冠军带你从零实践强化学习第三天(课程白话)
大家好你们的三岁又回来啦,今天已经是第3天的课程啦,先说声抱歉,没有时间看直播,只能够通过录播去自己解读,如果有不足的地方请多多指教!白话三岁今天叒开始啦!
神经网络方法求解
RL->Deep RL 数量逐渐增加到不可数
当转态可数的时候,所有的状态都可以用Q表格装下然后进行处理。但是状态太多了,无法完全记录怎么办呢???
ps:国际象棋 1047种状态,围棋 10170,宇宙原子数量近1080,某个区间的角度转态正无穷。
值函数的近似
针对以上实际生活中无法可数的状态就得使用传说中的值函数
用带参数的Q函数来代表Q函数,可以采用多项式函数,神经网络等进行表达。
优点:
①仅需存储有限的参数
②状态泛化,相似的状态可以输出一样。(自动去泛化一些相似的特征,输出相同的值)
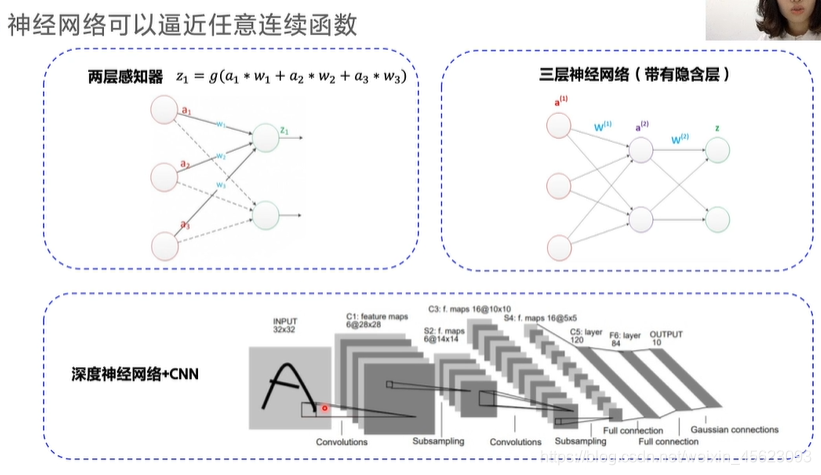
神经网络
神经网络:相当于一个巨大的黑盒子,里面是我们大量的算法和函数,通过一系列的结果可以获得想要的结果和值。
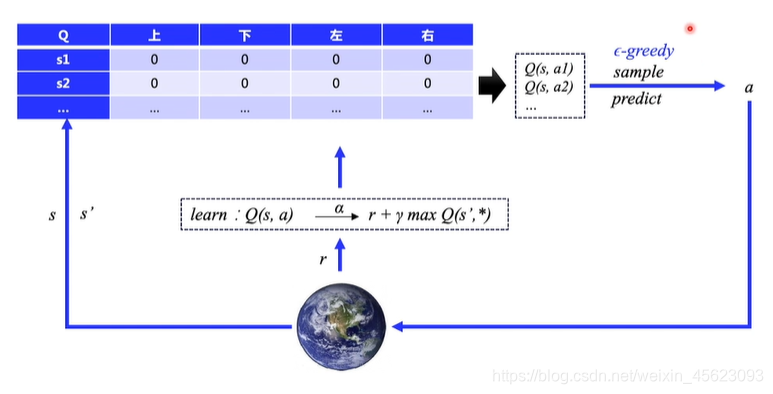
Q-learning
通过环境去查找Q表格获取一个R值进行输出,然后通过输出修改Q表格,同时进行探索不断完善Q表格。使得Q表格更加完善。
