三岁在架构师带你零基础实践深度学习的第一天
大家好这里是小白三岁,参加了百度飞桨的课程《百度架构师手把手带你零基础实践深度学习》,又开始了三岁的白话叨叨叨,虽然是0基础实践课程但是此’hello world’非彼’hello world’还需大家一起努力。
观前提示:小白眼光,不好勿喷,请指出必认真修改。
课程地址:https://aistudio.baidu.com/aistudio/education/group/info/1297?activityId=5&directly=1&shared=1(温馨提示:个别账号请登录后查看)
学习利器
paddlepaddle
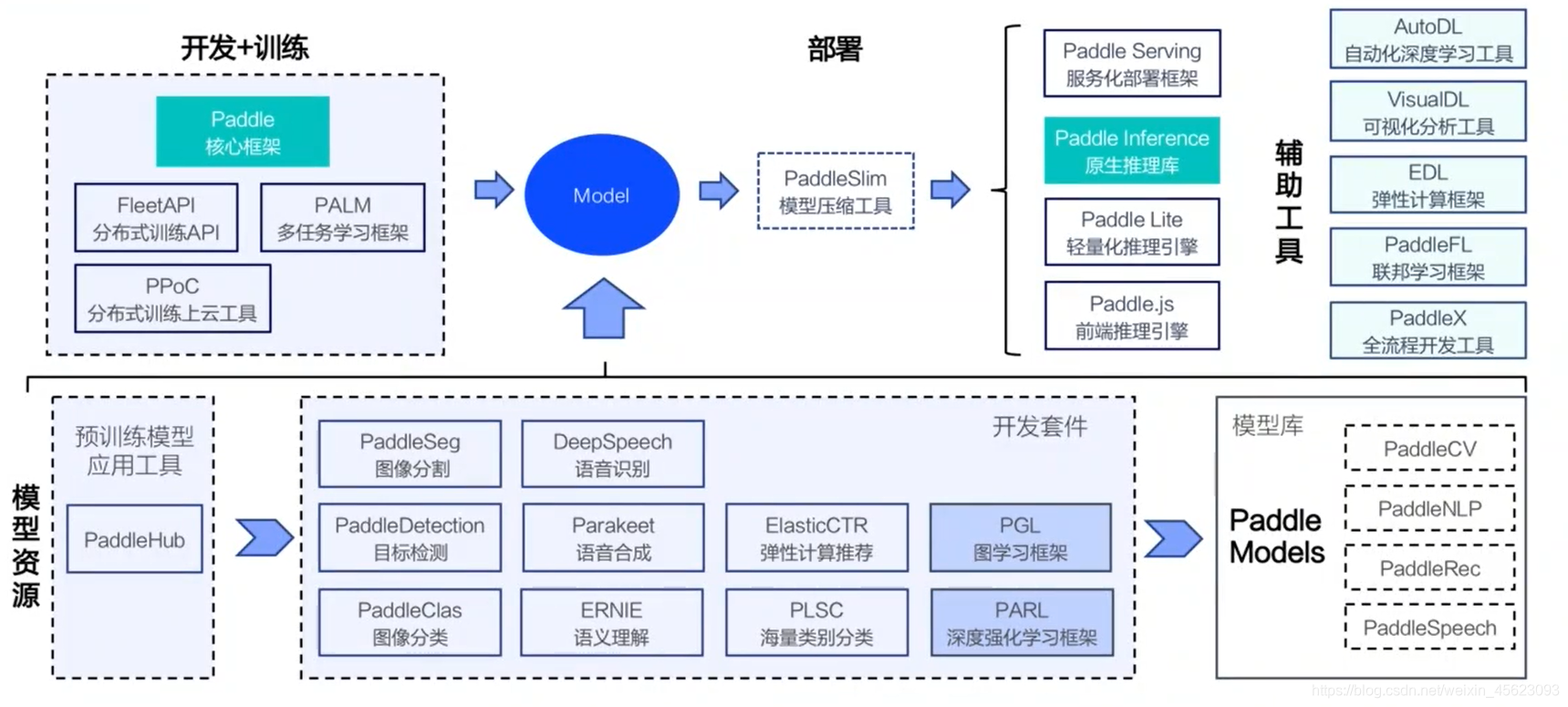
paddle是百度开源深度学习框架,有了他妈妈再也不用担心我学深度学习秃头了。
- 官网地址:https://www.paddlepaddle.org.cn/
- API文档地址:https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/index_cn.html
AI Studio
线上学习,线上环境运行,paddle适配,高算力支持,深度学习认证平台……
一切应有尽有,就在这里。
为什么要说这两个东西?
