线性分类
上篇对于图像分类问题实践了 k-Nearest Neighbor (k-NN)分类器,该分类器的基本思想是通过将测试图像与训练集带标签的图像进行比较,来给测试图像打上分类标签。k-Nearest Neighbor分类器存在以下不足:
- 分类器必须记住所有训练数据并将其存储起来,以便于未来测试数据用于比较。这在存储空间上是低效的,数据集的大小很容易就以GB计。
- 对一个测试图像进行分类需要和所有训练图像作比较,算法计算资源耗费高。
因此,实现一种更强大的方法来解决图像分类问题,该方法可以自然地延伸到神经网络和卷积神经网络上。这种方法主要有两部分组成:一个是评分函数(score function),它是原始图像数据到类别分值的映射。另一个是损失函数(loss function),它是用来量化预测分类标签的得分与真实标签之间一致性的。该方法可转化为一个最优化问题,在最优化过程中,将通过更新评分函数的参数来最小化损失函数值。
评分函数(score function)
评分函数,这个函数将图像的像素值映射为各个分类类别的得分,得分高低代表图像属于该类别的可能性高低。
对于SVM这个线性分类器而言,其评分函数为:
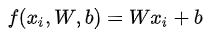
进行偏差和权重合并后,分类评分函数简化为如下:
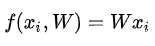

