百度飞桨从零实践强化学习第四天
这里是三岁,这里吧第四的素材和资料整理了一下,大家康康,有什么不足的欢迎提出,批评指正!!!
基于策略梯度求解RL
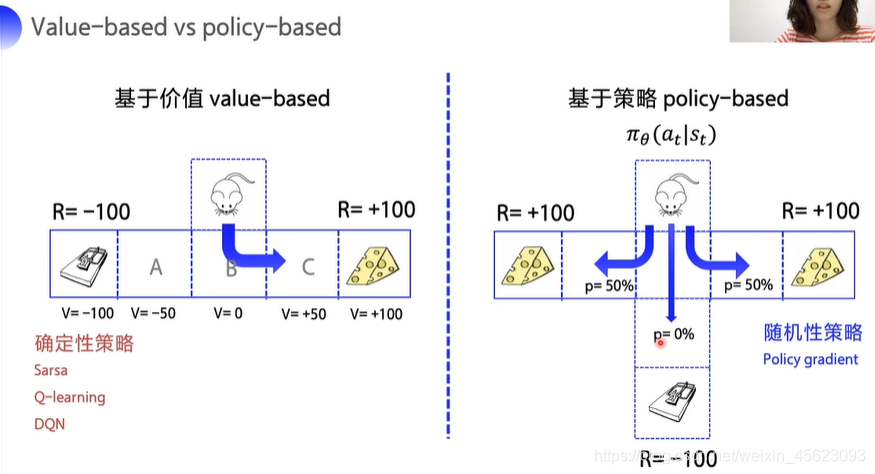
Value-based vs policy-based
Value-based
Value-based 是基于价值的,属于一种确定性策略
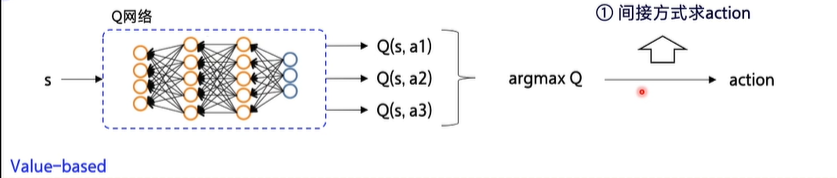
在计算时先求出Q的值然后把Q网络调到最优以后用间接方式输出action,属于确定性的策略,
policy-based
policy-based 是基于策略的,属于一种随机策略
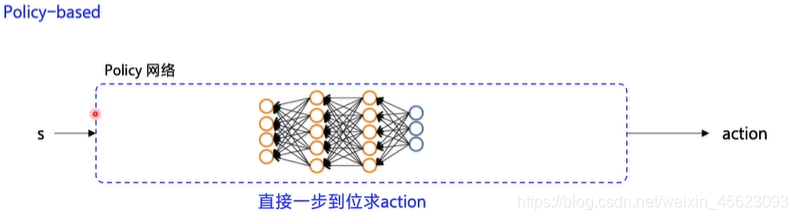
policy-based使用神经网络拟合直接一步到位求出action输出的是一种概率最后是一种随机的策略。适用于随机性比较大的项目。
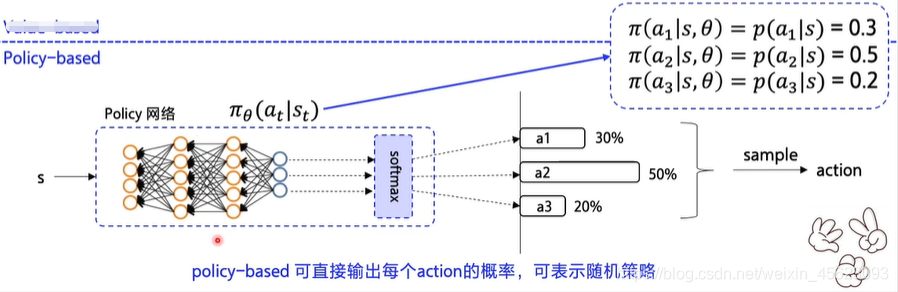
πθ(at|st)代表在st的转态下输出at的概率有多大、所有的概率之和为一,概率越大的越容易被采样到。
为了输出概率会在神经网络最后加上一个softmax的函数。将多个输出映射到一个(0,1)的区间中去,可以看成是一个概率。
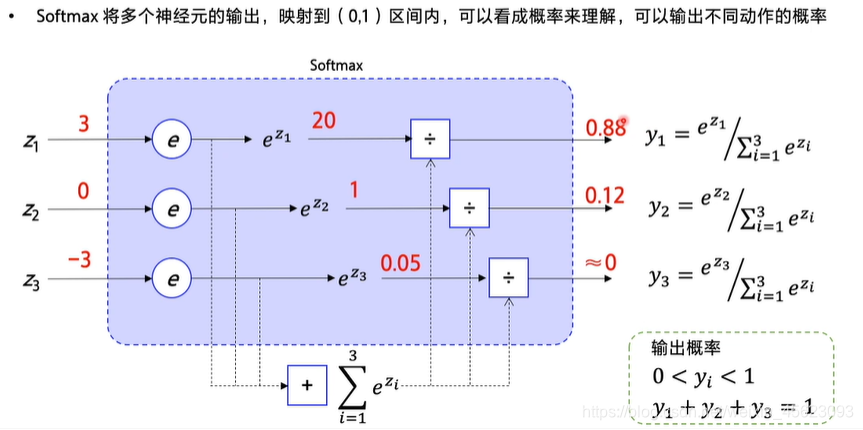
整个优化的目的是为了使每一个Episode(幕)可以理解为每一场比赛,的总的reward(分数,利益)最大化
