上次文章的补充:
权重 可以看作是每个种类的学习模板,决定输入的图片 里面哪些像素对输入被分到某个类别上有多少影响。所以权重的每一行对应一个分类模板,如果重新将权重某一行重新解开成图片大小,那么既可以看到这个模板的图片形式。
另一种线性分类器的解释:
学习像素在高维空间的一个线性决策边界,其中高维空间就对应图片能取到的像素密度值。
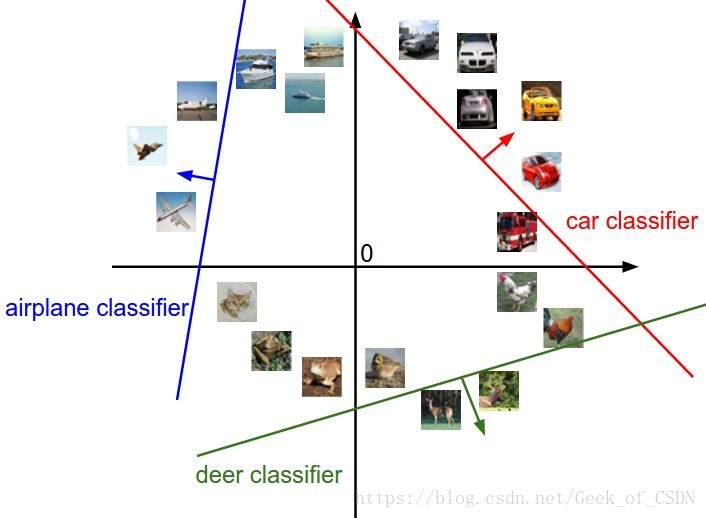
在上图中一张图片就对应着上面的一个坐标点,而分类器就是那个线。
损失函数简单定义:
一个将 当作输入,看下里面的数值,然后度量某个权重 数值好坏的函数。具体计算方法要看你是怎么定义损失函数的。
大致内容
- 线性分类
- 映射函数
- SVM
- softmax
- SVM和softmax之间的不同和相似的地方
线性分类
kNN主要缺点:
- 分类器必须要记住所有训练数据才能够用来和测试数据进行比对,而实际中的数据集可能会非常大
- 分类过程计算量巨大
后面将会引入更加强大的分类器,并逐渐发展到神经网络。这些分类器还是分成两个部分:映射部分和损失函数。映射部分就是模型要训练的部分。
将图片映射到类别的分数
模型的映射部分就相当于一个评分器,评价一张图片是某个类别的可能性是多大。映射部分函数的定义是:有训练数据 ,每张拥有一个对应的标签 , 且 。N是训练数据数目,K是类别总数目。评分函数就是 ,这个函数输入的是图片,输出是图片在各个类别上的可能性。
映射可以表示成:
注意,上面还是线性的映射,所以在这基础上建立的分类器还是线性分类器。
注意:
- 每行 对应的是一个类别的分类器,每次 计算就会并行地计算十个类别上的可能性。
- 计算出来结果应该是图片真正对应的类别上的分数最高
- 这种方法的好处是可以在训练好 之后直接扔掉训练集而只保留训练好了的
- 计算都是矩阵加减,所以比NN那种直接比较两张图片不同的方法快很多
在训练者中通常会为了方便把 和 合并在一起,并且在输入的图片尾部增加个元素 。只是一个小技巧,实际上公式还是 ,但是可以让代码简介一点,也不用单独训练两个矩阵。
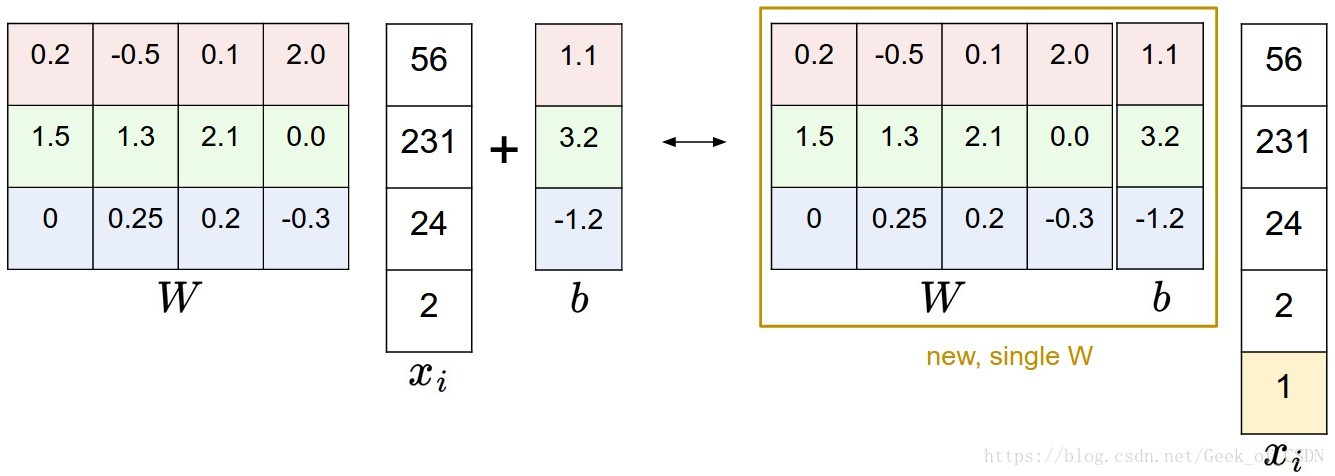
损失函数
损失函数是用来计算预测的分数和实际标签之间的差距的。损失函数计算出来的数值低模型不一定很理想(可能过拟合),但是如果高的话那么肯定不理想(根本没有学习到图片中的规律)。
多分类的SVM的损失函数
令映射关系为 , 是输入的数据, 是每张图片对应的正确标签。令映射部分最终输出的单个类别对应的向量 ,那么可以定义损失函数:
总的来说就是这里的损失函数的输出要么是0,要么是错误类别上分数逐次减去正确类别上的分数,然后把这些差加在一起,上面的 相当于是想要让正确类别上的分数超出其他类别的分数的数值(不懂的话可以看下面的例子)。
例子: ,第一个类别是正确的类别。假设 ,那么可以得到损失函数的输出:
那么第一项的解果是0,第二项的结果是8(可以这样想:正确类别上分数只有13,比错误类别上的大2,但是要求是大10,所以输出是8)。
因为 ,所以损失函数可以写成:
就是 的第 行,记住类别模板对应的就是 的某一行向量。
上面的损失函数可以表示成下面这张图。

还有一种损失函数是L2-SVM,其实就是 ,多了个平方。