因为:
他们是巨人
我们在他的基础上,进步成长。
人工智能&机器学习&深度学习
三者的关系:人工智能 > 机器学习 > 深度学习

- 人工智能:倒是像是一个更广泛的概念,只要是有人类特性的(包括行为思维,处理文题的方式……)机器、程序、代码都算是人工智能(AI)的一环。
- 机器学习:个人认为就是使用机器对人的行为进行模仿(主要是对认知事物的过程)利用训练和测试,反馈不断提高训练的效果及质量
- 深度学习:使用神经网络(复杂的神经模型)来识别一些难以识别的东西如图片,声音等。
hello world 之波士顿房价预测任务
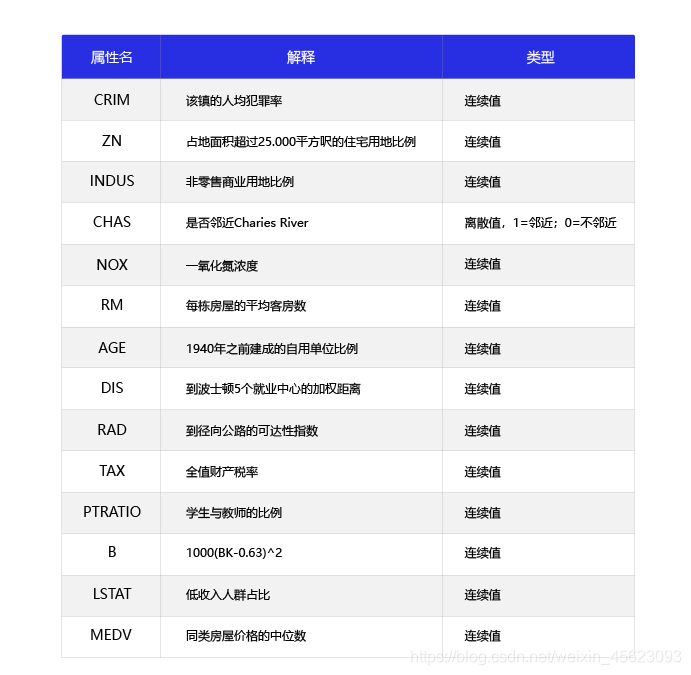
“波士顿房价预测任务”统计了13种可能影响房价的因素和该类型房屋的均价,希望通过机器的深度学习来获得一个预测的结果。
这是一个线性回归模型。那么什么是线性回归呢?(白话时间)就是多条数据导入通过特定的公式各个项加权等方式获得的一个结果叫做线性回归(非官方专业回答,为白话认知。)总的来说就是多个输入生成一个结果。
白话分析波士顿房价预测任务
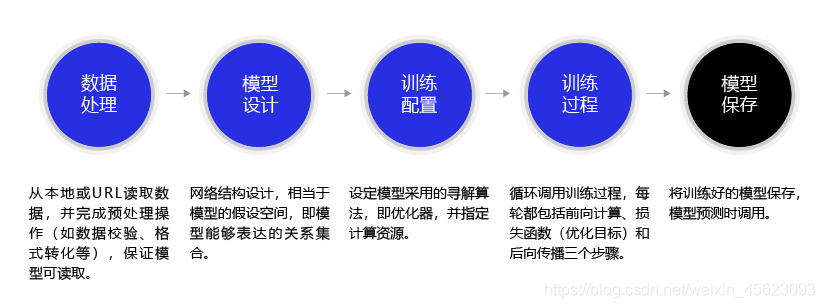
数据处理
数据处理没有什么好白话的,就是对数据集进行分析处理,通过numpy、pands等模块对数据进行整理、清洗、划分、加工等到可以“喂”给机器去学习的样本。
相当于买回来的菜要清洗,摘菜,然后处理(烧)才能够食用。至于工具可以理解为锅,微波炉或者是清蒸、红烧、油炸……
哧溜~ 怎么肥是,怎么有点流口水。
接下去会对处理好的数据进行分类,分为测试集和训练集,两者不能够重复
(白话时刻)
- 训练集就相当于我们上课做的训练题和试卷通过大量的学习获取一些特征和内容以得到更好的预测结果
- 测试集:相当于我们平时的考试试卷,只需要把平时的内容弄懂就可以做出来,通过得到的结果和实际结果进行比较生成loss(损失函数),通过把这个loss(成绩)进行反馈,通过反馈结果评判查看训练结果并促进训练。
模型设置
模型设置又称之为网络结构设计。
通过实际情况对数据进行加权等处理然后将结果与实际结果生成的loss进行比较反馈,通过反馈促进机器的学习。
训练配置
通过对初始参数及优化器,收到loss以后对训练方式进行优化,并指定训练、计算的资源
进行训练并保存模型
进行训练和对模型的保存,这个过程类似于人类每一天的生活和对生活的记载,模型就类似于日记(史记)记载整个训练过程,如果对训练的过程,参数等不满意可以删除模型重新“调参”。再次训练以寻求更好的结果。
这里是三岁今天的内容就到这里啦,如有什么不对的地方请多多指教,欢迎打扰,可以私信,留言,关注点赞一键4连呦!