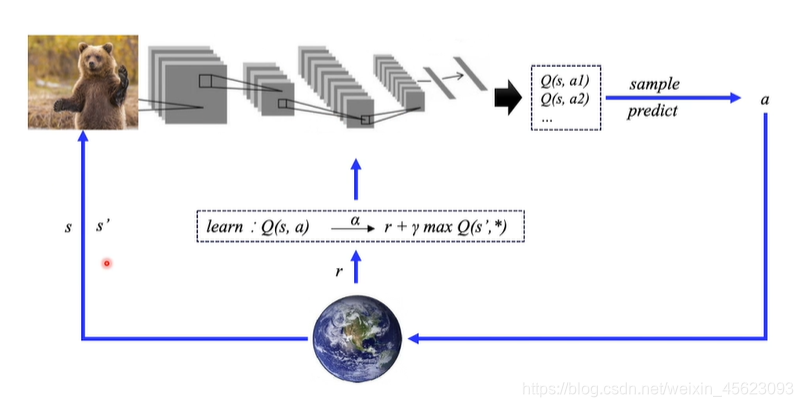
使用神经网络拟合Q表格
把原来的Q表格使用前面的神经网络进行替代,直接提取输入的环境特征,来得到结果。
监督式学习
在预设时除了输入一个环境(要预测的值)还要输入一个预计结果,促使机器学习的结果无限接近我们的预期值。机器学习的值和我们给的预期的均方差就是Loss,把Loss算尽就可以对网络自动更新和优化。
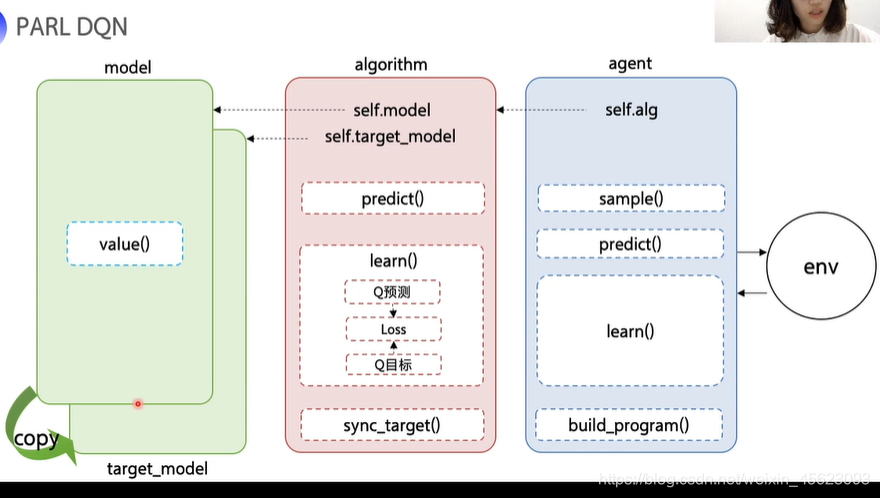
DQN
与监督式学习类似输入的每一个值s1得到一个相对应的Q值(这里的q对应的是向量),在这里需要让Q值逼近我们的目标值,同样用两个值的均方差Loss来给优化函数从而更新网络参数
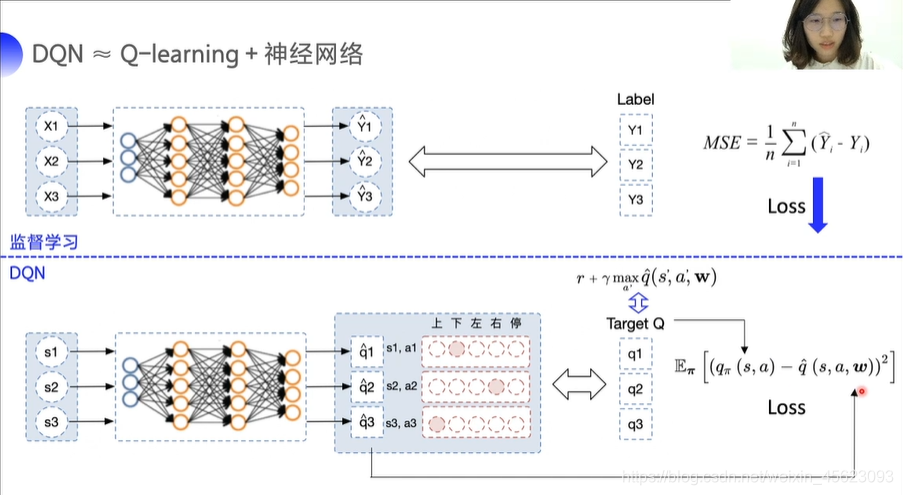
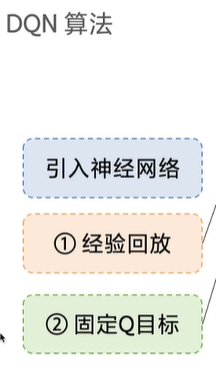
DQN两大创新点
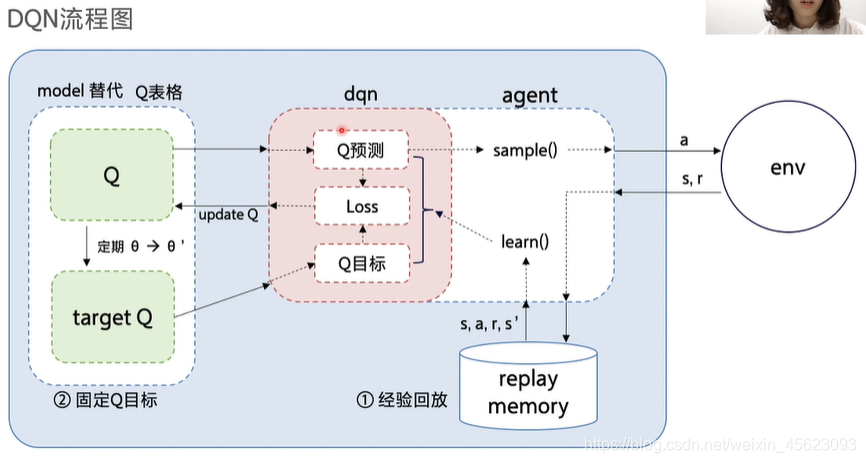
一、 经验回放
* 1.序列决策的样本关联
* 2.样本利用率低
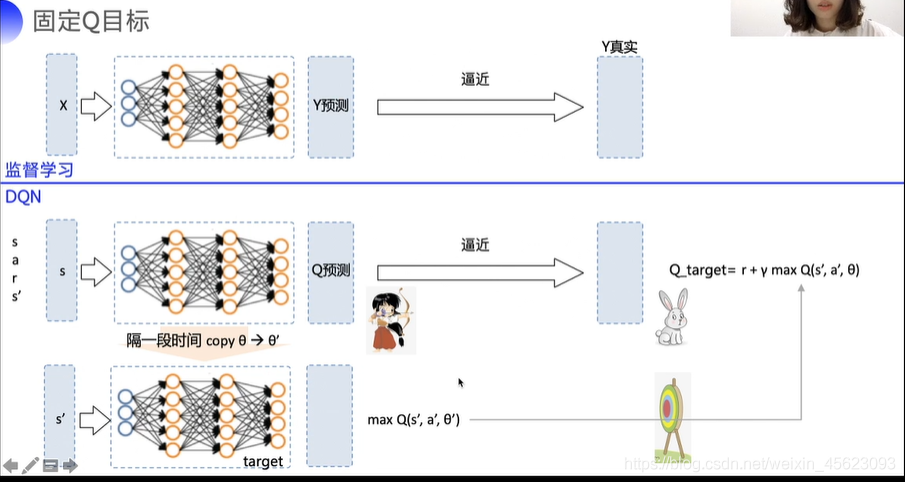
二、 固定Q目标
* 1.算法非平稳性
一:经验回放的优势
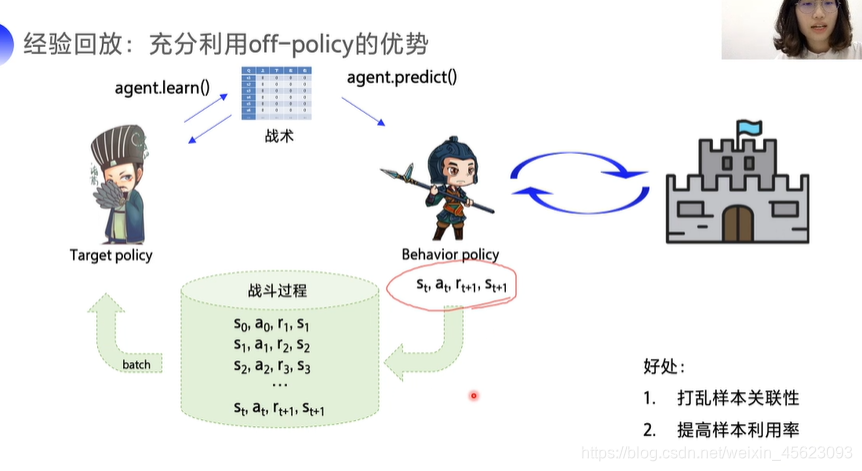
在探索和决策中添加了一个缓冲区用来存储探索数据,同时提高决策的关联性,促进更好的决策。
例示:

二:算法更新不平稳
在监督式学习中目标值是稳定的,预测值只要不断的靠近真实值y即可
但是在DQN中Q的目标值是,这个值是不断变化的,是有波动的可变值。
固定Q目标就是在一段时间内把Q固定,也就是单位时间内Q值是不动的,单位时间后再进行更新,这样子可以促进稳定。
DQN算法使用流程
理论部分就到这里啦,后面的是函数的和核心算法的解读,这里就不说啦。
作业问题
这次的作业问题还是有的,就三岁在群里面看到的一些数据来说无非是环境的选择,然后就是调试以及代码的书写
环境的选择
此处单纯的提及ai studio 的notebook平台
小编亲自尝试建议使用CPU版本(普通版)(原因是示例里面也是普通版跑的,而且转化高阶需要修改某些参数,三岁找不到)
代码书写
一句话
看范例!!!
看范例!!!
看范例!!!
参数修改
可以修改大家的学习率和学习的阶段(次数)
建议学习率为0.003和0.005
次数建议2000+
具体的还得自己多尝试
今天三岁就到这里啦,其他问题可以留言或者私聊小编,感谢大家的支持,希望点赞关注留言收藏们没事,谢谢大家