CNN(卷积神经网络)理论知识
完成课程笔记:Convolutional Neural Networks for Visual Recognition的理解,便于实现CNN~
1. 结构概述
卷积神经网络是由层组成的。每一层都有一个简单的API:用一些含或者不含参数的可导的函数,将输入的3D数据变换为3D的输出数据。
2. 用来构建卷积神经网络的各种层
卷积层
卷积运算本质上就是在滤波器和输入数据的局部区域间做点积。过程理解如下:

池化层
作用是逐渐降低数据体的空间尺寸,这样的话就能减少网络中参数的数量,使得计算资源耗费变少,也能有效控制过拟合。
归一化层
全连接层
在全连接层中,神经元对于前一层中的所有激活数据是全部连接的,这个常规神经网络中一样。它们的激活可以先用矩阵乘法,再加上偏差。
将全连接层转化为卷积层
举个例子,如果我们想让224x224尺寸的浮窗,以步长为32在384x384的图片上滑动,把每个经停的位置都带入卷积网络,最后得到6x6个位置的类别得分。上述的把全连接层转换成卷积层的做法会更简便。如果224x224的输入图片经过卷积层和汇聚层之后得到了[7x7x512]的数组,那么,384x384的大图片直接经过同样的卷积层和汇聚层之后会得到[12x12x512]的数组(因为途径5个汇聚层,尺寸变为384/2/2/2/2/2 = 12)。然后再经过上面由3个全连接层转化得到的3个卷积层,最终得到[6x6x1000]的输出(因为(12 - 7)/1 + 1 = 6)。这个结果正是浮窗在原图经停的6x6个位置的得分!
面对384x384的图像,让(含全连接层)的初始卷积神经网络以32像素的步长独立对图像中的224x224块进行多次评价,其效果和使用把全连接层变换为卷积层后的卷积神经网络进行一次前向传播是一样的。
3. 卷积神经网络的结构
层的排列规律
最常见的卷积神经网络结构如下:
INPUT -> [[CONV -> RELU]xN -> POOL?]xM -> [FC -> RELU]xK -> FC
其中x指的是重复次数,POOL?指的是一个可选的汇聚层。其中N >=0,通常N<=3,M>=0,K>=0,通常K<3。
- 直观说来,最好选择带有小滤波器的卷积层组合,而不是用一个带有大的滤波器的卷积层。前者可以表达出输入数据中更多个强力特征,使用的参数也更少。唯一的不足是,在进行反向传播时,中间的卷积层可能会导致占用更多的内存。
层的尺寸设置规律
- 输入层(包含图像的)应该能被2整除很多次。常用数字包括32(比如CIFAR-10),64,96(比如STL-10)或224(比如ImageNet卷积神经网络),384和512。
- 卷积层应该使用小尺寸滤波器(比如3x3或最多5x5),使用步长S = 1。还有一点非常重要,就是对输入数据进行零填充,这样卷积层就不会改变输入数据在空间维度上的尺寸。比如,当F = 3,那就使用P = 1来保持输入尺寸。当F = 5,P = 2,一般对于任意F,当P = (F - 1)/2的时候能保持输入尺寸。如果必须使用更大的滤波器尺寸(比如7x7之类),通常只用在第一个面对原始图像的卷积层上。
- 为何使用零填充?使用零填充除了前面提到的可以让卷积层的输出数据保持和输入数据在空间维度的不变,还可以提高算法性能。如果卷积层值进行卷积而不进行零填充,那么数据体的尺寸就会略微减小,那么图像边缘的信息就会过快地损失掉。
经典例子(LeNet、AlexNet、ZFNet、GooLeNet、VGGNet)
计算上的考量
在构建卷积神经网络结构时,最大的瓶颈是内存瓶颈。大部分现代GPU的内存是3/4/6GB,最好的GPU大约有12GB的内存。要注意三种内存占用来源:
- 来自中间数据体尺寸:卷积神经网络中的每一层中都有激活数据体的原始数值,以及损失函数对它们的梯度(和激活数据体尺寸一致)。通常,大部分激活数据都是在网络中靠前的层中(比如第一个卷积层)。在训练时,这些数据需要放在内存中,因为反向传播的时候还会用到。但是在测试时可以聪明点:让网络在测试运行时候每层都只存储当前的激活数据,然后丢弃前面层的激活数据,这样就能减少巨大的激活数据量。
- 来自参数尺寸:即整个网络的参数的数量,在反向传播时它们的梯度值,以及使用momentum、Adagrad或RMSProp等方法进行最优化时的每一步计算缓存。因此,存储参数向量的内存通常需要在参数向量的容量基础上乘以3或者更多。
- 卷积神经网络实现还有各种零散的内存占用,比如成批的训练数据,扩充的数据等等。
CNN(卷积神经网络)代码部分
1. 全连接神经网络
- 全连接神经网络的建立(FullyConnectedNets.ipynb):
以小数据集在3层神经网络中达到20周期以内真却率100%,一开始实验结果如下:


考虑学习率过低,适当升高学习率为1e-2后,完成要求。

在考虑增加层数为5层神经网络后,调整weight_scale和learning_rate的过程艰难了许多,需要经过多次的调整才能达到要求的100%正确率,说明对于单纯的增加网络的深度,其权重的调整过程会变得特别特别的麻烦。

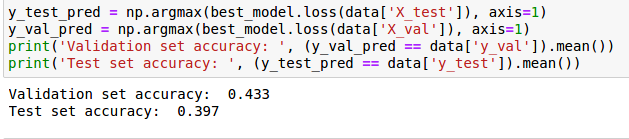
准确率也并不是很高~
-
相关层的前向与反向传播(layers.py):
affine_forward, affine_backward, relu_forward, relu_backward 函数,最后的损失函数 svm_loss, softmax_loss 因为和之前的代码一样,所以已经帮我们实现好了。
(1)affine_forward:
线性前向传播

(2) affine_backward:
线性反向传播

(3) relu_forward:

(4) relu_backward:

-
相关层的组合(layers_utils.py)

-
神经网络的参数更新方法(优化器)(optim.py):
(1)sgd:

(2)sgd+momentum:

(3)rmsprop:

(4)adam:

-
运用已有的模块实现一个两层神经网络和一个全连接网络
(1) 两层神经网络


(2)全连接网络
init:

loss:


其中需要考虑的批量归一化和dropout部分代码,在后续实现,不过需要考虑的是,批量归一化和dropout依旧包含在全连接神经网络部分中,也可以作为单独的层实现,其关系不冲突。
2. 批量归一化(batch normalization)
-
依照batchnormalization.ipynb中的步骤,实现layers.py里面的batchnorm_forward,batchnorm_backward,和 batchnorm_backward_alt 三个函数。
-
默认的 batchnorm_backward 是用计算图的方式计算的,比较快,而后面那个 batchnorm_backward_alt 是用论文里的公式直接实现的,比较容易理解。
-
在训练过程中,样本平均值和(未校正的)样本方差是根据小批量统计数据计算得出的,并用于归一化输入数据。在训练期间,我们还保留每个特征的均值和方差的指数衰减运行均值,这些均值用于在测试时对数据进行归一化。
在每个时间步,我们使用基于动量参数的指数衰减来更新均值和方差的移动平均值:
running_mean =动量* running_mean +(1-动量)* sample_mean
running_var =动量* running_var +(1-动量)* sample_var -
发现使用批量归一化可以帮助网络更快地收敛。


- batchnorm_forward:


- batchnorm_backward:

- batchnorm_backward_alt:

3. Dropout
- 按照 Dropout.ipynb 的步骤实现 cs231n/layers.py 里的 dropout_forward, dropout_backward 函数,添加 dropout 层到分类器 fc_net.py 中。
- 一般会把这一层加在激活层之后。激活值会按照 p∈[0,1] 的概率被保留,其余的都置零,这样可以有效地缓解过拟合的现象。
- dropout_forward:

- dropout_backward:

4. 卷积神经网络
- 按照 ConvolutionalNetworks.ipynb 的步骤,需要实现 cs231n/layers.py 里的 conv_forward_naive, conv_backward_naive, max_pool_forward_naive, max_pool_backward_naive, spatial_batchnorm_forward, spatial_batchnorm_backward 函数。
- 搭建一个三层卷积神经网络:
conv - relu - 2x2 max pool - affine - relu - affine - softmax
init:

loss:


CNN还是很强的,三层情况下,随意训练一下,准确率都能上40%以上:
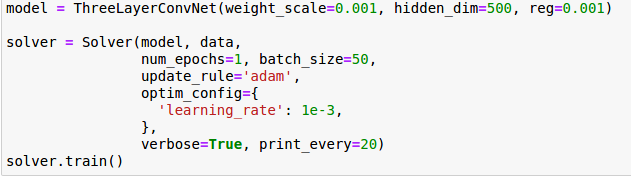

- 如果按照数学上的步骤做卷积读取内存是不连续的,这样就会增加时间成本。同时我们注意到做卷积对应元素相乘再相加的做法跟向量内积很相似,所以通过im2col将矩阵卷积转化为矩阵乘法来实现。
- conv_forward_naive:

- conv_backward_naive:

- max_pool_forward_naive:

- max_pool_backward_naive:

- spatial_batchnorm_forward:
以前我们做的BN形状是(N, D),这里不过是将(N, C, H, W)reshape为(NHW, C)。

- spatial_batchnorm_backward :
