文章目录
前言
论文标题:VideoBERT: A Joint Model for Video and Language Representation Learning
(VideoBERT:一个用于视频和语言表征学习的联合模型)
论文网址:https://arxiv.org/abs/1904.01766
源码网址:https://github.com/ammesatyajit/VideoBERT
基于 BERT 在 NLP 的成功,作者将 BERT 结合到视频领域(视觉-语言),提出了 VideoBERT。实验表明,VideoBERT 对动作分类任务直接进行 zero-shot 推理时,就能与先前的有监督训练好的 S3D 取得差不多的效果。用 VideoBERT 去做下游任务 video captioning 时,也是显著超过了 S3D,作者也将 VideoBERT 和 S3D 进行结合,混合模型的效果甚至超过了 SOTA。
一些例子:

上半图:给定一些食谱文本,将其分成句子 y = y 1 : T y=y_{1:T} y=y1:T,使用 VideoBERT 计算 x t ∗ = a r g m a x k p ( x t = k ∣ y ) x_t^*=arg\ max_k\ p(x_t=k|y) xt∗=arg maxk p(xt=k∣y) 来生成一个视频 tokens 序列 x = x 1 : T x=x_{1:T} x=x1:T。
下半图:给出一个视频 token,这里展示了 VideoBERT 在不同时间尺度下预测的未来 tokens 的前三个。在这种情况下,VideoBERT 预测一碗面粉和可可粉可能在烤箱中烘烤,并可能成为布朗尼或纸杯蛋糕。
利用特征空间中最接近中心点的训练集的图像对视频 tokens 进行可视化。
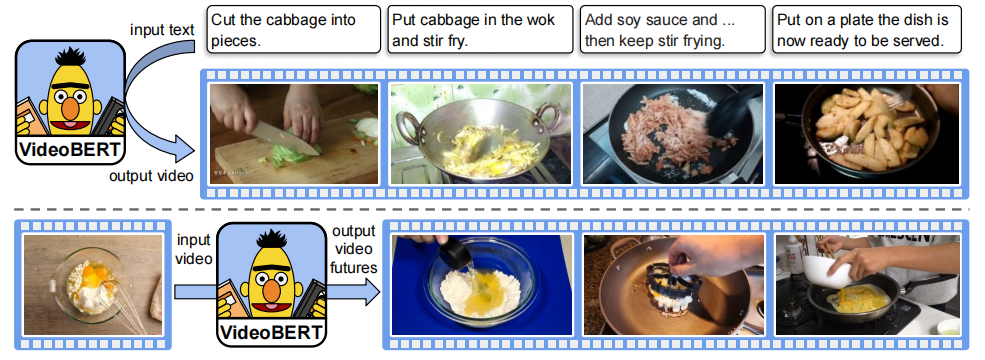

Figure 6:通过 VideoBERT 和 S3D baseline 生成的描述的示例。(其中 GT 为 ground truth )在最后一个示例中,VideoBERT未能利用完整的时态上下文,因为它忽视了纸巾(paper towel)。
0 摘要
自监督学习对于利用 YouTube 等平台上丰富的 未标记的数据 变得越来越重要。鉴于大多数已有的方法都是学习底层(low-level)表征,我们提出一个视觉-语言联合模型(原文:a joint visual-linguistic model)来学习高层(high-level)特征,而且不需要任何明确的监督。特别是,受其最近在语言模型中成功的启发,作者基于 BERT 模型来学习视觉和语言 tokens 序列的双向联合分布,这些序列分别来自视频数据的矢量量化和现成的语音识别输出中导出。VideoBERT 被应用在很多任务中,包括动作分类(action classification)和视频描述(video captioning)。作者证明了它可以应用于开放词汇的分类(open vocabulary classification),也证实了大量的训练数据和跨模态信息对性能至关重要。此外,VideoBERT 在视频描述任务中优于 SOTA,定量的结果验证了该模型学习了高层语义特征。
图像底层(low-level)、高层(high-level)特征:对图像中语义信息、高层和底层特征的理解
- 图像底层特征:轮廓、边缘、颜色、纹理和形状特征等。
- 图像高层特征:图像的高层语义特征指的是我们所能看的东西,比如对一张人脸提取低层特征我们可以提取到脸的轮廓、鼻子、眼睛之类的,那么高层特征就显示为一张人脸。高层特征语义信息比较丰富,但是目标位置比较粗略。
1 Introduction
