计算机视觉(斯坦福2017课程)
训练神经网络
在我的另一篇【深度学习】cs231n计算机视觉 Neural Network(两层神经网络)里同样有如下概念的细节解释;
- 初始设置神经网络
激活函数、数据预处理、权重初始化、正则化、梯度检查 - 训练中的动态变化
监控整个训练过程、参数更新、超参数优化 - 模型评估和模型集成
1. 激活函数
- 不同的激活函数:

- Sigmoid激活函数:(存在的问题)
- 饱和神经元将使梯度消失
如果输入的值过大或者过小,就会使得dw为0,使得梯度消失 - sigmoid函数的输出是一个非零中心的函数:意味着反向传播时,如果输入值全部为正数或者负数,那么dw就会是x, 就会一直保持正数或者负数,在我们更新参数时就会出现如下问题,本来沿着蓝色线的方向可以求解到最优的参数,可是所有梯度方向都是同方向,就无法直接沿着蓝线方向,出现过多折线问题(如红线所示)。

- 指数运算的代价稍微有点高
- tanh激活函数:
- 饱和也会出现梯度消失
- 是零中心函数
- ReLU激活函数:
- 正方向不存在饱和现象
- 计算成本最低
- 相比sigmoid更接近神经元传递生物合理性
- 是一个非零中心函数
- 在负半轴这一半区域中都会产生梯度消失现象
- Leaky ReLU激活函数:

- 推荐使用ReLU,或者是ReLU的变形,不推荐使用sigmoid激活函数
2. 数据预处理
归一化数据问题:

一般来说,对于图片,就是做零均值化的预处理;
3. 权值初始化(weight initialization)
-
初始想法:
权重是小的随机数

在小型网络结构适用,但是对于较深的网络结构不适用;
权重改成很大的随机数也不可以,因为好几种激活函数在数值很大的时候都会趋于1,趋于平稳,整个网络会饱和(saturated)。 -
针对ReLU时,采用如下初始权重计算方法:

-
针对tanh时,采用如下初始权重计算方法:

4. 批量归一化(batch normalization)BN层
因为了解到归一化在神经网络中非常重要,因此提出了BN层,在神经网络中加入额外的一层以使得中间的激活值均值为0,方差为1。
在深度学习中,因为网络的层数非常多,如果数据分布在某一层开始有明显的偏移,随着网络的加深这一问题会加剧(这在BN的文章中被称之为internal covariate shift),进而导致模型优化的难度增加,甚至不能优化。所以,归一化就是要减缓这个问题。
BN的作用在于强制把数据转换为单位高思数据。

也可以把这个过程看作是正则化的一部分;
这并不会改变原有的主体的神经网络结构,因为主要是在对数据进行一些处理,并不是改变网络结构的过程;
5. 跟踪学习过程(babysitting the learning process)
如何监视整个训练过程(在过程中调整以上的各种超参数):
- 数据预处理
- 选择网络结构
- 初始化网络,进行前向传播
- 进行训练
6. 超参数优化
- 对于任何超参数,执行交叉验证,交叉验证是在训练集上训练,然后在验证集上验证;
- 交叉验证:
假如有1000张图片,我们将训练集平均分成5份,其中4份用来训练,1份用来验证。然后我们循环着取其中4份来训练,其中1份来验证,最后取所有5次验证结果的平均值作为算法验证结果;
不能将测试集用于调整超参数
- 网格搜索和随机搜索(random search)
用于确定超参数的值,随机搜索对超参数空间覆盖的更好。
- 当你完成超参数优化的过程中,一开始可能会处理很大的搜索范围,几次迭代之后,就可以缩小范围,圈定合适的超参数所在的区域,然后在对这个小范围,重复这个过程。学习率一般会被率先确定。

对损失函数画图来观察判断学习率的好坏:

7. 更好的优化
- 随机梯度下降算法(SGD)的问题:
(1)梯度下降的等高线不均匀
 因为两个下降方向的等高线不均匀,因此采用随机梯度下降的时候会出现zig-zag问题;
因为两个下降方向的等高线不均匀,因此采用随机梯度下降的时候会出现zig-zag问题;
(2)对于局部最优点和鞍点(不是最大值也不是最小值,只是在当前位置的梯度为0)的问题:

在这种情况下,SGD会卡在中间。
在正常的大型的神经网络中,鞍点问题相较于局部最小值问题,出现的频率高的多。
(3)噪声影响:
在SGD过程中,如果存在噪声会使得常规的SGD过程变得较为曲折缓慢。可能需要花很长的时间才能到达最小值。
- 解决办法:
(1)在SGD中加入一个动量项 :
想象一个球滚下山顶,现在考虑了它的速度,那么即便在局部最小值点,它也是有速度的,所以就能够越过这个局部最小值点。
设置这个速度的时候只需要考虑把它设置为0,不需要把它考虑成一个超参数。


(2)结合了Momentum和RMSProp两者的方法:
Adam:

也有一个小问题,在最初几步的时候可能会出现很大的步长,导致出现问题。
因此,Adam加入了偏置矫正项(bias correction term)相当于开始时放大了一下second-moment,来避免开始就可能出现很大的步长。

推荐采用的设置值:

- 采用步长衰减的学习率,通常是先尝试不用衰减,观察损失函数曲线情况,之后再考虑加上在哪加上衰减函数。Adam通常不使用衰减学习率。
8. 正则化
- 如何提升单一模型的效果:正则化就是一种方法;防止训练集上的过拟合,从而使测试集上的效果得到提升。
-
在损失函数后加上一项正则化部分:
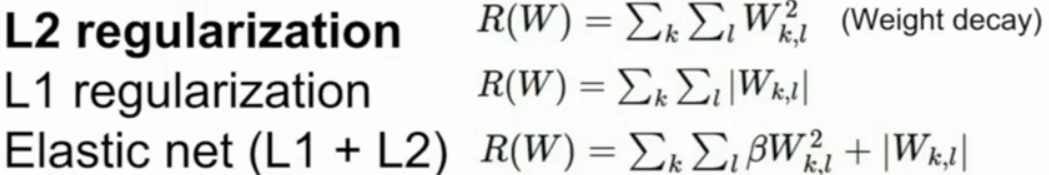
-
Dropout:
(1)神经网络正则化的常用办法就是dropout,dropout就是在前向传播中,随机的将一些神经元置零,随机被置成0的神经元都不是完全相同的,左边是全连接网络,右边是经过dropout的;
(2)就是将部分激活函数中的值置为零,等到这些数值作为下一个神经元的输入函数时,当中有一部分是0;
(3)一般使用dropout在全连接层,但是有时也会出现在卷积层,出现在卷积层时,是随机的将整个特征映射置零(将一个或几个通道完全置零);

在训练中加入dropout为了使它不过拟合,而在测试过程中,需要考虑准确性,随机置零可能会出现判断问题,因此使用了p,来解决。

-
数据增强(data augmentation)
在训练过程中,以某种方式随机的转换、裁剪、色彩抖动原图像,使得标签不变,然后用这些随机转换的图像进行训练。这种方式对网络有正则化效果,因为在训练的过程中,又增加了某种随机性,然后在测试的时候将它们淡化。

-
BN层 批量归一化(batch normalization)
前面已经介绍过,此处不赘述。 -
随机最大池化操作(Fractional Max Pooling)
9. 迁移学习
想要完成一个功能强大的网络需要足够多的数据用来训练,小数据集合很容易导致过拟合问题。迁移学习能够使你不用拥有很大的数据,也能够很好的训练一个CNN模型。

如何选择需要调整哪些参数:

fine tuned :精调