损失函数(loss function)
当评分函数输出结果与真实结果之间差异越大,损失函数输出越大,反之越小。
常用的多类支持向量机(SVM)损失函数。SVM的损失函数想要SVM在正确分类上的得分始终比不正确分类上的得分高出一个边界值。
针对第i个数据的多类SVM的损失函数定义如下:
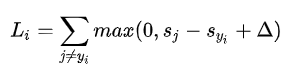
SVM的损失函数想要正确分类类别 yi 的分数比不正确类别分数高,而且至少要高出一个边界值。多类SVM“想要”正确类别的分类分数比其他不正确分类类别的分数要高,而且至少高出delta的边界值。如果其他分类分数进入了红色的区域,甚至更高,那么就开始计算损失。如果没有这些情况,损失值为0。我们的目标是找到一些权重,它们既能够让训练集中的数据样例满足这些限制,也能让总的损失值尽可能地低。
包含正则化惩罚后,就能够给出完整的多类SVM损失函数了,它由两个部分组成:数据损失(data loss),即所有样例的的平均损失,以及正则化损失(regularization loss)。完整公式如下所示:
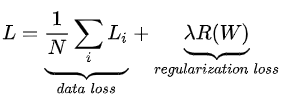
将其展开后的完整公式如下:
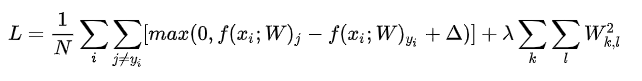
代码:如下为一个不包含正则化部分的损失函数的实现(非向量化和半向量化两种形式)
#非向量化
def L_i(x, y, W):
delta = 1.0
scores = W.dot(x)
correct_class_score = scores[y]
D = W.shape[0]
loss_i = 0.0
for j in xrange(D):
if j ==y:
continue
loss_i += max(0, scores[j] - correct_class_score +delta)
return loss_i
#半向量化
def L_i_vectorized(x, y, W):
delta = 1.0
scores = W.dot(x)
margins = np.maximum(0, scores - scores[y] + delta)
margins[y] = 0
loss_i = np.sum(margins)
return loss_i
找到使得损失值最小化的权重
设置delta:超参数delta和λ看起来是两个不同的超参数,实际上一同控制同一个权衡:损失函数中数据损失和正则化损失之间的权衡。真正的权衡是我们允许权重能够变大到何种程度(通过正则化强度λ来控制)。
最优化Optimization
最优化的目标就是寻找使得损失函数值最小化的参数W。
- 损失函数可视化:SVM的损失函数是一个凸函数。但是一旦我们将 f 函数扩展到神经网络,目标函数就就不再是凸函数了,图像也不会像上面那样是个碗状,而是凹凸不平的复杂地形形状。
- 由于max操作,损失函数中存在一些不可导点(kinks),这些点使得损失函数不可微,因为在这些不可导点,梯度是没有定义的。但是==次梯度(subgradient)==依然存在且常常被使用。
策略一:随机搜索
随机尝试很多不同的权重,然后观察其中哪个最好。
bestloss = float("inf") #python中最大的float值
for num in xrange(1000):
W = np.random.randn(10,3073)* 0.0001
loss = L(X_train, Y_train, W)
if loss < bestloss:
bestloss = loss
bestW = W
print 'in attempt %d the loss was %f, best %f' % (num,loss,bestloss)
准确率很低,一般只有15%左右
策略二:随机本地搜索
第一个策略可以看做是每走一步都尝试几个随机方向,如果某个方向是向下山的,就向该方向走一步。
随机本地策略意味着从一个随机W开始,然后生成一个随机的扰动δW,只有当W +δW的损失值变低,才会更新。
W = np.random.randn(10,3073) *0.001 #生成随机初始W
bestloss = float("inf")
for i in xrange(1000):
step_size = 0.0001
Wtry = W + np.random.randn(10,3073)*step_size
loss = L(Xtr_cols, Ytr, Wtry)
if loss < bestloss:
W = Wtry
bestloss = loss
print 'iter %d loss is %f' % (i, bestloss)
准确率依旧很低,只能达到21%左右的分类准确率
策略三:跟随梯度
其实不需要随机寻找方向,因为可以直接计算出最好的方向,这就是从数学上计算出最陡峭的方向。这个方向就是损失函数的梯度(gradient)。
- 梯度计算:
- 缓慢的近似方法(数值梯度法:利用有限的差值来近似计算梯度),实现相对简单,但是该策略不适用于大规模数据,而且终究只是近似,因此采用微分分析计算梯度
def eval_numerical_gradient(f, x):
'''