深度学习可以从有标签的数据中受益很多,但很难获得极大量的有标签的数据。因此,最近人们对自监督学习很感兴趣,我们在各种“辅助任务”上训练一个模型,并且希望它可以应用于下游任务中特征或表征的发现。在图像和视频领域已经提出了各种各样的此类辅助任务,然而,这些方法大多都关注于底层特征(如,纹理)和短时间尺度(如,持续一秒钟或更短的运动模式)。作者发现在更长时间尺度(如,分钟)上展开的动作和活动对应着高层语义特征,因为这种表征将有助于各种视频理解任务。
在本文中,作者利用了人类语言已经进化出用来描述高层物体和事件的词语,从而提供了自监督的自然来源。特别是,我们提出了一种简单的方法去建模视觉领域和语言领域之间的关系,这个方法结合了三种现成的方法:
- 将语音转化为文本的自动语音识别(Automatic Speech Recognition,ASR)系统;
- 将矢量量化(Vector Quantization,VQ )应用于从预训练视频分类模型来提取底层时空的视觉特征;
- 最近提出的 BERT 模型用于学习离散 tokens 序列上的联合分布。
VideoBERT 就是使用 BERT 去学习一个形式为 p ( x , y ) p(x,y) p(x,y) 的模型,其中 x x x 是一个 “视觉词 (visual words)” 的序列, y y y 是一个口语词的序列。给出这样一个联合模型,可以轻松地处理各种有趣的任务。 例如,我们可以进行 text-to-video 的预测,它可以用来自动说明一组指令(例如一个食谱),如 Figure 1 和 Figure 2 中上半图的示例所示。 我们还可以进行更传统的 video-to-text 的任务,即密集的视频描述,如 Figure 6 所示。在 4.6 节中,作者展示了他们的视频描述方法在 YouCook II 数据集上明显优于以前的 SOTA。
我们也可以以 “单峰 (unimodal)” 的方式使用我们的模型。 例如,隐含边际分布 p ( x ) p(x) p(x) 是一个针对视觉词的语言模型,我们可以用它来进行长时间预测。 Figure 1 和 Figure 2 中下半图的示例说明了这一点。 当然,未来存在不确定性,但该模型可以在比其他视频深度生成模型更高的抽象层次上产生可信的猜测,例如那些基于 VAEs 或 GANs 的模型,它们倾向于预测场景的低层次方面的微小变化,例如少量物体的位置或姿态。
总之,作者在本文中的主要贡献是一种简单的方法来学习高层次的视频表示,捕捉语义上有意义的和时间上长程的结构。 本文的其余部分详细描述了这一贡献。 第2节简要回顾相关工作,第3节描述了如何将自然语言建模的最新进展应用到视频领域,第4节介绍了动作识别和视频描述任务的结果,第五节是总结。
2 相关工作
监督学习
大部分的视频表征学习方法都是利用大的有标记的数据集来训练卷积神经网络用于视频分类。然而,收集这些有标记的数据非常昂贵,并且相应的标签的词汇往往很小,无法表示多种行为的细微差别(例如,“sipping(小口喝,呷,抿)”、“drinking(喝,饮)” 和 "gulping(吞咽)"都只有很小的差别)。此外,这些方法是为了表示短视频剪辑而设计的,通常只有几秒钟长,而本文的工作主要专注于视频中事件的长期演变,并且不需要手动提供的标签。
无监督学习
近年来,多种从视频中学习密度模型的方法。这些方法要么使用单个静态随机变量,然后使用 RNN 将其解码成一个序列,要么就是使用 VAE 或 GAN 类型的损失函数。最近的工作使用时间随机变量,例如 SV2P (Stochastic Variational Video Prediction) 和 SVGLP (Stochastic Video Generation with a Learned Prior),此外也有各种基于 GAN 的方法,例如 SAVP (Stochastic Adversarial Video Prediction) 和 MoCoGAN (MoCoGAN: Decomposing Motion and Content for Video Generation)。本文与上述工作的不同之处在于使用 BERT 应用于从视频中导出 visual tokens,且没有任何显式的随机潜变量。因此,我们的模型不是 pixel 的生成模型,但它是从 pixel 中导出的特征的生成模型。
