百度飞桨带你从零实践到强化学习第二天
大家好这里是三岁,又是絮絮叨叨的一节课,三岁白话带你看看第二天讲了什么吧!
基于表格型方法求解RL
强化学习四元组 < S,A, P, R>
S : state 状态
A : action 动作
R : reward 奖励
P : probability 状态转移概率
强化学习和智能体之间的交互是逐步的
他是一个和时间相关的序列决策问题。
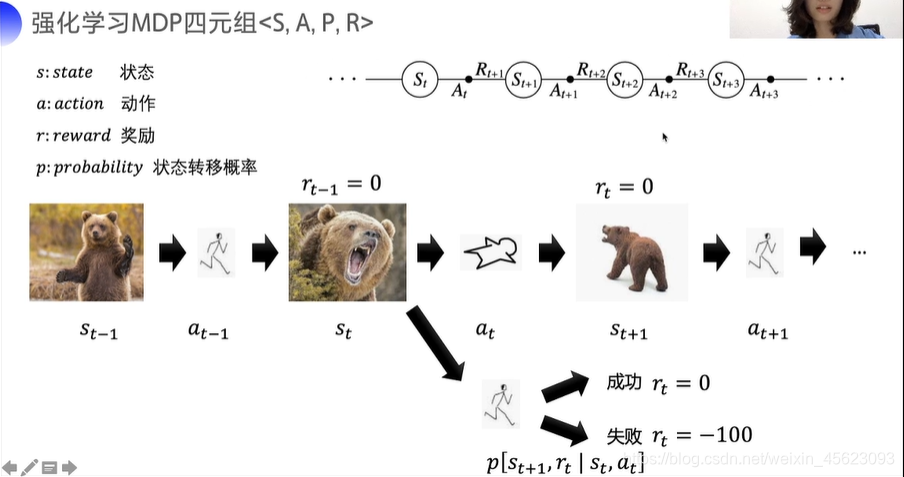
白话解析时间:(以下为个人认知与实际不一定符合)
交互是逐步的:类似于看电视,视频是逐帧的,每一帧的动画都是连续的不可能缺失不然就不是完整的影片了!
时间相关的决策:和人类的行为一样,我现在的行为决定了一生,如果选好了人生完全不一样,同样的机器的这次学习就是机器的此生,他的每一个行为决定了它这一生的结果。而且这一生没有后悔药一直是向前的。
转态转移概率:就是我们生活中的选着,比如吃什么,哪里恰?对于机器也是一样,机器选择是因为概率,我们选择是因为思维,我们模拟了自己的思维赋值给了机器。
总结:机器学习相当于机器模拟了某一个行为指定次数的探索,相当于人类几千年的探索和生存史,机器学习以收益为激励促进机器去探索尝试,最后获得一个相对较好的结果。
Model-free 试错探索

Model-based:对于p和r的概率是已知的。人、R的值和 P的概率都是知道的,这样就相当于在前人的肩膀上拉
Model-free:对于结果都是未知的,只能够摸着石头过河,逐步去探索

通过价值函数来代表这个过程的好坏。(V(st+1))
Q(st,at)代表某一个点他的结果的好坏及价值
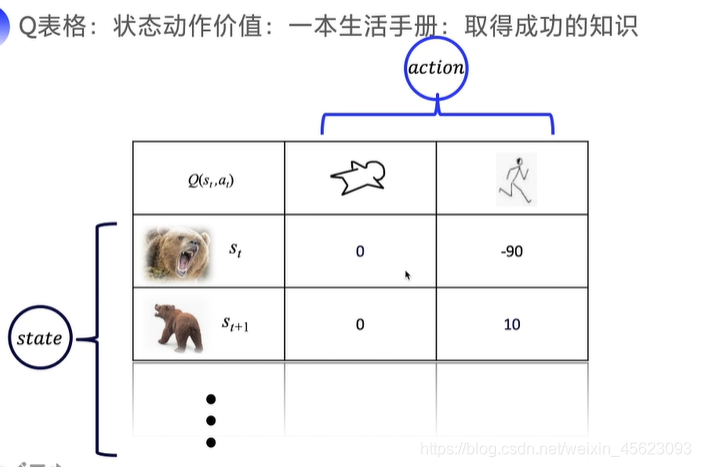
Q函数表格;转态动作价值:相对应生活手册,根据价值来获取
以未来的总收益为标准,更据实际情况进行操作。
比如:
- 闯红灯:一个是因为自己想扣12分还要罚款,一个是送人去医院或者避让特殊车辆则不用扣分,同样的机器学习以最后的那个结果(奖励或处罚为激励项目)
- 股票 :虽然我很久以后可能会大涨(根据预测),但是当前并不是很好,可是我预测的是当下的和好久以后的关系并不大,所以要注意时间的长度及跨度。
这里就多了一个衰减因子的概念
经典语录:对于远一点的东西我们只要当自己是近视就好了!
添加一个伽马值,范围是0到1之间。
这个值给越往前越大(伽马的平方)哪怕后面好久以后的数值很大但是也起不了什么波澜。对当前价值的影响就越小。
强化概念

当中性刺激和有条件刺激在时间上的结合导致中性刺激对也产生条件反射的学习叫做强化。
emmm,简单点讲,人类对某些事物的认知与联系就算是强化学习。看到定情信物想到爱人,本来两者毫无关联但是有了情感在里面就不一样啦!
转态价值迭代
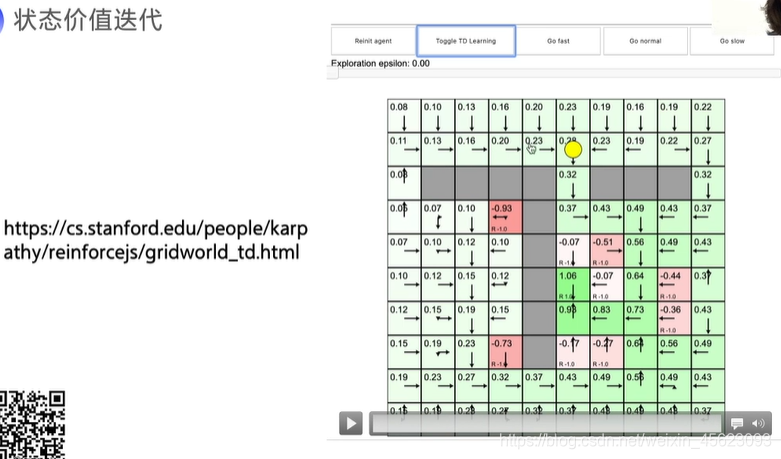
机器在学习过程中会对不同的地方进行价值评价,同时会影响周围地方的价值,当时间长了以后会选择出一条价值水平最高的路线。
探索与利用的选择

在选择过程中是强迫症还是计划性不纠结是去新的地方探索还是始终如一,这个就是探索和利用的一个方法。
存在的问题
没有图形界面
原因不详可能和环境有关系,但是在线下可以,那个结果还是比较美好的。
有几个需要修改的
没有文件
找不到一个GridWorld.py文件
这个可以自己写也可以直接使用
下载地址:(还在审核)
有文件不会用?

参考这个图,你懂得哦!!!

还有这个地方
根据他的修改了还是没有怎么办?

找到这个地方,把他改成 True ,尝试一下说不定可以有!!!
这里是三岁今天就先到这里了,我去研究今天晚上的作业啦!记得支持一下,点赞收藏留言关注!!!
呕心沥血系列!!!