f在x处的数值梯度法的简单实现
-f 是只有一个参数的函数
-x 是计算梯度的点
'''
#在原点计算函数值
fx = f(x)
grad = np.zeros(x.shape)
h = 0.00001
#对x中所有的索引进行迭代
it = np.nditer(x,flags = ['multi_index'],op_flags = ['readwrite'])
while not it.finished:
#计算x+h处的函数值
ix = it.multi_index
old_value = x[ix]
x[ix] = old_value + h #增加h
fxh = f(x) #计算f(x+h)
x[ix] = old_value #记得存回前一个值当中,重要
#计算偏导数
grad[ix] = (fxh - fx)/h #坡度
it.iternext() #到下个维度
return grad
#使用上述函数
def CIFAR10_loss_fun(W):
return L(X_train, Y_train,W)
W = np.random.randn(10,3073)*0.001 #随机权重向量
df = eval_numerical_gradient(CIFAR10_loss_fun, W) #得到梯度
#初始损失值
loss_original = CIFAR10_loss_fun(W)
print 'original loss: %f' % (loss_original,)
#查看不同步长的效果,步长后面会称为学习率
for step_size_log in [-10,-9,-8,-7,-6,-5,-4,-3,-2,-1]:
step_size = 10** step_size_log
W_new = W - step_size * df
loss_new = CIFAR10_loss_fun(W_new)
print 'for step size %f new loss:%f' % (step_size,loss_new)
- (分析梯度法:微分分析计算梯度)计算迅速,结果精确,但是实现时容易出错,且需要使用微分,在实际操作时常常将分析梯度法的结果和数值梯度法的结果作比较,以此来检查其实现的正确性,这个步骤叫做梯度检查(gradient check)。
#普通的梯度下降
while True:
weights_grad = evaluate_gradient(loss_fun, data, weights)
weights += -step_size * weights_grad #进行梯度更新
#普通的小批量数据梯度下降
while True:
data_batch = sample_training_data(data,256) #256个数据
weights_grad = evaluate_gradient(loss_fun,data_batch,weights)
weights += -step_size * weights_grad #进行梯度更新
后续会采用反向传播技术来高效的计算梯度
小批量数据策略有个极端情况,那就是每个批量中只有1个数据样本,这种策略被称为随机梯度下降(Stochastic Gradient Descent 简称SGD)。
SVM
首先,具体阅读文档Linear classification: Support Vector Machine, Softmax,了解什么是线性模型,支持向量机(SVM)和Softmax分类器都是线性分类器,如阅读英文不方便理解,还可参考中文翻译版,链接如下:中文翻译版。
1. 数据载入
2. 数据预处理
(1)需要将数据集分为训练集、验证集(用来选择合适的W)、测试集,以及一个小的数据集(训练集中的一小部分,为了优化代码速度)
(2)需要将数据集变化成二维矩阵,方便计算
(3)所有图像都是使用的原始像素值(从0到255)。在机器学习中,对于输入的特征做归一化(normalization)是必然的。在图像处理中,每个像素点可以看作是一个简单的特征,在一般使用过程中,我们都先将特征“集中”,即训练集中所有的图像计算出一个平均图像值,然后每个图像都减去这个平均值,这样图像的像素值就大约分布在[-127, 127]之间了,进行偏差和权重合并后,后期只需要优化单一权重W。
3. 实现SVM分类器
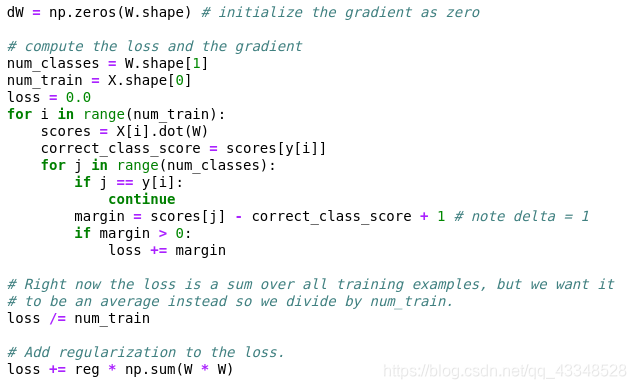
(1)实现非完全矢量化损失函数
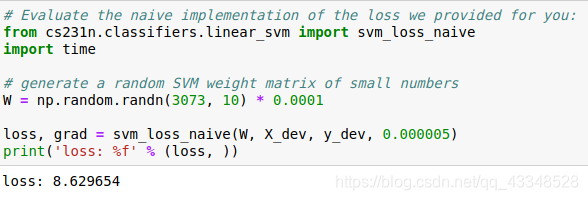
(2)使用数值梯度法比较分析梯度法检查实现
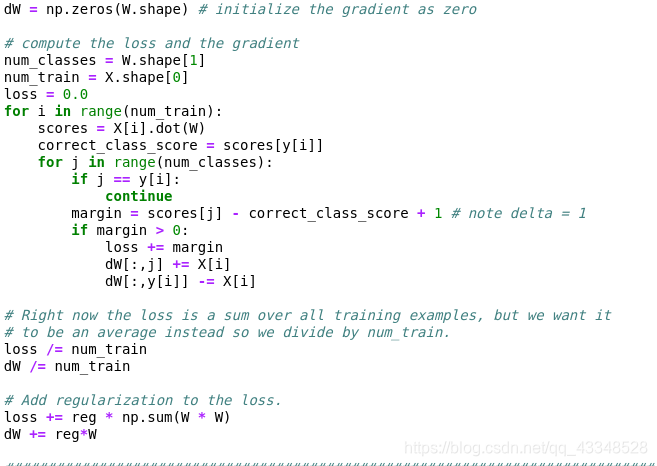
- 实现分析梯度法:
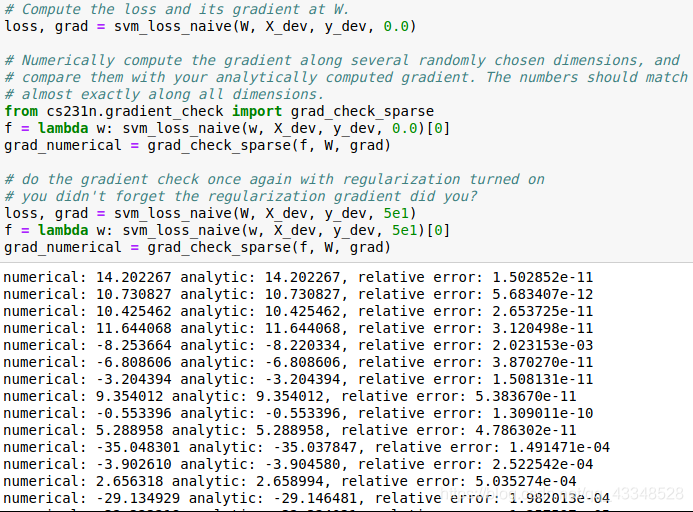
- 比较数值梯度法和分析梯度法来验证使用分析梯度法时微分公式推导正确:
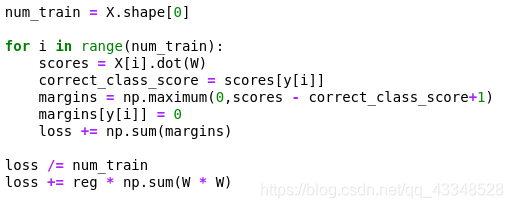
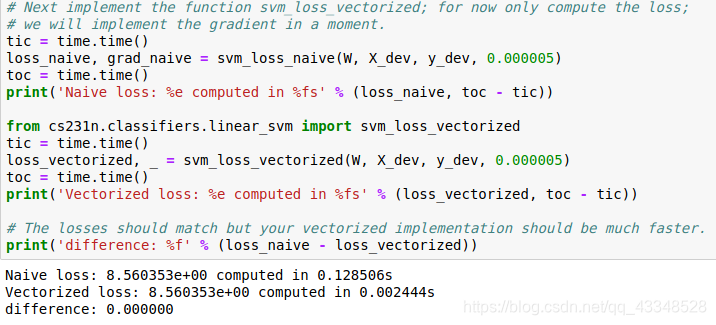
(3)实现其损失函数的完全矢量化表达式
- 一开始没有做到完全矢量化,只考虑到了半矢量化,也就是还保留了一层循环,导致计算时间上减少的程度不够大
代码:
结果:

- 完全矢量化,完全矩阵计算,大大节省计算时间
代码:

结果:
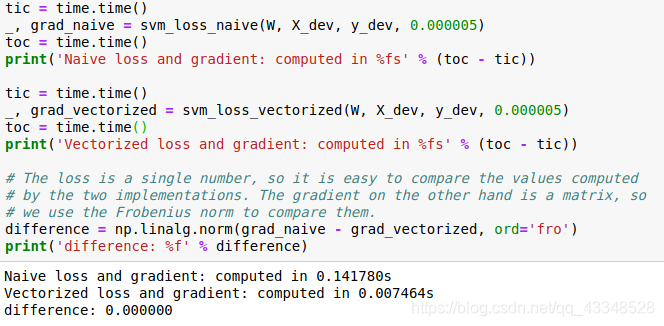
(4)实现梯度的完全矢量化表达式
未使用时代码见(2),实现梯度计算的完全矢量化表达式,代码如下:

结果如下:
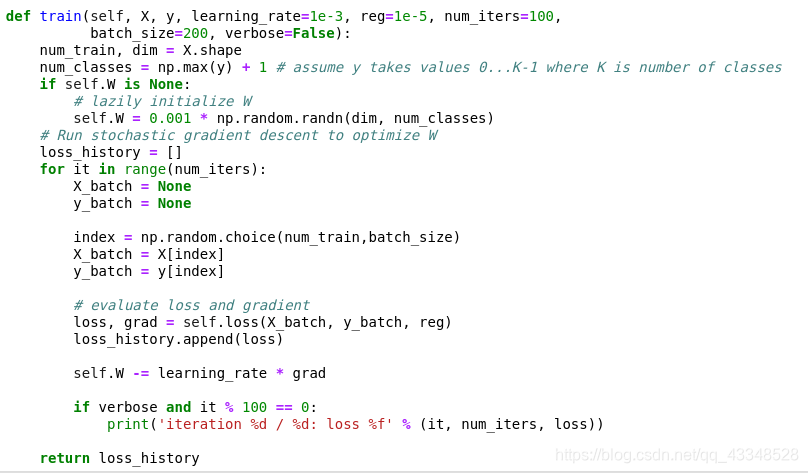
4. 使用SGD(随机梯度下降)来最小化损失函数值
(1)线性分类器通过训练来不断地沿着负梯度方向,迭代更新权重值。
代码:
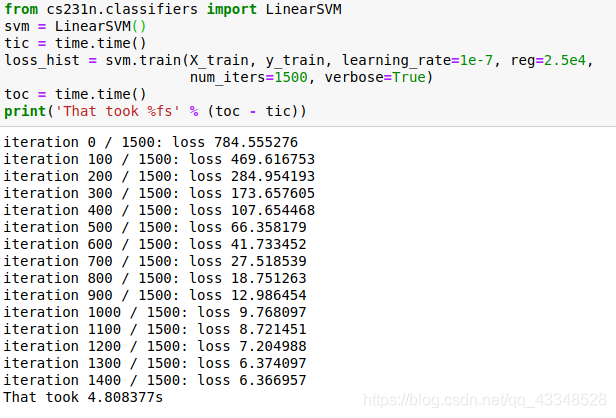
结果(迭代1500次):
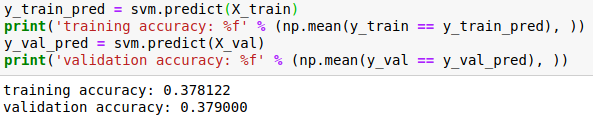
(2)使用训练完成后,更新出的权重值来做预测
代码:

结果:
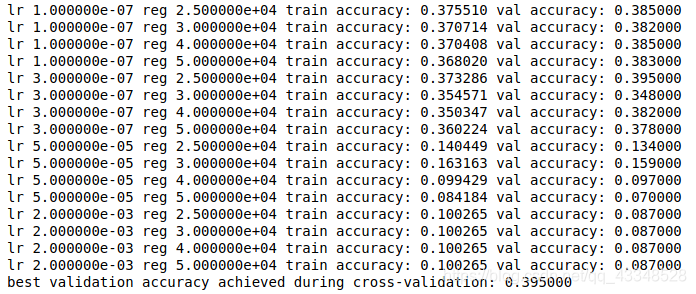
5. 对学习率和正则化强度这两个超参数进行训练
采用排列组合来尝试得到较好的超参数组合:
代码:

结果:
6. 采用目前最好的学习率、正则化强度和训练完成的W,对测试集进行预测

结果如上,正确率为37.4%
7.总结
SVM中梯度(dW)只与数据有关,而与权重W无关,准确率虽然不是很高,但是其损失函数以及通过求损失函数的梯度来对权重进行优化的思想,在后续神经网络中也是用得上的,神经网络相对而言只是评分函数远复杂于线性分类器。