自监督学习
为了避免学习联合模型 p ( x 1 : T ) p(x_{1:T}) p(x1:T) 的困难,学习 p ( x t + 1 : T ∣ x 1 : t ) p(x_{t+1:T}\mid x_{1:t}) p(xt+1:T∣x1:t) 的条件模型已变得流行,其中我们将信号划分为两个或多个块,例如灰度和颜色,或前一帧和下一帧,并试图预测其中一个和另一个。 我们的方法是相似的,除了我们使用量化的 visual words 而不是 pixels。 此外,尽管我们学习了一组条件分布,但我们的模型是一个适当的联合生成模型,如第3节所解释的。
跨模态学习
视频的多模态类型也是学习视频表征的一个广泛的监督来源,本文就是在此基础上建立的。 由于大多数视频包含同步的音频和视觉信号,这两种模式可以相互监督以学习强的自监督视频表示。在这项工作中,作者使用语音(由ASR提供)而不是低级声音作为跨模态监督的来源。
自然语言模型
大规模的语言模型,如 ELMO 和 BERT 已经在各种 NLP 任务中获得 SOTA,无论是在词层(如词性标注)还是句子层(如语义分类)。BERT 随后也被扩展到对多语言数据进行预训练。 本文建立在 BERT 的基础上,以获取在语言和视觉领域的体系。
图像和视频描述
最近有许多关于图像描述的工作,它是形式为 p ( y ∣ x ) p(y\mid x) p(y∣x) 的模型,其中 y y y 是手动提供的描述, x x x 是图像。 也有一些关于视频描述的工作,使用手动提供的时间分段或估计分段。 作者使用联合 p ( x , y ) p(x,y) p(x,y) 模型,并将其应用于视频描述,并获得了 SOTA,正如在本文 4.6 节中讨论的那样。
教学视频
各种论文都有用训练好的模型来分析教学视频,如烹饪视频。我们与这项工作的不同之处在于,我们不使用任何人工标记,我们学习了一个大规模的生成模型,其既有单词信号,也有离散化的视觉信号。
3 模型
本节中,先简要地总结了 BERT,然后描述了如何扩展它来联合建模视频和语言数据。
3.1 BERT
BERT 提出了使用 “掩码语言模型” 来学习语言特征,即 设 x = { x 1 , … , x L } x=\{x_1,…,x_L\} x={
x1,…,xL} 是一个离散的 tokens 集合。我们可以定义这个集合上的联合概率分布如下:
p ( x ∣ θ ) = 1 Z ( θ ) ∏ l = 1 L ϕ l ( x ∣ θ ) ∝ exp ( ∑ l = 1 L log ϕ l ( x ∣ θ ) ) p(x\mid\theta) = \frac{1}{Z(\theta)} \prod \limits_{l=1}^L \phi_l(x\mid\theta) \varpropto \exp(\sum \limits_{l=1}^L\log \phi_l(x\mid\theta)) p(x∣θ)=Z(θ)1l=1∏Lϕl(x∣θ)∝exp(l=1∑Llogϕl(x∣θ))
其中 ϕ l ( x ) \phi_l(x) ϕl(x) 是第 l l l 个 势函数 (potential function),参数 θ \theta θ 和 Z Z Z 是 配分函数 (partition function).
