百度飞桨从零实践强化学习第五天
这里是三岁,这个课程最后一节大课啦,时间飞快,三岁百话的时间又不多啦,好好珍惜吧!
连续动作空间上求解RL
连续动作 vs 离散动作
- 离散动作是可数的无论多大都是可以数的
- 连续的动作是不可数的而且生活中大部分情况是不可数的
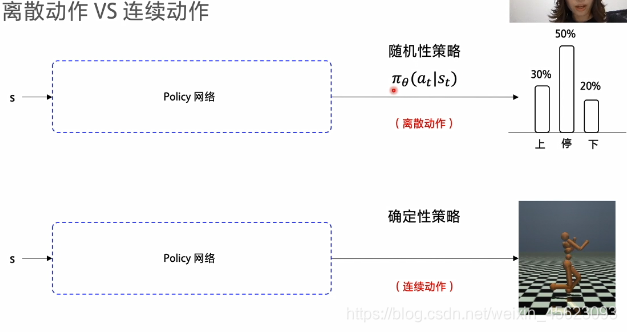
随机型策略:通过神经网络获得一个最佳的概率输出的值不少固定的是一个概率P(所有概率之和为一)
确定性策略:通过神经网络以后经过训练,只要再输入相同的值输出的结果是固定的
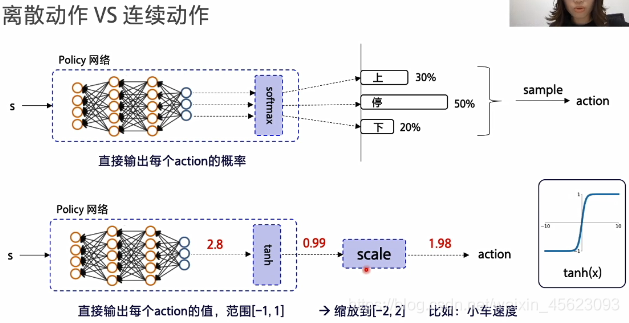
离散型动作概率输入神经网络通过softmax函数获得一个概率,并且加和为一。
连续的动作概率输入神经网络通过softmax函数进行映射使得数据在[-1,1]之间。通过实际要求做缩放再给环境。
DDPG
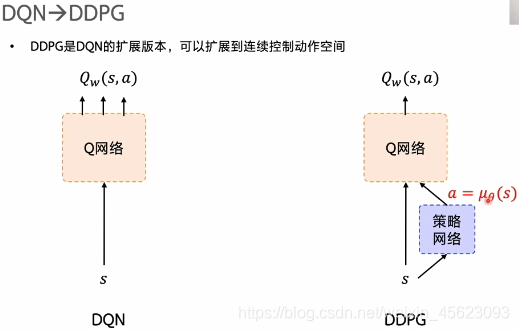
DDPG在原来的DQN网络上进行了增加使得原本的只能够处理离散型数据装换成了可以处理连续型的数据的模型。在原先的基础上添加了一个策略网络,使得机器一边学习网络一边学习策略,称为Actor-Critic结构,他需要通过Q网络的结果来调整自己的策略,不断更新自己的值,Q网络则需要通过环境的反馈进行调整 不断改变结果,尽可能的获得更高的收益。
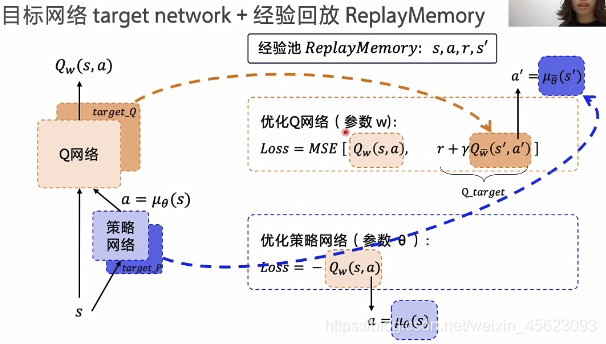
(目标网络的计算)
PARL DDPG的代码解析
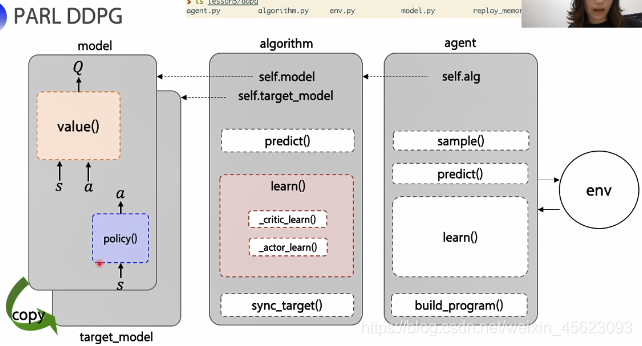
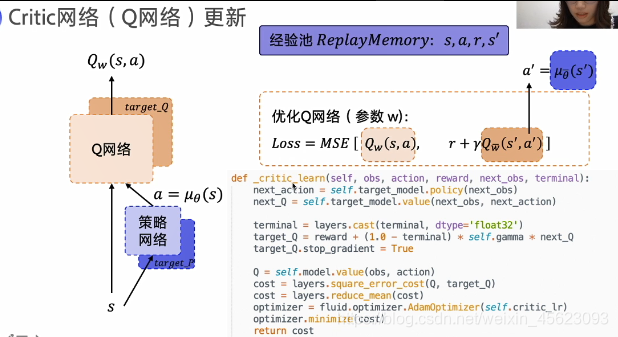

总结
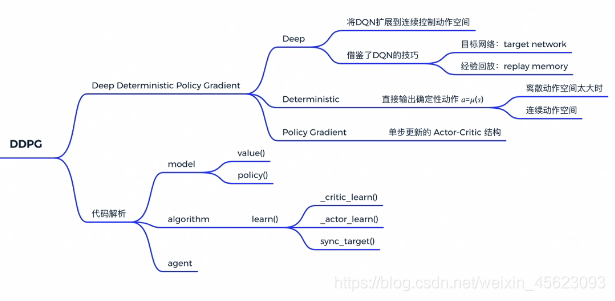
大作业
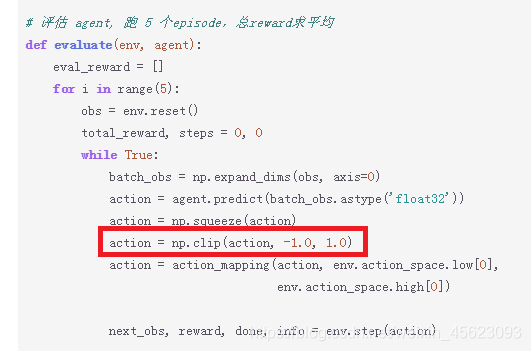
问题1AssertionError: the action should be in range [-1.0, 1.0]
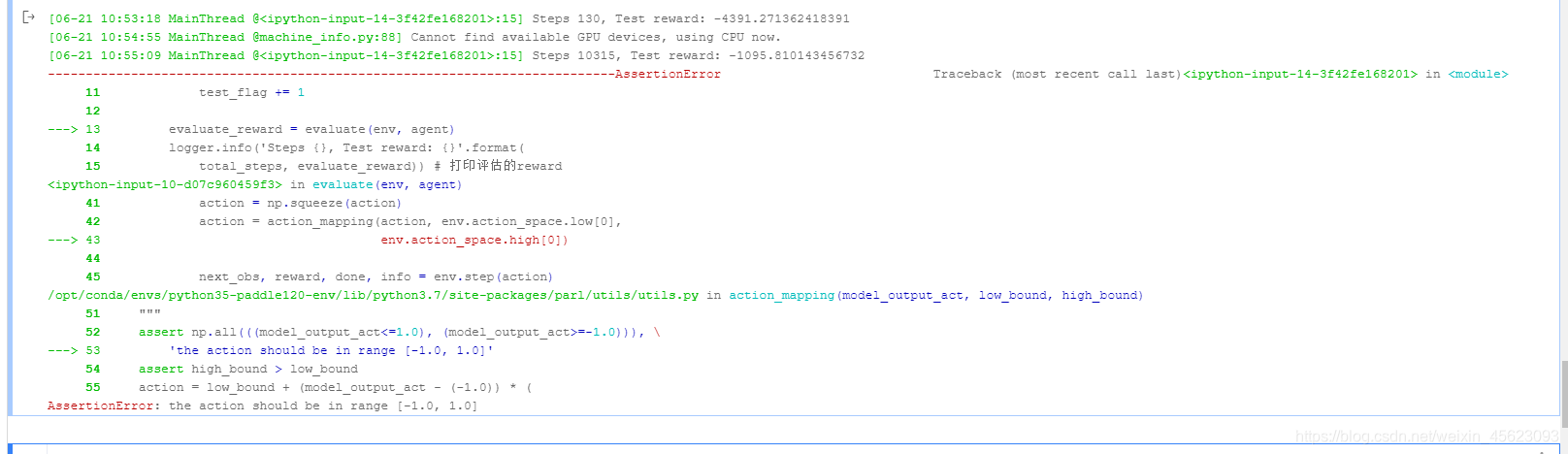
这个报错大家应该都经历了
在Step4 Training && Test(训练&&测试)中第41行后需要增加限幅
action = np.clip(action, -1.0, 1.0)
结果展示
这里感谢一下提出解决方法的大佬!

谢谢大佬!!!
问题2 类库安装失败
看了讨论区有许多非常棒的小哥哥小姐姐给出了好的答案,我就厚着脸皮copy啦,谢谢小哥哥小姐姐们
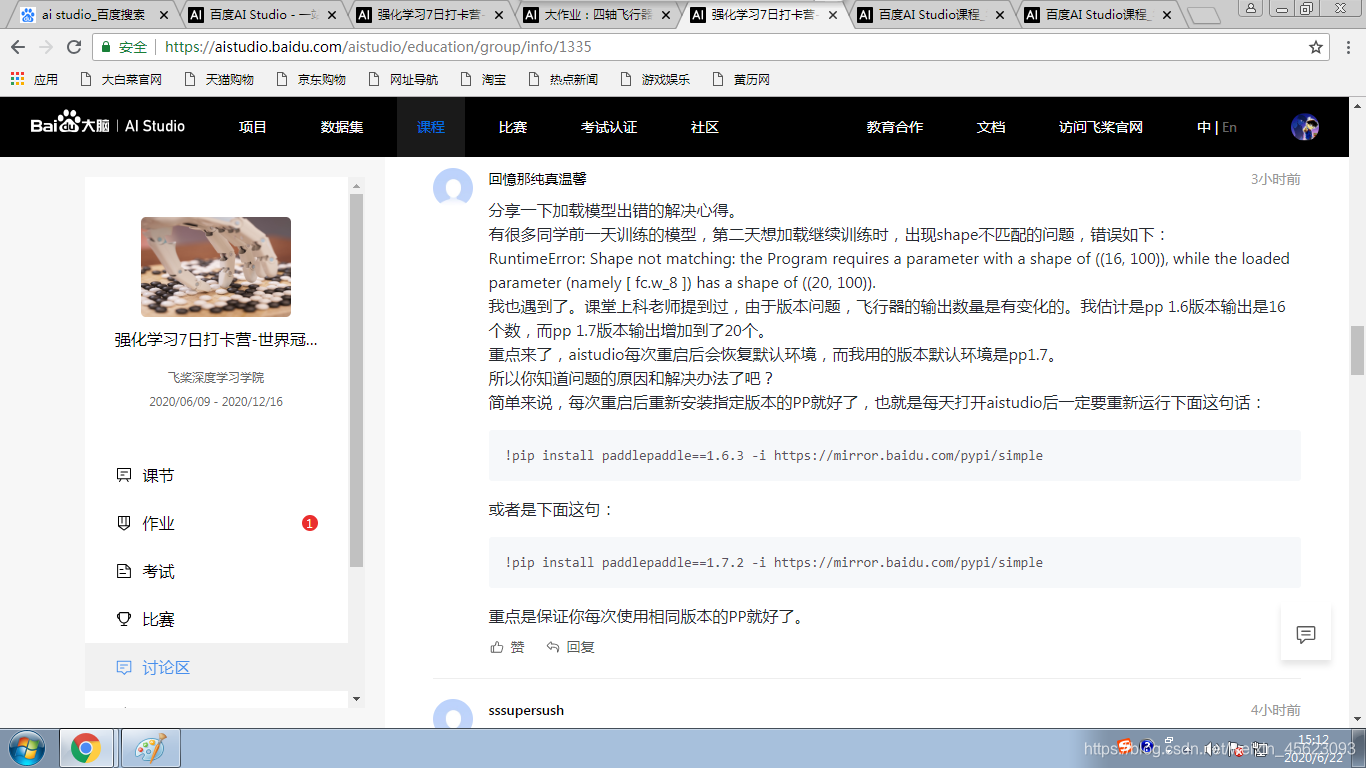
!pip install paddlepaddle==1.6.3 -i https://mirror.baidu.com/pypi/simple
或
!pip install paddlepaddle==1.7.2 -i https://mirror.baidu.com/pypi/simple
还有就是下载安装失败,需要添加国内的源
-i + 源地址
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
华中理工大学:http://pypi.hustunique.com/
山东理工大学:http://pypi.sdutlinux.org/
豆瓣:http://pypi.douban.com/simple/
评论区小编认为不错的东西,分享分享
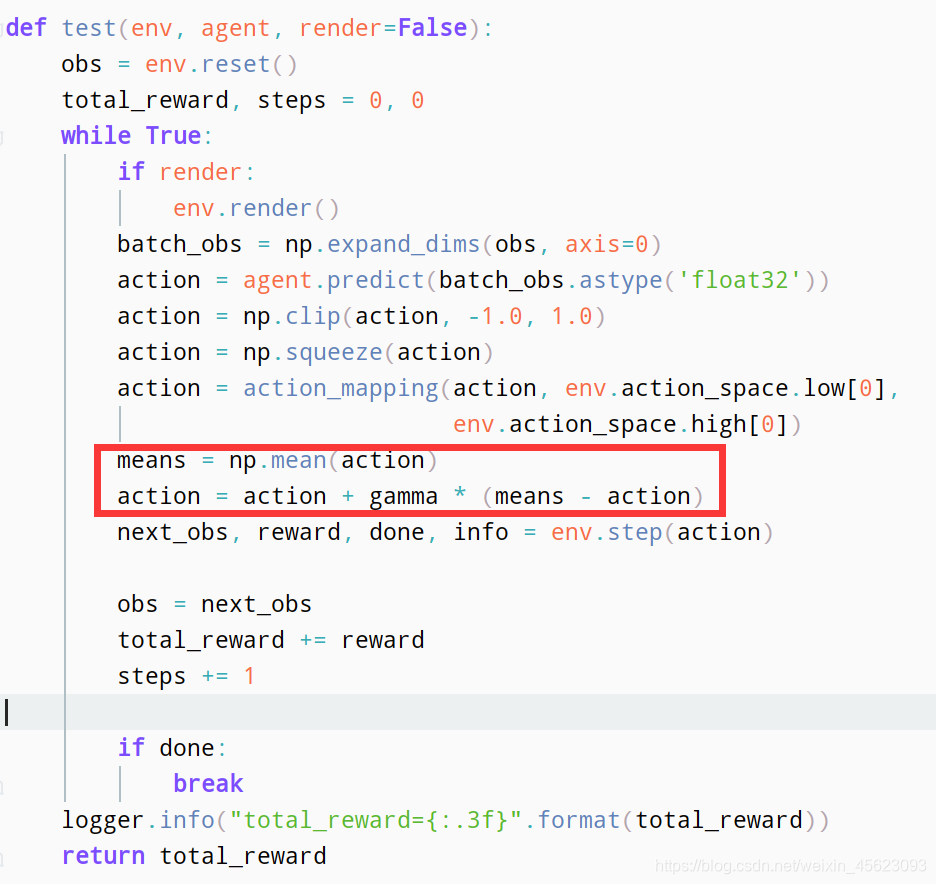
这里面在Step3 设置超参数里面设置 gamma的提前预设值为0.2(可以自己调整)
# Step3 设置超参数
gamma=0.2
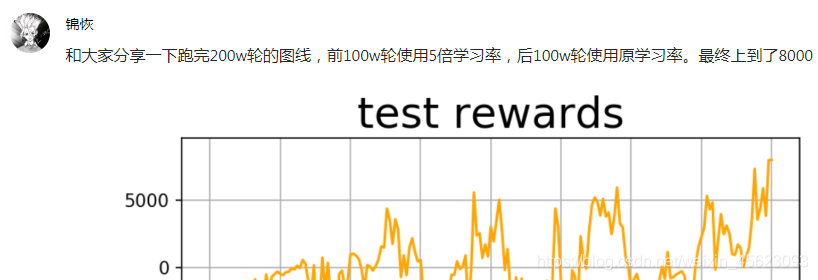
感谢大佬的无私分享。
三岁也还在跑程序革命还没有成功只能够如此啦,希望有所帮助,感谢大家的支持,如果可以点赞关注收藏留言。
这里是三岁,感谢您嘞!