文章目录
一、聚类分析
1. 概述
- 聚类分析(cluster analyses)可作为一种定量方法,从数据分析的角度,给出一个准确、细致的分类工具。
2. 相似性度量
2.1. 样本的相似性度量
1. 重点内容
- 核心思想:用距离来度量样本点间的相似程度。距离近的样品聚为一类。
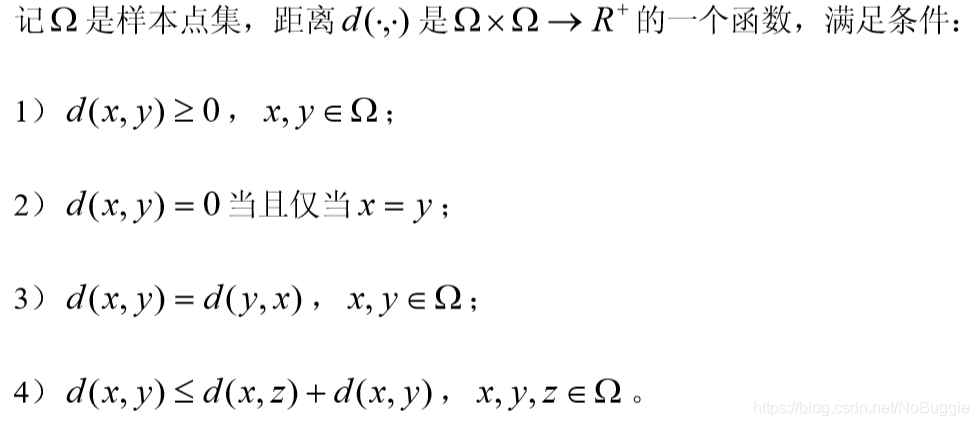
- 在聚类分析中,对于定量变量,常用的是 Minkowski 距离
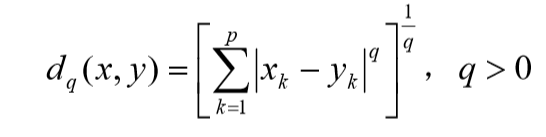

- 在 Minkowski 距离中,常用的是欧氏距离,它的主要优点是当坐标轴进行正交旋转时,欧氏距离是保持不变的。因此,如果对原坐标系进行平移和旋转变换,则变换后样本点间的距离和变换前完全相同。
- 采用 Minkowski 距离时,一定要采用相同量纲的变量。如果变量的量纲不同,测量值变异范围相差悬殊时,建议首先进行数据的标准化处理,然后再计算距离。
- 在采用 Minkowski 距离时,还应尽可能地避免变量的多重相关性。多重相关性(multicollinearity)所造成的信息重叠,会片面强调某些变量的重要性。
- 由于 Minkowski 距离的这些缺点,一种改进的距离就是马氏距离,定义如下:
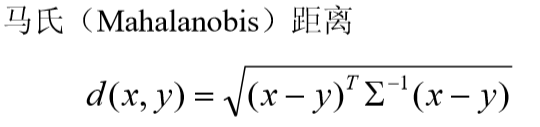
其中x, y为来自p 维总体Z的样本观测值,Σ为Z的协方差矩阵,实际中Σ往往是不知道的,常常需要用样本协方差来估计。马氏距离对一切线性变换是不变的,故不受量纲的影响。 - 此外,还可采用样本相关系数、夹角余弦和其它关联性度量作为相似性度量。
2. 示例
下图是数据的一般格式
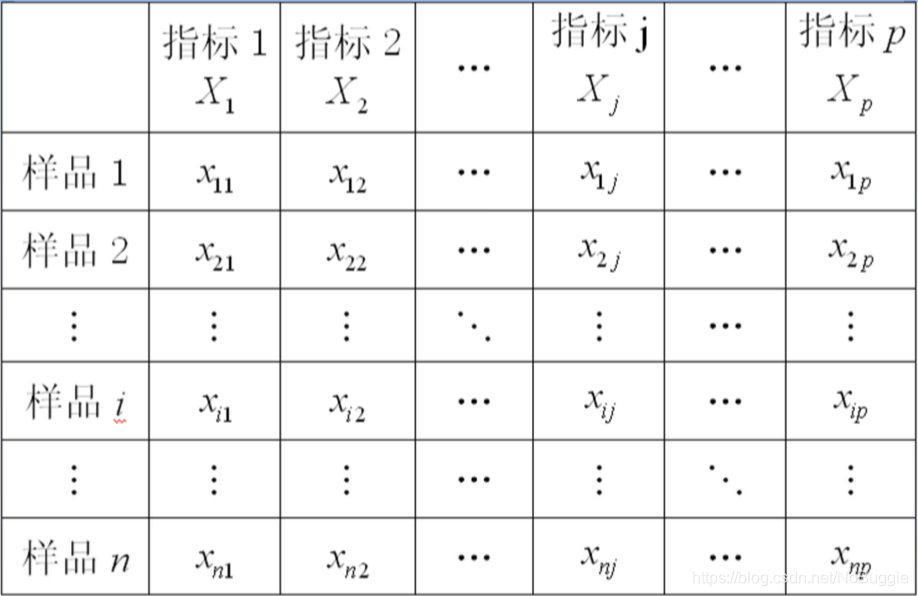
则样品与样品之间的常用距离(样品i与样品j)

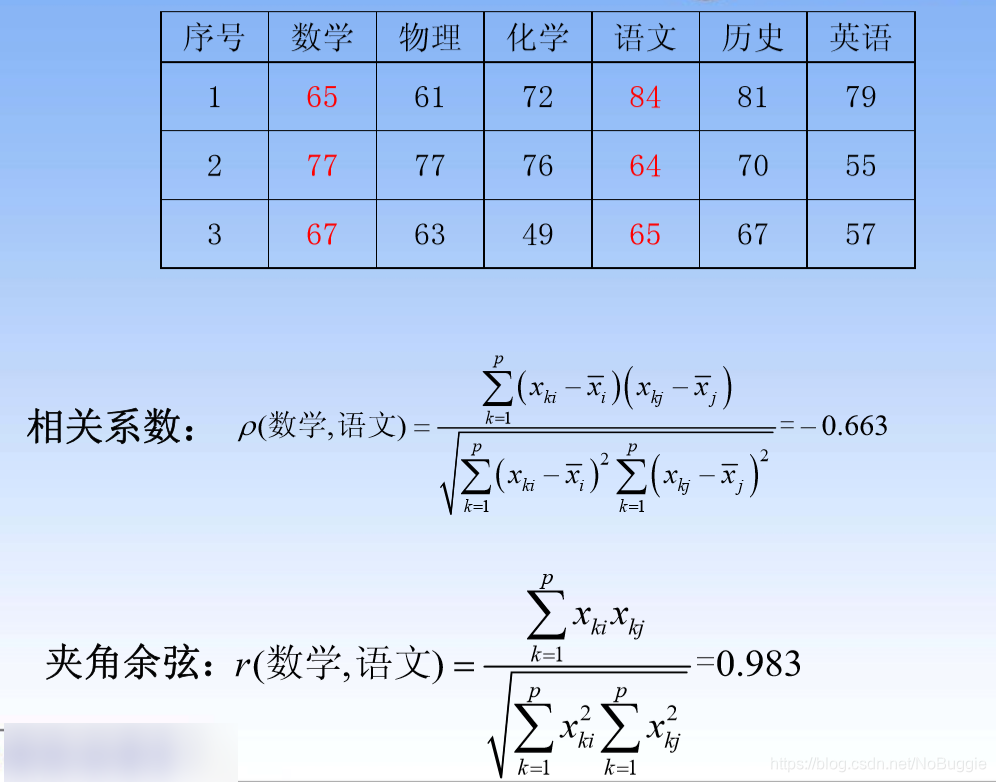
示例计算:

指标与指标之间的常用“距离”(指标i与指标j)
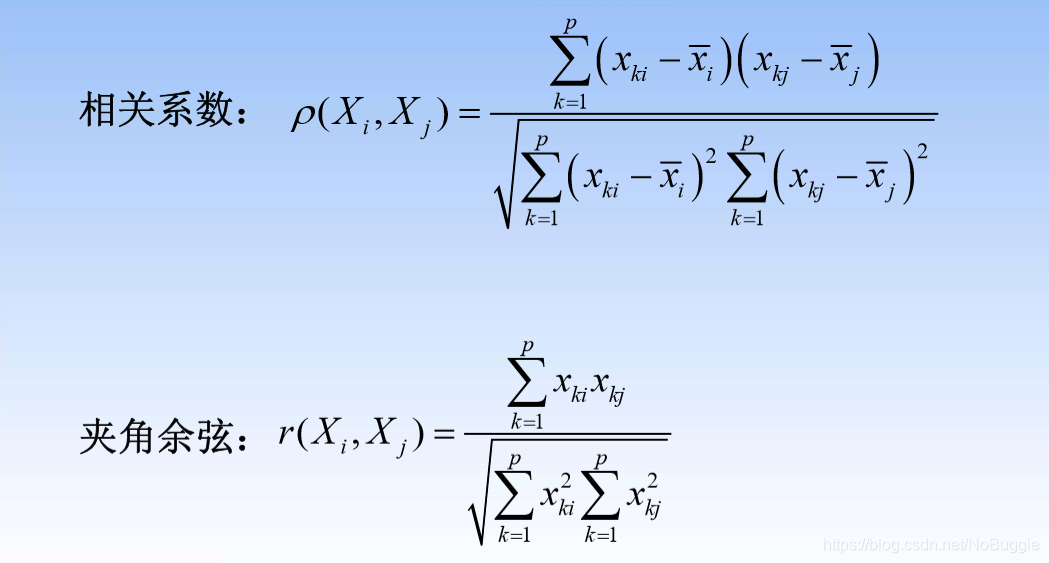
示例计算
2.2. 类与类间的相似性度量
1. 度量方法
- 由一个样品组成的类是最基本的类。如果每一类都由一个样品组成,那么样品间的距离就是类间距离。
- 如果某一类包含不止一个样品,那么就要确定类间距离,类间距离是基于样品间距离定义的。如果有两个样本类G1和G2,我们可以用下面的一系列方法度量它们间的距离:
-
最短距离法(nearest neighbor or single linkage method)
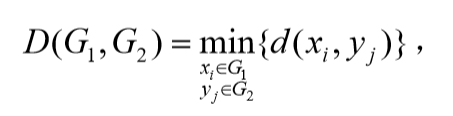
它的直观意义为两个类中最近两点间的距离。 -
最长距离法(farthest neighbor or complete linkage method)
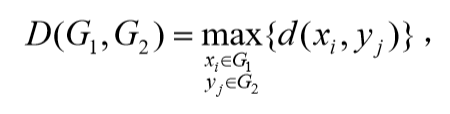
它的直观意义为两个类中最远两点间的距离。 -
重心法(centroid method)
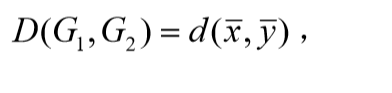
其中 , 分别为G -
类平均法(group average method)
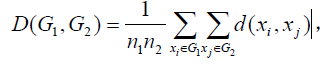
它等于G1 ,G2中两两样本点距离的平均,式中n1 , n2 分别为G1 ,G2中的样本点个数。 -
离差平方和法(sum of squares method)
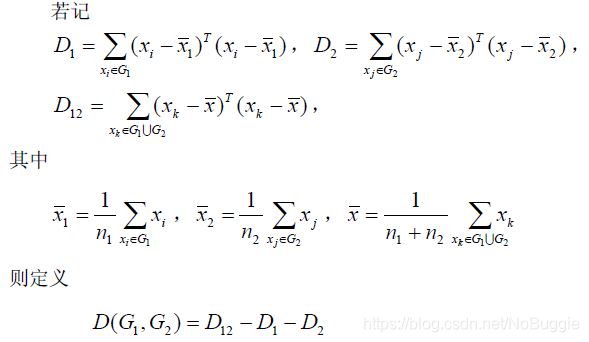
事实上,若 G1 ,G2内部点与点距离很小,则它们能很好地各自聚为一类,并且这两类又能够充分分离(即D12很大),这时必然有D = D12 − D1 − D2 很大。因此,按定义可以认为,两类G1 ,G2之间的距离很大。
-
2. 更形象化地表达
2.2. 系统聚类法
1. 概述
系统聚类法是聚类分析方法中常用的一种方法。它的优点在于可以指出由粗到细的多种分类情况,典型的系统聚类结果可由一个聚类图展示出来。
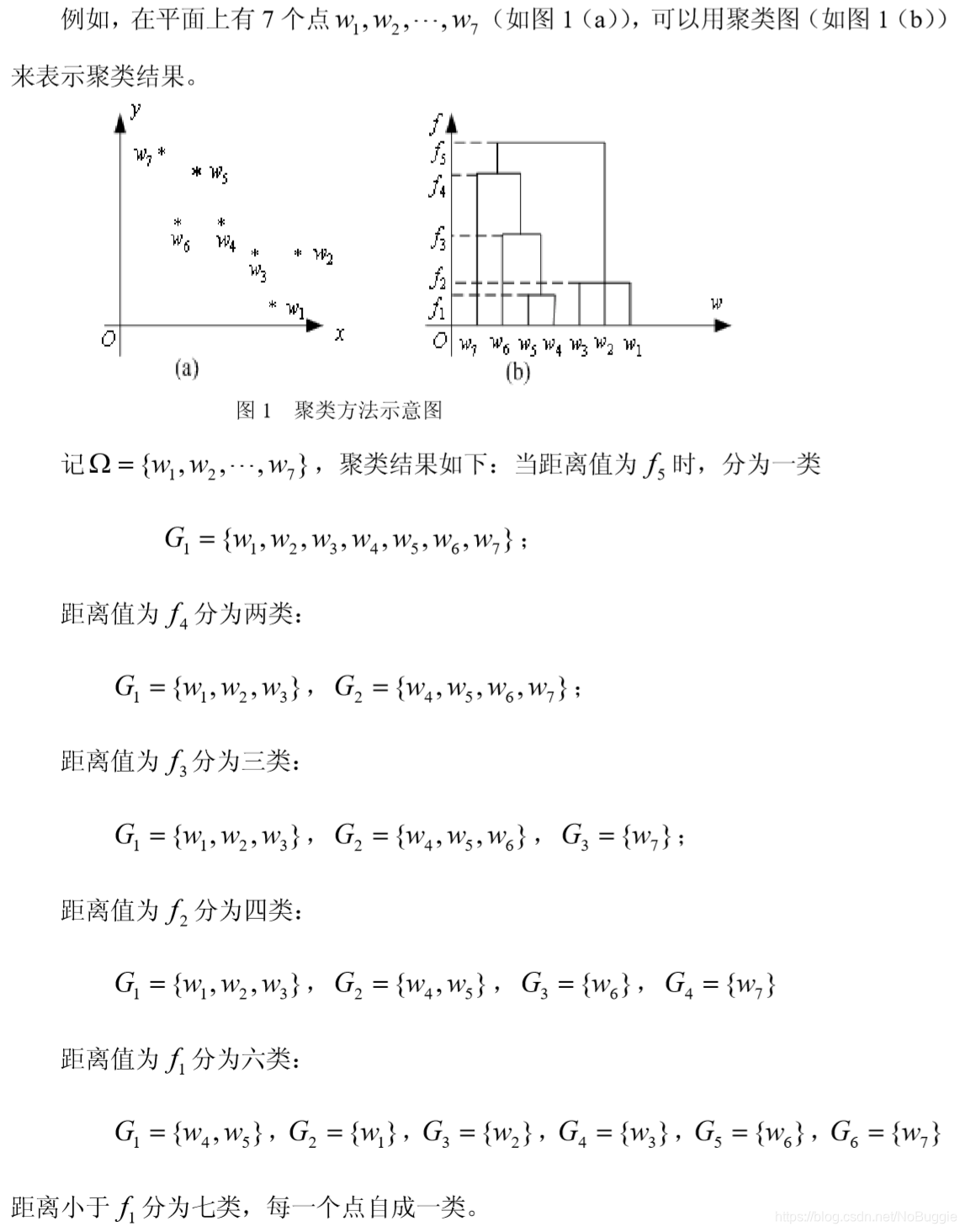
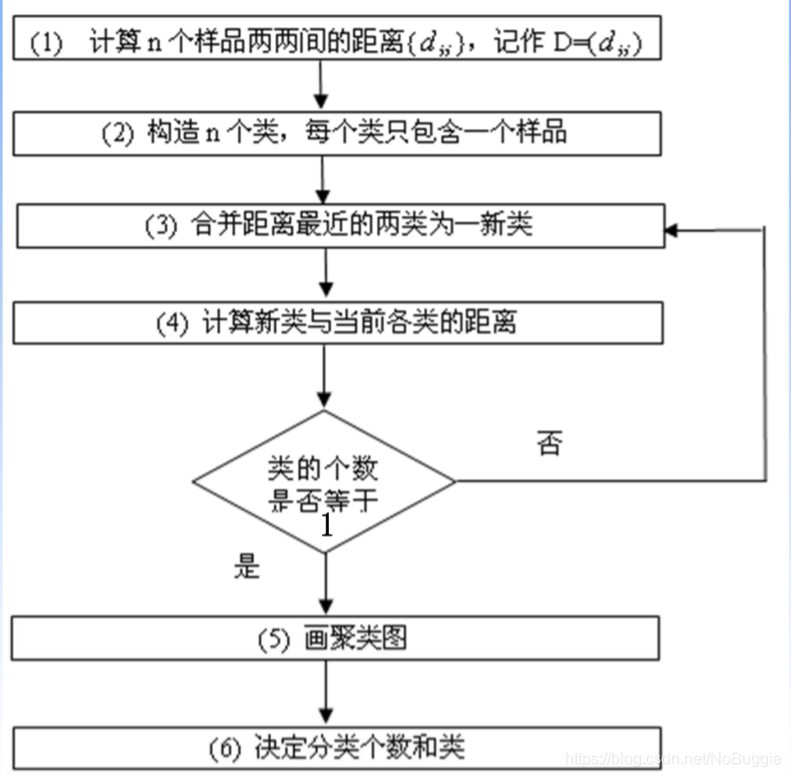
如何才能生成这样的聚类图呢?,其步骤如下:
显而易见,这种系统归类过程与计算类和类之间的距离有关,采用不同的距离定义,有可能得出不同的聚类结果。
2.最短距离法
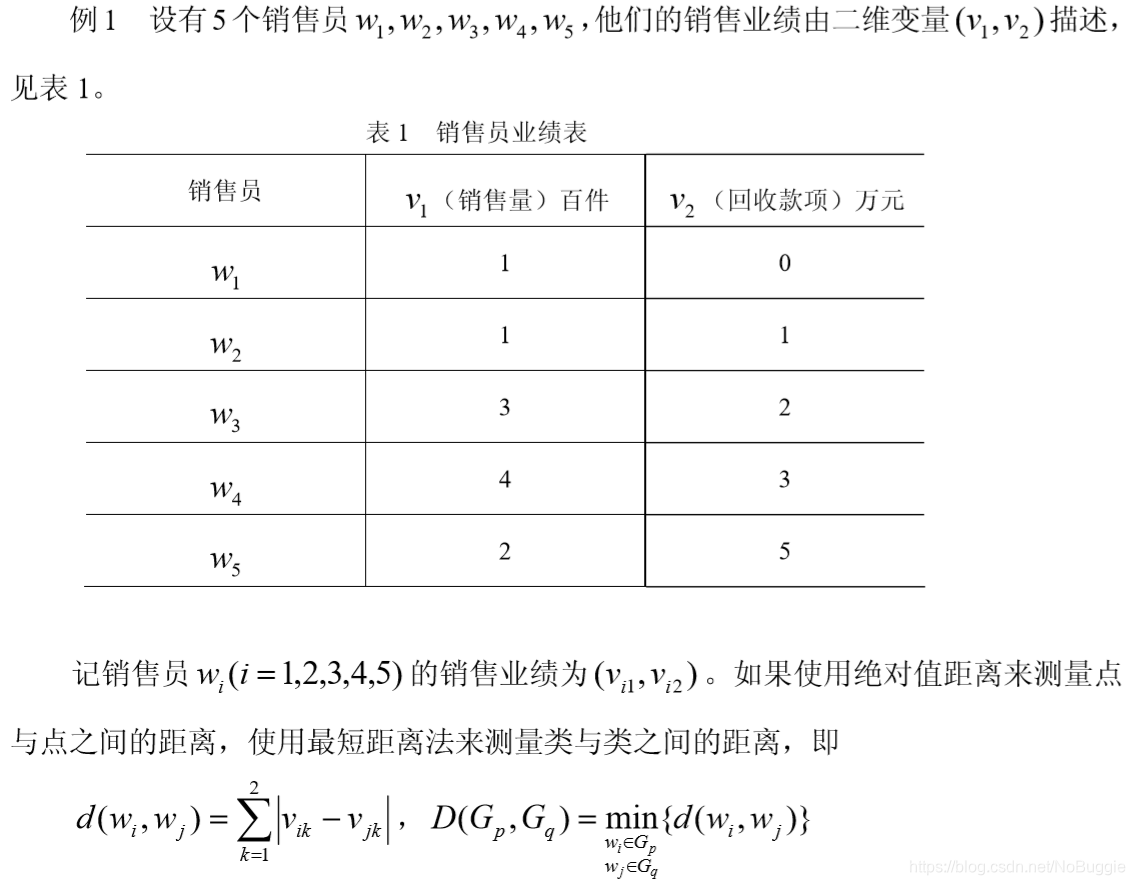

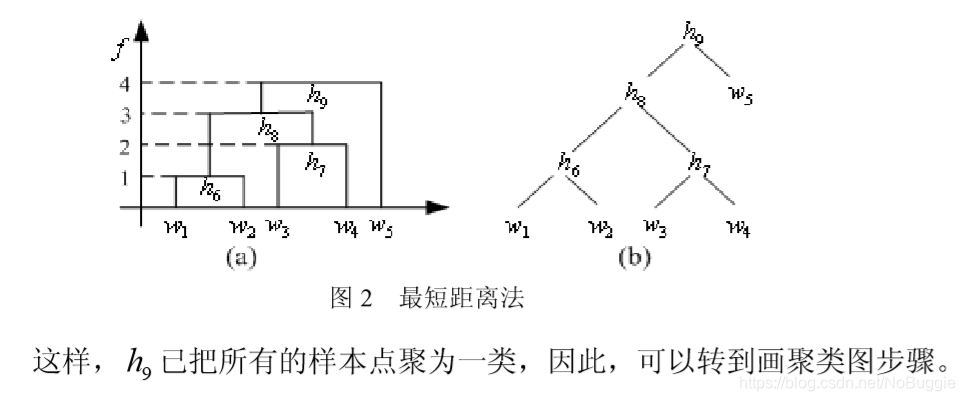
有了聚类图,就可以按要求进行分类。可以看出,在这五个推销员中w5的工作成绩最佳,w3w4的工作成绩最好,而w1w2的工作成绩较差。