上述模型是置换不变的。为了获取顺序信息,我们可以在每个词在句中的位置来“标记”它。BERT 学习了每个 word tokens 和这些标签的 embedding,然后对 embedding向量求和,得到每个 token 的连续表示。每个位置的对数 势(能量)函数定义如下:
log ϕ l ( x ∣ θ ) ) = x l T f θ ( x \ l ) \log \phi_l(x\mid\theta)) = x_l^T f_\theta(x_{\backslash l}) logϕl(x∣θ))=xlTfθ(x\l)
其中 x l x_l xl 是第 l l l 个 token 及其标签的 独热向量(one-hot vector),且:
x \ l = ( x 1 , . . . , x l − 1 , M A S K , x l + 1 , . . . , x L ) x_{\backslash l} = (x_1,...,x_{l-1},MASK,x_{l+1},...,x_L) x\l=(x1,...,xl−1,MASK,xl+1,...,xL)
f ( x \ l ) f(x_{\backslash l}) f(x\l) 是一个多层双向 Transformer,它取一个 L × D 1 L\times D_1 L×D1 的 tensor,包含与 x \ l x_{\backslash l} x\l 相对应的 D 1 D_1 D1 维 embedding 向量,并返回一个 L × D 2 L\times D_2 L×D2 的 tensor,其中 D 2 D_2 D2 是每个 Transformer 结点的输出的大小。该模型被训练成近似最大化的伪对数似然:
L ( θ ) = E x ∼ D ∑ l = 1 L log p ( x l ∣ x \ l ; θ ) L(\theta) = E_{x\sim D}\sum \limits_{l=1}^L \log p(x_l \mid x_{\backslash l};\theta) L(θ)=Ex∼Dl=1∑Llogp(xl∣x\l;θ)
在实践中,我们可以通过抽样位置和训练句子来随机优化 logloss (由 f f f 函数预测的 softmax 计算)。
BERT 可以扩展去建模两个句子通过将他们连接在一起,然而,我们往往不仅仅对扩展序列进行简单建模感兴趣,而是对两个句子之间的关系感兴趣(例如,这是一对先序的句子还是随机选择的句子)。BERT 通过用一个分类头 [CLS] token,并通过用一个分隔符 [SEP] token 连接句子来实现这一点。 与 [CLS] token 相对应的最终隐藏状态被用作集合序列表示,我们从中预测分类任务的标签,否则可能被忽略。 除了用[SEP] token 来区分句子之外,BERT 还可以根据每个 token 来自的句子来选择标记。 对应的联合模型可以写成 p ( x , y , c ) p(x,y,c) p(x,y,c),其中 x x x 是第一个句子, y y y 是第二个句子, c = { 0 , 1 } c=\{0,1\} c={ 0,1} 是一个标记,用指示这些句子在源文档中是离散的还是连续的。
为了与原论文保持一致,我们还在序列的末尾添加了 [SEP] token,尽管它并不是严格需要的。 因此,一个典型的 masked-out 训练句子对可能如下所示:[CLS] let’s make a traditional [MASK] cuisine [SEP] orange chicken with [MASK] sauce [SEP]. 在这种情况下,相应的类标签为 c = 1 c=1 c=1,表明 x x x 和 y y y 是连续的。
3.2 VideoBERT
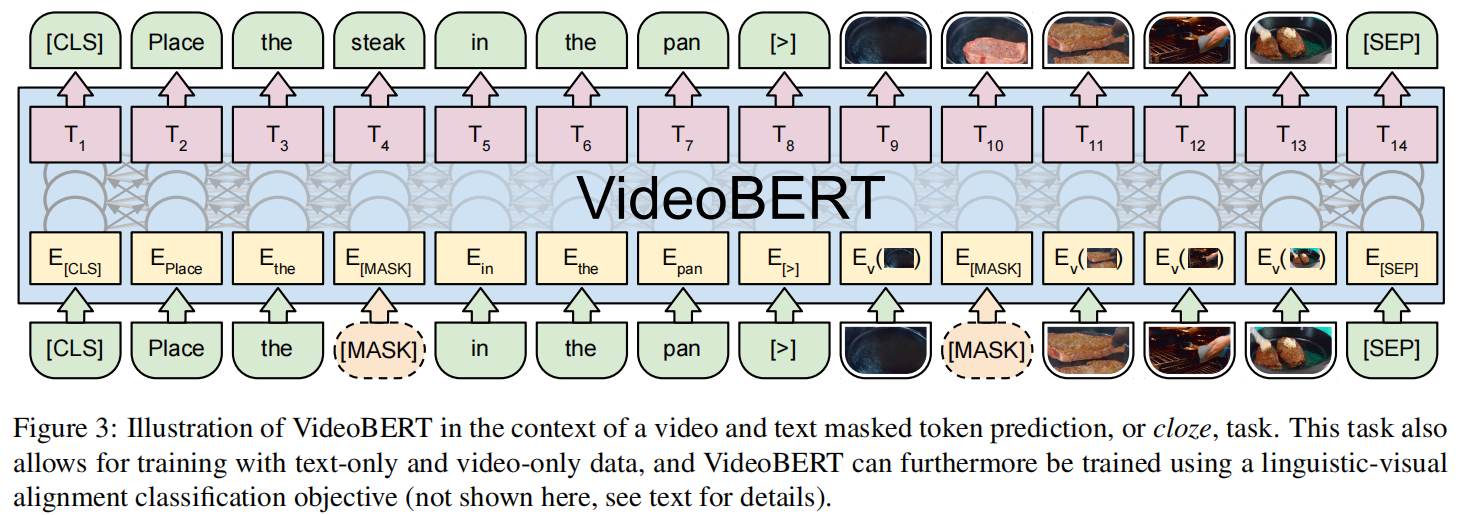
为了将BERT扩展到视频,我们仍然可以利用预训练语言模型和可伸缩的实现来进行推理和学习,作者做出了极小的改变,即将原始的视觉数据转换为离散的 tokens 序列。 为此,作者提出通过对从视频中提取的特征使用预训练模型进行分层矢量量化来生成一个 “visual words” 序列。 除了这个方法简单外,它也鼓励模型关注于视频中的高层语义和更长时间的动态变化,这与大多数现有的自监督的视频表征学习(关注与底层特征,如局部纹理和运动)形成鲜明对比。
我们可以将语言语句(使用 ASR 从视频中生成)和视觉语句结合起来生成这样的数据:[CLS] orange chicken with [MASK] sauce [>] v01 [MASK] v08 v72 [SEP],其中 V01 和 V08 是 visual tokens,[>] 是用于结合文本和视频语句的特殊 token。
虽然完形填空任务自然地扩展到语言和视觉 tokens 序列,但使用 BERT 去做下一句子预测任务就不那么简单了。 作者提出了一个 语言-视觉 对齐任务,使用[CLS] token的最终隐藏状态来预测语言语句是否与视觉语句在时间上对齐。 请注意,这是语义相关性的一个噪声指示,因为即使在教学视频中,说话者也可能指的是视觉上不存在的东西。
为了解决这个问题,首先随机地将相邻的句子连接成一个长句子,即使两个句子在时间上没有很好地对齐,模型也可以学习语义的对应关系。其次,由于在不同的视频中,即使是同一动作,其状态转换速度也会有很大的差异,我们随机选取 1-5 步的二次采样率进行 video tokens。 这不仅有助于模型对视频速度的变化具有更强的鲁棒性,而且允许模型在更大的时间范围内获取时间动态并学习更长期的状态转换。
总的来说,有三种训练机制对应于不同的输入数据模式:纯文本、纯视频 和 视频-文本。 对于纯文本和纯视频,使用标准的掩码目标函数来训练模型。对于 文本-视频,我们使用上面描述的 语言-视觉 对齐分类目标函数。 总体的训练目标是单个目标的加权和:文本目标使 VideoBERT 在语言建模方面做得很好; 视频目标使它学习一个 “用于视频的语言模型”,可用于学习动态和预测; 文本-视频目标使它学习两个领域之间的对应关系。
一旦训练了模型,我们就可以在各种下游任务中使用它,这里作者定量地评估了两个应用。 在第一个应用中,把它作为一个概率模型,要求它预测或推算已经被 mask 掉的符号,比如在 4.4 节中做了 zero-shot 的分类。在第二个应用中,提取 [CLS] token 的预测表示(来自模型的内部激活函数),并使用该密集向量作为整个输入的表示。 这可以与从输入中导出的其他特征相结合,以便在下游监督学习任务中使用,比如在 4.6 节中做了视频 captioning。
4 实验与分析
4.1 数据集
在语言和视觉领域,以往的模型都证明了数据集越大,模型的性能越好。因此,我们希望用一个相当大规模的视频数据集来训练 VideoBERT。 由于希望探索语言和视觉之间的联系,作者希望找到口语更有可能指代视觉内容的视频。 直观地说,教学视频通常是这种情况,作者特别关注烹饪视频,因为它是一个经过充分研究的领域,现有的注释数据集可用于评估。 不幸的是,这样的数据集相对较小,所以作者转向 YouTube 收集大规模的视频数据集进行训练。
作者使用 YouTube 视频注释系统从 YouTube 中提取一组公开的烹饪视频,以检索与 “烹饪” 和 “食谱” 相关的视频。 作者还根据视频的时长进行过滤,删除超过15分钟的视频,产生一组 312K 的视频。 此数据集的总持续时间为 23186 小时,约为 966 天。 作为参考,这比最大的烹饪视频数据集 YouCook II 大了两个数量级以上,YouCook II 由 2K 个视频组成,总时长176小时。
为了从视频中获取文本,我们利用 YouTube 的自动语音识别(ASR)工具包(由YouTube Data API提供)来检索带时间戳的语音信息。 API返回单词序列和预测的语言类型。 在 312K 的视频中,有 180K 的 ASR 可以被 API 检索,其中 120K 预计是英语的。 在实验中,当使用所有视频作为纯视频目标时,只使用来自英语 ASR 的文本作为 VideoBERT 的纯文本和 视频-文本 的目标。
在 YouCook II 数据集上评估 VideoBERT,该数据集包含2000个YouTube视频,平均时长5.26分钟,总共176小时。 视频有手动标注的分割边界和 caption。 平均每个视频有 7.7 个片段,每个 caption 有 8.8 个单词。 使用提供的数据集 split,其中 1333 个视频用于训练,457 个用于验证。 为了避免训练前的潜在偏见,还从训练前集中删除了任何出现在YouCook II中的视频。
4.2 视频和语言预处理
对于每个输入视频,我们以20 fps 采样帧,并从视频上30帧(1.5秒)的非重叠窗口创建剪辑。 对于每一个 30 帧的剪辑,使用一个预先训练的 video ConvNet 来提取特征。使用 S3D (Rethinking Spatiotemporal Feature Learning: Speed-Accuracy Trade-offs in Video Classification),它将可分离的时序卷积添加到一个 Inception network (Going Deeper with Convolutions) backbone中。在最终的线性分类器之前进行特征激活,并使用 3D 平均池化来获得 1024 维的特征向量。其中,S3D 是在 Kinetics 数据集上进行预训练的,该数据集蕴含了 YouTube 视频中的广泛行为,并作为每个个体剪辑的通用表示。
使用层次 Kmeans 来 tokenize 视觉特征,通过视觉检查簇的一致性和代表性来调整层次 d d d 的数量和每个层次 k k k 的簇的数量。设置 d = 4 d=4 d=4, k = 12 k=12 k=12,共产生 1 2 4 = 20736 12^4=20736 124=20736 个团簇。 Figure 4 说明了这个 “矢量量化” 过程的结果。

对于每个 ASR 单词序列,使用一个现成的基于 LSTM 的语言模型通过添加标点符号将 WordPieces 分解成句子。 对于每个句子,遵循 BERT 的标准文本预处理步骤,并将文本标记为单词。 这里作者使用 BERT 的作者提供的相同词汇表,其中包含 30,000 个 tokens。
与语言可以自然地分解成句子不同,如何将视频分解成语义一致的片段尚不清楚。 作者使用一个简单的启发式来解决这个问题:当 ASR 语句可用时,它与开始和结束时间戳相关联,我们将该时间段中的 video tokens 视为一个片段。 当 ASR 不可用时,简单地将 16 个 tokens 视为一个片段。
4.3 模型预训练
我们从一个文本预训练的 checkpoint 初始化 BERT 权重。具体来说,使用作者发布的 B E R T L a r g e BERT_{Large} BERTLarge 模型,使用相同的 backbone 架构:它有 24 层 Transformer blocks,其中每个 block 有 1024 个隐藏单元和 16 个 self-attention heads。
作者增加了对 video tokens 的支持,为每一个新的 “visual words” 在 word embedding 查找表中添加了 20736 个条目。 用它们相应的聚类中心的 S3D 特征初始化这些条目。 在预训练期间,输入的 embedding 被冻结。
模型训练过程基本上遵循BERT的设置:在 Pod 配置中使用 4 个Cloud TPUs,总 batch size 为 128,训练模型进行 50 万次迭代,大约 8 个epoch。 使用 Adam 优化器,初始学习速率为 1e-5,学习速率为线性衰减。 训练大约需要2天。
4.4 zero-shot 动作分类
预训练后,VideoBERT 就可以用于对新数据集(如 YouCook II)进行 zero-shot 分类(zero-shot 就是指该模型在预训练过程中并没有使用 YouCook II 上的数据,即模型是在其他数据集上进行训练的,而在测试时直接迁移在 YouCook II 上进行分类)。 更准确地说,我们要计算 p ( y ∣ x ) p(y\mid x) p(y∣x),其中 x x x 是序列 visual tokens, y y y 是一个单词序列。由于模型被训练来预测句子,我们定义Y为固定句子,“now let me show you how to [MASK] the [MASK],” 从第一个和第二个 mask 掉的位置中预测的 tokens 中分别提取动词和名词标签。有关一些定性结果,请参见 Figure 5。

对于定量评估,使用 YouCook II 数据集。 在 Weakly-Supervised Video Object Grounding from Text by Loss Weighting and Object Interaction 中,作者为 YouCook II 的验证集收集了 63 个最常见对象的 ground truth 的 bounding box。但是,没有针对动作的 ground truth 标签,许多其他常见对象也没有标签。 因此,作者收集来自 ground truth caption 的动作和对象标签来解决这个缺点。在 ground truth caption 上运行了一个现成的词性标记器,以检索 100 个最常见的名词和 45 个最常见的动词,并使用这些来导出 ground truth。虽然 VideoBERT 的 word piece 词汇表使其能够有效地进行 open-vocabulary 分类,但它更有可能做出语义上正确的预测,而这些预测与更有限的 ground truth 并不完全匹配。 因此,作者展示了 Top-1 和 Top-5 分类精度度量,其中后者旨在缓解这一问题,将更复杂的评估技术留给未来的工作。 最后,如果有一个以上的动词或名词与视频剪辑相关联,我们认为一个预测是正确的,如果它符合其中任何一个。作者展示了在YouCook II验证集上的性能。

Table 1 展示了 VideoBERT 及其消融的 top-1 和 top-5 的准确性。为了验证 VideoBERT 实际上使用了视频输入,首先删除了 VideoBert 的视频输入,并仅使用语言模型 p ( y ) p(y) p(y) 来进行预测。还使用了纯文本 BERT 模型中的 language prior,这在烹饪视频中没有 fine-tune。 可以看到,VideoBERT 的表现明显优于这两个 baseline。 不出所料,VideoBERT 的 language prior 适用于烹饪的句子,并优于 Vinilla BERT。
然后,作者与使用 YouCook II 的 training split 训练的全监督分类器进行了比较。 使用预先计算的 S3D 特征(与 VideoBERT 的输入相同),随着时间的推移使用平均池化,然后是一个线性分类器。如 Table 1 所示,监督框架在动词精确度上超过了VideoBERT,这并不奇怪,因为 VideoBERT 有一个有效的开放词汇表。 (请参见图5以说明动作标签的模糊性。)然而,前5名的精度度量显示,VideoBERT在不使用 YouCook II 的任何监督的情况下,实现了与完全监督的 S3D baseline 相当的性能,这表明该模型能够在这种 zero-shot 中具有竞争力。
4.5 大型训练集的好处

如 Table 2 所示,研究了预训练数据集大小对模型性能的影响。 在这个实验中,从预训练集中随机抽取 10K、50K 和 100K 视频子集,并使用与上面相同的设置对 VideoBERT 进行预训练,时间相同。可以看到,随着数据量的增加,精度单调地增长,没有饱和的迹象。 这表明VideoBERT可能受益于更大的预训练数据集。
4.6 迁移学习 captioning
我们进一步证明了VideoBERT作为特征提取器的有效性。为了提取仅给定视频输入的特征,我们再次使用一个简单的填空任务,将 video tokens 附加到模板句子中 “now let’s [MASK] the [MASK] to the [MASK], and then [MASK] the [MASK].” 通过提取 video tokens 和 mask 掉的 text tokens 的特征,对它们求平均值,并将两者连接在一起,供下游任务中的有监督模型使用。
作者评估了 video captioning 上提取的特征,遵循 End-to-End Dense Video Captioning with Masked Transformer 的设置,其中 ground truth 视频片段用于训练一个有监督的模型,将视频片段映射到 captions。 作者使用与他们相同的模型,即Transformer encoder-decoder,但用来自 VideoBERT 的特征替换了 encoder 的输入。 作者还将 VideoBERT 特征与平均集合的 S3D 特征串联起来;对于 baseline,考虑只使用 S3D 的特征而不使用 VideoBERT 的特征。在参数等方面:
- Transformer block layer 设为 2
- 隐藏单元大小设为 128
- Dropout 概率设为 0.4
- 在 training split 上使用 5 折交叉验证来设置超参数,并在验证集上反馈性能
- 对该模型进行了40K 次迭代训练
- batch size 为 128
- 使用与 VideoBERT 预训练相同的 Adam 优化器,并将初始学习速率设置为 1e-3,并且使用线性衰减的调度器 (linear decay schedule)

如 Table 3 所示,作者遵循机器翻译的标准做法,在语料库水平上计算BLEU和METEOR分数的微平均值 (micro-averaged),也计算了 ROUGE-L 和 CIDEr 分数。 对于 baseline 方法(即 End-to-End Dense Video Captioning with Masked Transformer),使用作者提供的预测重新计算度量。 我们可以看到,VideoBERT 一直优于 S3D baseline,尤其是 CIDEr。 我们还可以看到,跨模态预训练优于 video only 的版本。 此外,通过将来自 VideoBERT 和 S3D 的特征连接起来,该模型在所有评价指标中都达到了最佳性能。
如 Figure 6 所示,展示了一些定性结果。我们注意到,预测的单词序列很少完全等于 ground truth,这解释了为什么 Table 3 中计算 n-gram 的指标的绝对值都很低。 然而,从语义上看,结果似乎是合理的。
5 结论
本文采用强大的 BERT 模型来学习视频的 视觉-语言 联合表征。 实验结果表明, VideoBERT 能够学习高级语义表示,并且在YouCook II数据集上的 video captioning 性能优于 SOTA。 还证明了该模型可以直接用于 open-vocabulary 分类,并且它的性能随着训练集的大小而单调增长。
这项工作是朝着学习这种联合表征方向迈出的第一步。 对于包括烹饪在内的许多应用,使用空间细粒度的可视化表示非常重要,而不仅仅是在帧或剪辑级别上工作,这样我们就可以区分单个目标及其属性。 我们设想要么使用预训练的目标检测和语义分割模型,要么使用无监督技术来实现更广泛的覆盖。
除了改进模型,作者还计划评估在其他视频理解任务上的方法,以及除了烹饪之外的其他领域。 (例如,可以使用最近发布的人工标记教学视频的 COIN 数据集)作者对从视频和语言中进行大规模表征学习的未来前景相当看好。