正则化:
有些时候损失函数完全为0的时候模型反而可能完全没训练好,因为如果模型 对所有的类别都输出同样的分数,那么损失函数会等于0,但是实际使用中模型的表现并不好,这是因为 没有办法区分不同的类型,各行的类别模板可能非常相似。
为了解决这个问题就要对损失函数加多一个项,正则化惩罚项 。最常见的惩罚想是L2形式的,也就是这样:
其实就是把W上所有的元素都给平方然后加起来了。
加入了正则化惩罚项之后的多分类SVM损失函数才是完整的:

是训练集的照片数目,上面的超参数 通常由交叉验证后的结果决定。
加入正则化惩罚项其实还有别的好处,例如可以增加模型的泛化能力,因为惩罚可以让权重保持在相对比较小的数值上,所以可以保证不会出现某一部分元素直接决定了分类的结果的情况,这样可以保证模型在不同数据上的适应能力。
注意,通常只对权重 进行正则化,因为偏置项 并不会直接影响到输入像素对应的权重(虽然实际上还是有一点影响的)。正则化惩罚项不可能为0,因为惩罚项只有在所有权重都为0的时候才是0( 全为0那么没意义了)。
模型训练好的标志就是模型损失函数取得的值要尽可能小(在没出现过拟合的前提下)。
现实中要考虑的问题
Delta的值的选取
在大部分情况下 都可以直接取1。因为损失函数本身的定义式是:
展开来就是:
所以 和 其实控制的是损失函数中的数据损失和正则化损失之间权衡。而因为权重 直接影响分类结果,通过改变自己的数值大小来控制分类之后不同类别之间的差异大小,所以不同分类分值之间边界的具体值是没有意义的。真正影响到权衡的是 ,因为权重的大小直接影响到这个值,所以限定 可以限定权重的变化范围(因为训练模型到最优在某种程度上就是让损失函数最小)。
Softmax
两个最常用的分类器分别是SVM和softmax。softmax的损失函数和SVM不同,但是还是有评分,只是在直接输出评分之前先进行了处理,视为每个分类未归一化的对数概率,并且将折叶损失替换成了交叉熵损失。公式:
上面的 就是评分向量 中的第 个元素。整个数据集的损失值是数据集中所有样本数据的损失值 的均值与正则化损失 之和。其中函数 就是softmax函数(输入值是向量,向量的元素是评分值,函数输出是概率响亮,向量里面所有的元素的和是1,其实就相当于把输出的分数给正则化了)。
SVM最终的输出可以看作是对输入是对应类别上的评分(但是因为没有标准,所以具体分数的意义不明),而softmax可以看作是一种归一化了的属于某一类别的概率(可以用概率来解释)。
概率论角度解释(原笔记有信息论解释,但是贫僧看不懂):原方程可以变成这样:
这可以看作是经过规范化之后的输入图片被归类到正确类别上的概率。记住softmax分类器接受的评分值看作没有归一化的对数概率,所以把这些当成指数函数的幂输入到指数函数的时候,就可以得到没归一化的概率,除法操作才对数据实现了归一化处理(所以最后面数出来的和为1)。(后面这一部分贫僧不是很明白,主要是缺失了相关的概率论知识)这样操作就相当于实在最小化正确分类的负对数概率,可以看作是在进行最大似然估计(MLE)。这样就可以把损失函数中的正则化部分 看作是权重矩阵 的高斯先验,这里进行的是最大后验估计(MAP,这一个地方贫僧也是不懂。。。)而不是最大似然估计。
