三岁在飞桨带你入门深度学习,利用PARL复现基于神经网络与DQN算法
大家好,这里是三岁,众所周知三岁是编程届小白,为了给大家贡献一个“爬山”的模板,三岁利用最基础的深度学习“hello world”项目给大家解析,及做示范。
三岁老规矩,白话,简单,入门,基础
如果有什么不准确,不正确的地方希望大家可以提出来!
以下为一些参考资料及相关协助作品,希望大家可以结合使用:
B站视频地址:https://www.bilibili.com/video/bv1v54y1v7Qf
AI studio文章地址:https://ai.baidu.com/forum/topic/show/962531
csdn文章地址:https://editor.csdn.net/md?articleId=107393006
三岁推文地址:https://mp.weixin.qq.com/s/6-6RR0XuvTNuXKhX7fFXaQ
参考论文:https://www.nature.com/articles/nature14236
DQNgithub地址:https://github.com/PaddlePaddle/PARL/tree/develop/examples
参考视频:https://www.bilibili.com/video/BV1yv411i7xd?p=12
Carpoel参考资料:https://gym.openai.com/envs/CartPole-v1/
PARL官方地址:https://github.com/PaddlePaddle/PARL
参考视频:
世界冠军带你从零实践强化学习
那么我们接下来就开始爬山吧,记得唱着小白船然后录像呦,三岁会帮你调整一下jio的位置的【滑稽】
环境及所需内容描述
小车的故事——Carpoel
Carpoel是我们深度学习的一个基础项目,类似于计算机编程中的“hello world”
我们先康康什么是Carpoel吧

(这个是之前跑数据时候的一个截图)
下面黑色的应该是一辆黑色的劳斯莱斯,但是太黑了你看不出来。
上面是要运送的一截光头强刚刚砍伐的大树(保护环境,珍惜绿水青山,此处静静只是想举个腻子)
大树只是垂直放置,重心在大树中间,随着小车的移动重心在惯性的因素下开始移动,
如果倾斜的角度大于12°或者移动2.4个单位该局结束。
emmm,简化一下就是 树木只要移动小于12°,或者超过2.4个单位即为成功。
官方文档:(此处为15°,下文代码等都是12°)

官网视频查看:
Carpoel视频
这里面还涉及到一个神奇的PARL
PARL是何方神圣呢?
通过三岁对官方文档的品读(copy)得到以下结论:

- PARL主要是基于Model、Algorithm、Agent三个代码块来实现,其中Model和Agent是用户自定义操作。
- Model:是网络结构:要三层网络还是四层网络都是在Model中去定义(下文是三层的网络结构)
- Agent:是PARL与环境的一个接口,通过对模板的修改即可运用到各个不同的环境中去。
- 至于Algorithm是内部已经封装好了的,直接加入参数运行即可,主要是算法的模块的展现
官方表达:

为什么说Carpoel是深度学习届的hello world ?
- 1.所有的算法都可以通过这个模型来查看是否是收敛的
- 2.内容简单,训练时间相对较短,对选手的能力水平要求不是很高
- (要求高的三岁也弄不来,关键是不会啊!)
- 3.这方面的代码可读性比较好,问题、异常处理较为方便。
环境配置
pip install gym
pip install paddlepaddle==1.6.3
pip install parl==1.3.1
# 添加百度源
# python -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
# pip install parl==1.3.1 -i https://mirror.baidu.com/pypi/simple
在里面涉及到了飞桨环境,建议加上百度源具体安装参考如下:
百度飞桨安装及使用说明(PAR说明):https://www.paddlepaddle.org.cn/install/quick
源代码
注:代码源于百度飞桨强化学习7天打卡营
代码地址:https://mp.weixin.qq.com/s/Yrt7iR597gXP703j9al7lA
csdn只能够显示68行,只有一部分,不好看,如果分开来怕有些看不懂会乱掉,我统一放在三岁的公众号里面,希望大家移步查看,如有不便多多包涵!
代码解析
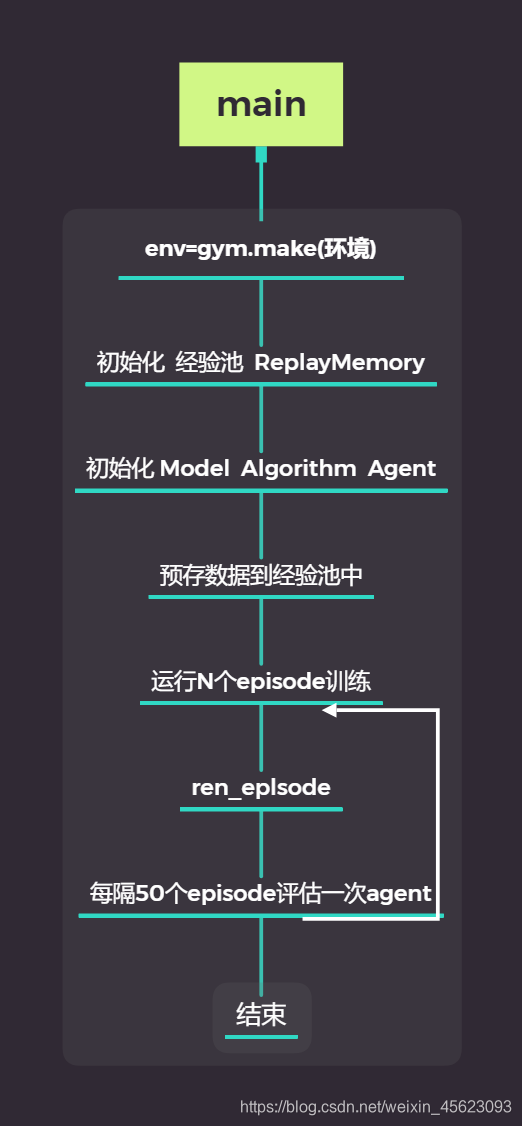
以上是主函数,也是这串代码的一个整体思路。
看一下各个代码的作用吧!
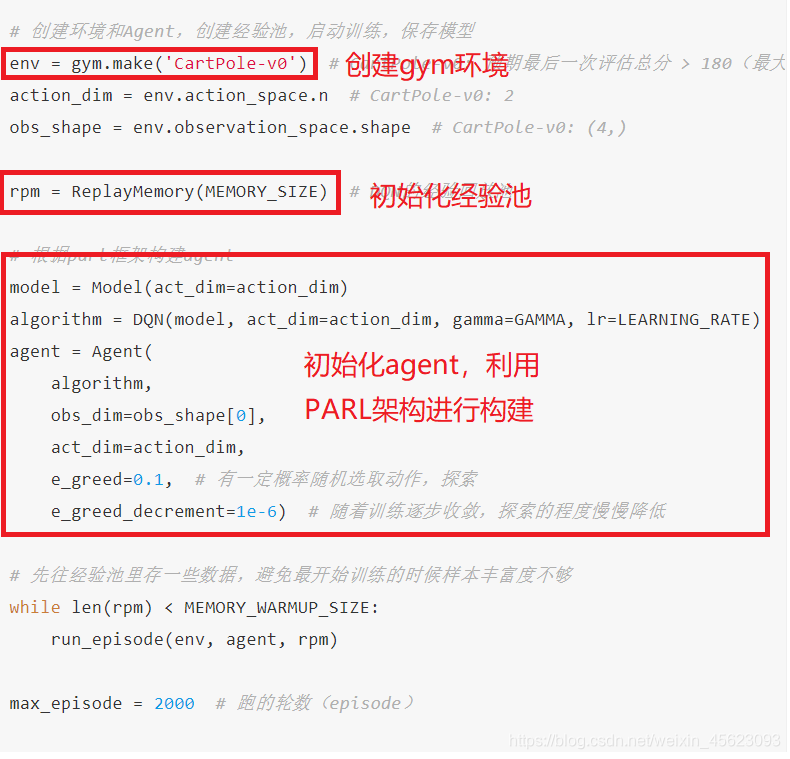
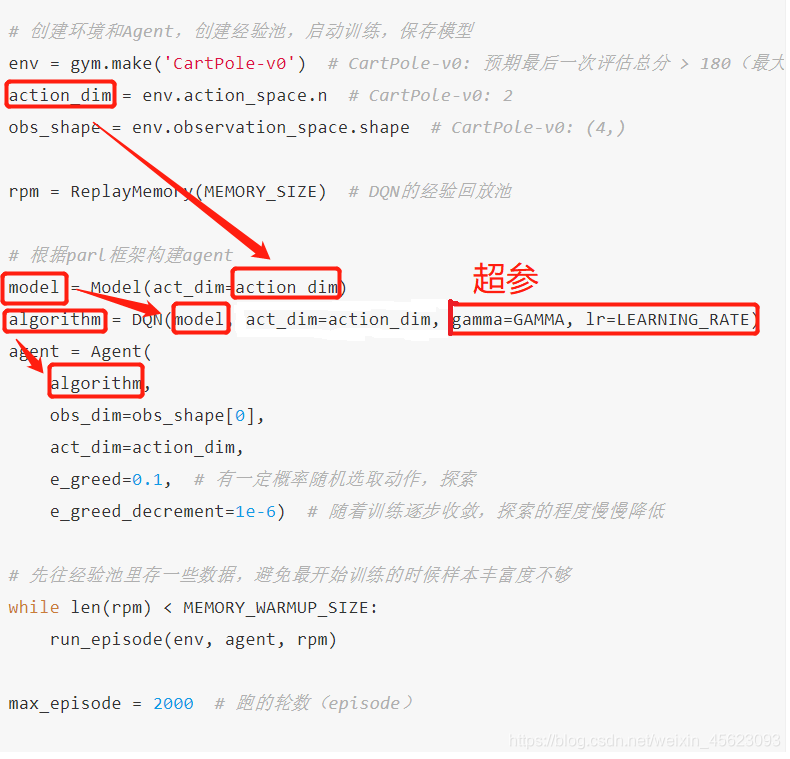
在这里面把一个代码主函数(代码中没有明确main()函数)流程进行一定的解析
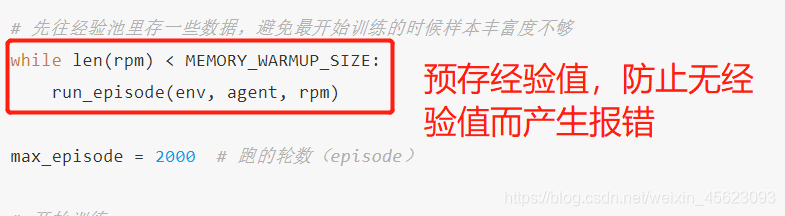

训练一轮:

训练一组(5轮):

结果查看:
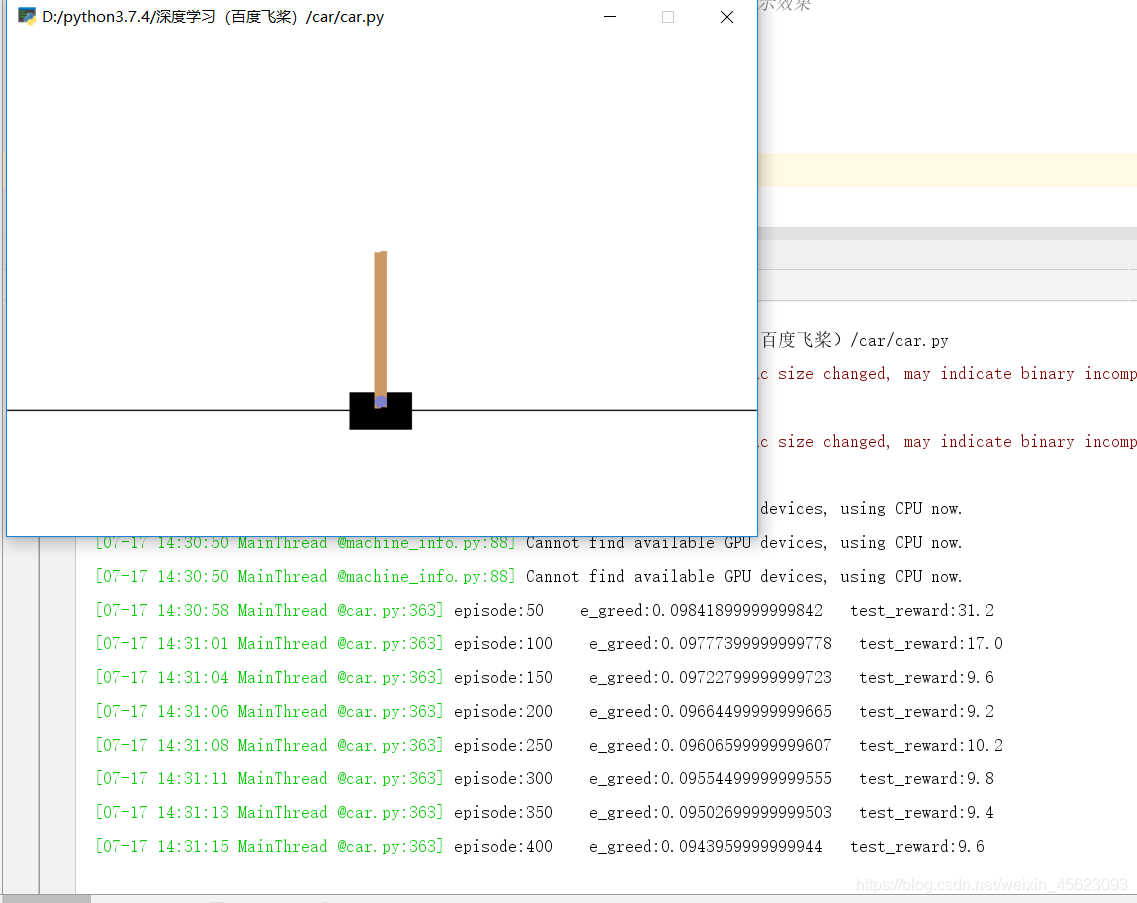
DQN算法 —— 白话
优势
DQN算法较普通算法在经验回放和固定Q目标有了较大的改进
-
1、经验回放:他充分利用了off-colicp的优势,通过训练把结果(成绩)存入Q表格,然后随机从表格中取出一条结果进行优化。这样子一方面可以:减少样本之间的关联性另一方面:提高样本的利用率
注:训练结果会存进Q表格,当Q表格满了以后,存进来的数据会把最早存进去的数据“挤出去”(弹出)

-
2、固定Q目标他解决了算法更新不平稳的问题。
和监督学习做比较,监督学习的最终值要逼近实际结果,这个结果是固定的,但是我们的DQN却不是,他的目标值是经过神经网络以后的一个值,那么这个值是变动的不好拟合,怎么办,DQN团队想到了一个很好的办法,让这个值在一定时间里面保持不变,这样子这个目标就可以确定了,然后目标值更新以后更加接近实际结果,可以更好的进行训练。
举个例子:以打靶为例,监督学习就像是打固定靶,他的结果是固定的,,但是DQN就是打移动靶,每一个时间段都是移动的,只能够把时间线拉长,分解成无数个时间段,每个时间段的值都是固定的。这样子就可以解决变动的不好处理的问题。
深度学习 — 白话
三岁又来逼逼赖赖啦,三岁白话深度学习:
深度学习:就是人们利用机器模拟人类对事物认知的方式来解决预测一些东西,对于机器他们只是通过构建的模型进行跑数据,进行数据的分析处理,然而我们把数据进行实例化,把抽象数据定义成一些实际化的东西,这样子便可以产生一些我们可以用的东西。
他利用了“奖励”引导的机制在里面,机器会尽可能的拿到跟多的奖励以获取更好的结果,有些时候会受到时间影响,比如股票的值可能受到很久以后的一个值的影响,但是这个值实际上并无意义,于是加入了一个“衰减因子”*他位于0-1之间,利用他自身多少倍的值来削弱某一个长期无意义值的影响。
运行经历
这一串代码是从课件上copy下来的,所以里面的参数及数据都是已经调整好了的,但是在线下跑数据发现每一次跑也并非到最后都是200也就是每一次的结果都是不一定的,然后我开了显示模式,里面的测试画面和结果会被显示和打印,前面的速度会比后面的快,因为分数低时间自然就短了。
更据这段时间对深度学习的学习,基本上代码运行没有问题后那么调整几个超参基本上可以得到一个比较好的拟合效果。
心得体会
本次“爬山”,发现之前的一些盲点在本次有了解决,,之前对深度学习、PARL、算法等都有了最新的认识,虽然还是那个小白但是认识提上去了,以后还是可以更加努力的去奋斗的,这就是传说中的回头看的时候就知道自己以前是多么的无知了。
爬完山拍完视频记得去公安机关呦~~~
希望这个“爬山”视频能够给大家一定的参考,如有不对或者有缺失的地方希望大家多多提出来,留言,私聊都ok,希望大家可以一起学习,一起提高,这里是小白三岁,感谢你的支持,不要忘记点赞、留言、收藏、关注呦~~~
那个那个那个,对就是你,说你呢,你那个jio的位置不对,拍出来照片不好看,我来帮你挪一下!!!