当有房子这一列为否时,可以分为三类,其中青年:4个,这4各种类别为是的有3个,否的有1个;中年:2个,是有0个,否有2个(说明不用分类了,这一部分直接不用算了,等于0),老年:3个,类别为是的有2个,否的有1个,所以将青年和老年的经验条件熵进行相加,得到结果0.667,最后用经验熵相减得到年龄的信息增益为0.918-0.667得到0.251,同理可以得到有工作,信贷情况的信息增益分别为0.918,0.474,选择增益最大的特征作为分支进行分割,不断重复这样的过程最后无法分割为止,这样得到一棵树。当然这样得到的树很容易过拟合,我们必须进行减枝进行处理。
C4.5算法
C4.5算法和ID3算法类似,唯一不同的是规则由信息增益比取代信息增益:
