CVPR2017_Unsupervised Learning of Depth and Ego-Motion from Video
这是一篇从一段视频中恢复场景深度和相机pose的论文。
他可能是第一篇用深度学习的方法从一段视频中恢复camera的pose的方法,它用两个网络(严格意义上是3个网络,下文赘述)分别/独自无监督地估计单帧的深度,和视频序列中的camera的pose变化。最终得到的深度达到state of art,pose的精度也与ORB-SLAM2的localization模式(即没有丢失后的重定位以及以关键帧的全局BA为核心力量的回环检测)效果相当。

Q1:pose估计是怎么找到的?
A1:在已知当前帧depth,以及当前帧poses转换到将一个图像序列(视频)中其他帧的情况下,我们知道,可以将当前帧的每一个像素映射到其他帧上,然后最小化当前帧和其他帧映射位对应位置的光度误差来求出这些pose.
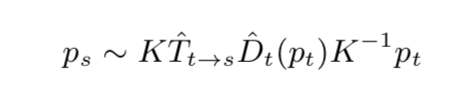
Q2:那么先验深度预测怎么求出?
A2:本文的框架为联合训练depth和pose,因此我猜测是在分别给定depth和pose一个初始值下,然后联合训练整个网络得到最终的depth和pose。虽然是联合训练,但最终得到的是两个模型:一个depth模型,一个pose模型。
1.简介
所谓无监督,是指它利用的是一帧时间相邻的图像帧进行视图合成(View synthesis )——对于某一目标帧It,用视频所有其他剩余帧,将这些帧中像素位置映射到目标帧It中。
无监督地估计深度的网络采用和DispNet相似的架构,输入是某一单帧It,输出其对应的深度图(实际上这个过程需要用到pose网络得到的pose)。作者尝试用多张图像来联合恢复深度(方法和《DeMoN: Depth and Motion Network for Learning Monocular Stereo》相同),但发现对精度没有提升。
估计pose的网络的输入是一张目标图像,以及其(时间上)附近的图像序列Is(s=t-1,t+1,t-2,t+2,…),输出目标图像到附近的这些图像的位姿(欧拉角和位移(pose共6个自由度))。
利用以上得到的深度和位姿,将图像It上的图像块warp到Is,并通过卷积网络来最小化It与Is的总的光度误差,得到最终的pose。
2.价值函数
视频序列中的某单帧估计深度,用类似于于SLAM直接法的方式来获得帧A与帧B之间的像素灰度值差异:
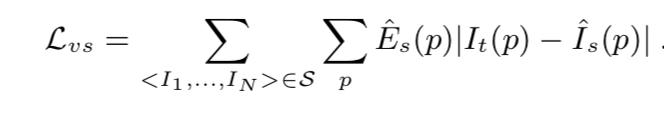
并对映射后的点进行双线性插值来获取灰度值。
由于光度一致性的假设是:图像中没有物体移动;图像图像没有遮挡;反射是漫反射(diffuse)。如果假设不成立,图像梯度会出现跳跃。这可能导致训练失败。
为了避免这种情况,文章额外用了一个“解释性网络”来估计每个target和source图片对的mask,用这个mask(相当于target图像与每一个source图像组成的图像对都有一个mask)来降低弱纹理的图像部分的权重。其网络结构形似pose网络(如图1),与pose共享前4层网络,随后分开分别求解释性pose和mask(可认为得到的mask大小为层数x(N-1),即与其他所有帧,每两帧共享一层,Es就是每层中的数值。)
于是上述的灰度差值的损失函数为:
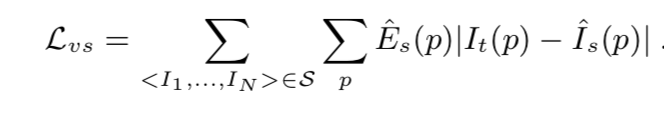
为了避免Es最终被优化为0,给Es添加了形如softmax的交叉熵的正则项
为了输出(不论是深度还是视差)在图像分布中平滑,特别为了解决低纹理或估计值离真值太远时会造成梯度为0或梯度错误的情况,大家一般会有两种思路:将周围的梯度传递给当前像素;和其他无监督方法一样用一个表征平滑度的正则化。本文受SfmNet启发,采用后一种方案。作者是用深度图的二阶梯度的L1的正则项来提取平滑信息。
所以最终的代价函数:
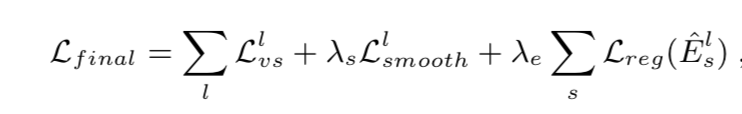
3.网络实现
depth估计如图:每层跟batch normalization和relu。
训练时用了Adam。
最终网络结构如图:

4.试验结果
最后结果如图:

如图,可见该网络不如Godard的左右一致性检查一文的结果。作者认为原因可能是由于Godard所谓的左右一致性本质上是已知两帧之间的pose,而当前的深度预测是基于预测的不精确的pose。
不过要想到,本文的深度其实是一个中间值(intermediate value),它的主要公用是用于pose估计。
此外,作者提到他们的解释网络没有很好地表现,可能是因为测试集中图像大多是静态的图,中没有太多遮挡的情况(遮挡的情况大多3帧内就会消失),但发现他们的解释网络具有良好的预测图像动态部分能力。
作者最后认为当前还可以从以下几个方面进步:
- 没有考虑实际环境中可能出现的物体移动和遮挡。当然作者提到可以借鉴 motion segmentation的工作成果,这也是上次组会导师提到的参考方向。
- 目前还需要内参已知,如果利用往上随处可获得的video来估计(内参不知)?
- 用更加好的深度预测(我认为这也是pose估计一个很核心的任务。有了更好的三维点,就有更小的重投影误差),比如利用体素