轨迹Trajectory
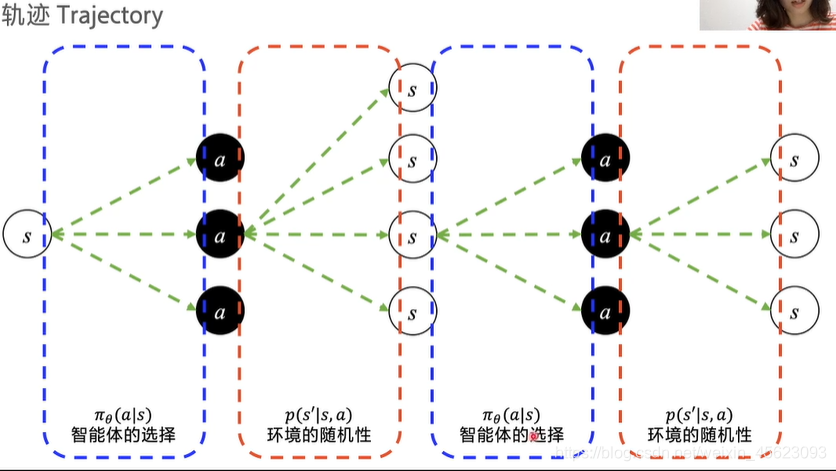
智能体的选择是我们需要优化的策略,智能体不断的和环境发生交互,在不同的环境中随机选择最好的策略,已获得最好的结果,然而环境是不可选择的,只能够不断的在交互过程中选择最好的策略。

一条智能体的选择与环境的交互选择连起来直到结束成为一条轨迹也就相当于这个episode的结束。
期望回报

当求出所有的轨迹的回报值(收益)的时候可以求出来他的平均回报值,通过该回报值来判断该策略的好坏。
但是因为策略轨迹太多了是无穷的所以采用了采样的方式来获取,当数据样本足够大的时候就可以近似为平均回报。
优化策略
-
Q网络
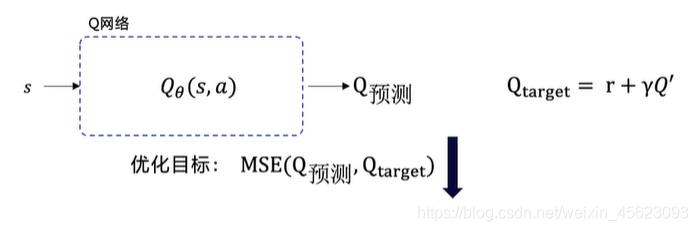
Q的预测值和Q的预期值进行对比要求Loss越低越好,越低距离预期越远。 -
policy 网络
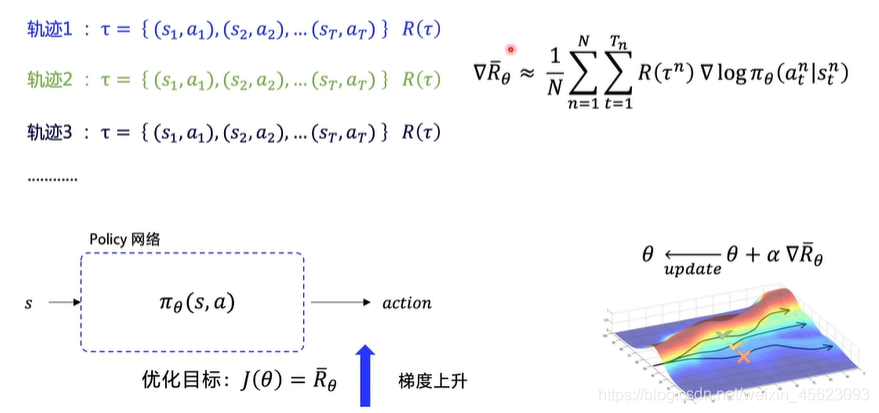
由于policy网络的策略梯度是没有预期值的所以就需要上面说到的期望回报,只有结果越高才能够有更大的收益。通过轨迹的收益,不断强化网路,促使收益高的出现概率更高。
蒙特卡洛MC与时间差分TD
- 蒙特卡洛 回合更新制度,每一回合进行一次更新
- 时序差分 为每一步都更新
PEINFORCE
先产生一个回合的数据,利用公式计算每一回合的总收益,用来更新网络
以上基本上就是今天的理论知识啦,这里是三岁,有是和你白话的一天,希望大家多多支持,点赞关注收藏评论,有问题可以私聊呦!!!