实际操作中要考虑的问题
数值稳定:编程实现的时候中间项 和 因为用的是指数函数,所以数值可能很大,可能会导致数值计算不稳定(嘛。。。毕竟计算机),所以最好用归一化技巧把大数化成小数:
C的值可以随便选(反正都数学等价了。。。当然可以随便选),但是通常会选 (原文的公式是 ,应该是写错了),变换之后最大值是0(大部分都变成了负数)。
f = np.array([123, 456, 789]) # example with 3 classes and each having large scores
p = np.exp(f) / np.sum(np.exp(f)) # Bad: Numeric problem, potential blowup
# instead: first shift the values of f so that the highest number is 0:
f -= np.max(f) # f becomes [-666, -333, 0]
p = np.exp(f) / np.sum(np.exp(f)) # safe to do, gives the correct answer说这么多,不如看张图啦
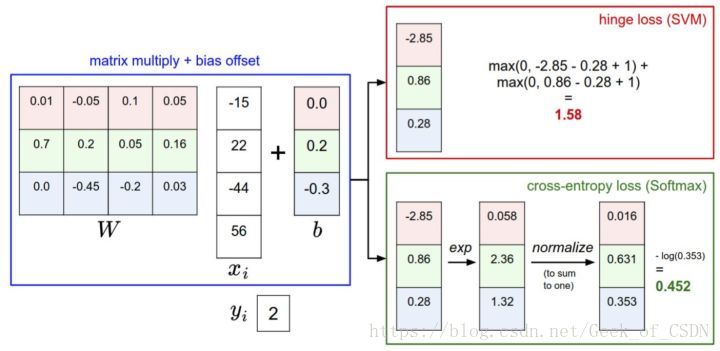
上面这张图就可以概括上面大部分的内容。因为原本的笔记里面概括就已经非常好了,所以直接摘录:
针对一个数据点,SVM和Softmax分类器的不同处理方式的例子。两个分类器都计算了同样的分值向量f(本节中是通过矩阵乘来实现)。不同之处在于对f中分值的解释:SVM分类器将它们看做是分类评分,它的损失函数鼓励正确的分类(本例中是蓝色的类别2)的分值比其他分类的分值高出至少一个边界值。Softmax分类器将这些数值看做是每个分类没有归一化的对数概率,鼓励正确分类的归一化的对数概率变高,其余的变低。SVM的最终的损失值是1.58,Softmax的最终的损失值是0.452,但要注意这两个数值没有可比性。只在给定同样数据,在同样的分类器的损失值计算中,它们才有意义。
说回到softmax分类器的“可能性”,其实这个可能性不是真的可能性,只是对输入图片属于某个类别的自信程度(可以认为是模型对输入图片属于某个类别时的“可能性”的估计),这是因为softmax给出的“可能性”其实是受到 影响的(决定了可能性的集中程度,如果 高那么对权重 的惩罚大,权重系数就会变得相对小,计算出来的分数也就更加小了,所以会让概率分布更加分散,反之亦然),而 又刚好是由你/模型设计者输入的。
来自原笔记的例子:

如果 特别大,那么权重值会越来越小,最后输出的概率会接近均匀分布。因此最后SVM和softmax一样,都要通过对最终输出的类别分数之间进行比较来确定数字的意义。
实际使用中SVM和softmax是相似的,但是SVM更加“局部目标化”,只要求最终得出的正确类别上的数值比错误类别的数值高出一定分数。而softmax要求正确类别的分数尽可能高并且错误类别的分数尽可能低。
参考资料
Linear classification: Support Vector Machine, Softmax:大部分内容都是来自这里
CS231n课程笔记翻译:线性分类笔记(下):上面笔记的中文翻译