课程作业1链接
http://cs231n.github.io/assignments2019/assignment1/
完成作业步骤
- 从链接中获取.zip为作业1的基础代码
- 将.zip解压缩

- 下载数据,需要下载CIFAR-10数据集,从assignment1目录执行以下命令:
cd cs231n/datasets
./get_datasets.sh
- 完成cs231n网页,同时参考了里面部分内容链接下有关KNN的详细介绍,之后完成knn.ipynb的代码。
有关KNN的相关知识:
- KNN主要用于图像分类,不用于图像识别
- 图像分类中的任务是预测给定图像的单个标签(或此处所示的标签分布,以表示我们的信心)。图像是从0到255的整数的3维数组,大小为宽x高x3。3表示红色,绿色,蓝色三个颜色通道。
- 采用数据驱动的方式,为计算机提供很多示例,然后开发学习算法
- 图像分类的流程:
- 输入:我们的输入包含一组N个图像,每个图像标记有K个不同的类之一。我们将此数据称为训练集。
- 学习:我们的任务是使用训练集来学习每一堂课的模样。我们将此步骤称为训练分类器或学习模型。
- 评估:最后,我们通过要求分类器预测从未见过的一组新图像的标签来评估分类器的质量。然后,我们将这些图像的真实标签与分类器预测的标签进行比较。直观地,我们希望很多预测与真实答案(我们称之为基本事实)相匹配。
NN分类器(Nearest Neighbor Classifier):
最简单的可能性之一是逐像素比较图像,然后将所有差异相加。 换句话说,给定两个图像并将它们表示为向量I1,I2,比较它们的合理选择可能是L1距离:

如何在代码中实现NN分类器:
import os
import sys
import pickle
import numpy as np
"""
load_CIFAR10()这个神奇的方法定义在 cs231n.data_utils里面,可以自行查看
"""
def load_CIFAR_batch(filename):
"""
cifar-10 数据集分batch储存,这里是载入单个batch
"""
with open(filename,'r') as f:
datadict = pickle.load(f)
X = datadict['data']
Y = datadict['labels']
X = X.reshape(10000,3,32,32).transpose(0,2,3,1).astype("float")
Y = np.array(Y)
return X,Y
def load_CIFAR10(ROOT):
"""
读取载入整个cifar-10数据集
@参数ROOT:根目录名
X:data
Y:labels
"""
xs = []
ys = []
for b in range(1,6):
f = os.path.join(ROOT,"data_batch_%d"%(b,))
X , Y = load_CIFAR_batch(f)
xs.append(X)
ys.append(Y)
X_train = np.concatenate(xs)
Y_train = np.concatenate(ys)
del X, Y
X_te, Y_te = load_CIFAR_batch(os.path.join(ROOT,"test_batch"))
return X_train, Y_train, X_te, Y_te
#载入训练和测试数据集
X_train, Y_train, X_te, Y_te = load_CIFAR10('data/cifar10')
#将32*32*3的多维数组展平
Xtr_rows = X_train.reshape(X_train.shape[0],32*32*3)
Xte_rows = X_te.reshape(X_te.shape[0],32*32*3)
已经将所有图像拉伸成行,下面是如何训练和评估分类器的方法:
#创建一个最邻近对象
nn = NearestNeighbor()
#训练:本质就是读取训练集
nn.train(Xtr_rows, Y_train)
#预测
Yte_predict = nn.predict(Xte_rows)
#比对标准答案,计算准确率
print 'accuracy:%f' % (np.mean(Yte_predict == Y_te))
将要构建的所有分类器都满足一个通用的API:它具有一个train(X,y)函数,该函数接收数据和标签以供学习。同时,类内部应当建立标签的某种模型以及如何根据数据进行预测,他是一个predict(X)函数,该函数获得数据并预测标签。
下面代码是一个简单的最邻近分类器的实现,该分类器使用L1距离:
class NearestNeighbor:
def __init__(self):
pass
#train训练函数
def train(self, X, y):
#此处就是将所有已有的图片读取进来
self.Xtr = X
self.ytr = y
#预测过程就是扫描所有训练集中的图片,计算距离,取最小的距离对应图片的类目
def predict(self,X):
num_test = X.shape[0]
#保证维度一致
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
#把训练集扫一遍
for i in xrange(num_test):
#计算L1距离,并找到最近的图片
distances = np.sum(np.abs(self.Xtr - X[i,:]),axis = 1)
#取最近图片的下标
min_index = np.argmin(distances)
#记录下label
Ypred[i] = self.ytr[min_index]
return Ypred
在assignment1目录下,运行jupyter notebook,然后运行上述代码,得到最邻近分类器的准确度如下:
约为30%

- 距离的选择。 还有许多其他方法可以计算向量之间的距离。另一个常见的选择是改为使用L2距离,该距离具有计算两个向量之间的欧式距离的几何解释。距离采用以下形式:
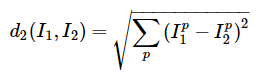
换句话说,我们将像以前一样计算像素方向的差异,但是这次我们将所有像素平方,将它们相加,最后取平方根。在numpy中,使用上面的代码,我们只需要替换一行代码。计算距离的线:
distances = np.sqrt(np.sum(np.square(self.Xtr - X[i,:]), axis = 1))
KNN分类器
- KNN图像分类思想:
进行预测时,仅使用最近图像的标签是很奇怪的,通过使用所谓的k-最近邻分类器来做得更好。这个想法很简单:不是在训练集中找到最近的单个图像,而是找到最前面的k个最近的图像,并让它们在测试图像的标签上投票。特别是,当k = 1时,我们恢复最近邻分类器。直观地说,较高的k值具有平滑效应,使分类器更能抵抗异常值,使得测试数据得到更好的泛化。 - 超参数调整的验证集:
k近邻分类器需要k的设置。同时,可以使用许多不同的距离函数:L1范数,L2范数。。这些选择被称为超参数,它们经常出现在许多从数据中学习的机器学习算法的设计中。人们应该选择哪些值/设置通常并不明显。注意:不能将测试集用于调整超参数 - 交叉验证:
假如有1000张图片,我们将训练集平均分成5份,其中4份用来训练,1份用来验证。然后我们循环着取其中4份来训练,其中1份来验证,最后取所有5次验证结果的平均值作为算法验证结果。 - 实践:
1. 准备工作(导包等)

2. 加载数据集

3. 把数据集中的一些例子进行可视化,展现出来

4. 选取部分数据进行实践(否则数据量太大)
训练集采样5000张,测试集采样500张,并将32323的图片reshape成一行:

5. 实现KNN邻近分类器
利用两层循环计算L2距离,两层循环是指从原始训练集(50000)中分两次抽取训练集数(5000)进行L2计算:
两层循环和可视化:

两层循环代码:

6. 修改predict尝试k=1,尝试k=5
首先修改predict_labels函数
 k=1:
k=1:
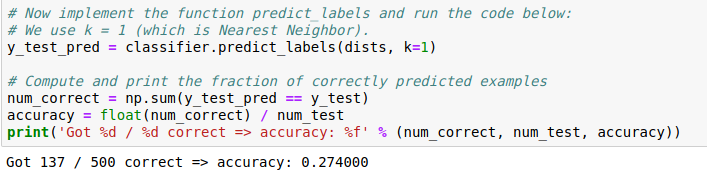
k=5:

精度比k=1时稍高;
7. 使用1层循环和使用0层循环与使用2层循环相对比:
使用1层循环,并使用范数与两层循环时的结果进行比较,验证正确性:


使用0层循环,并使用范数与两层循环时的结果进行比较,验证正确性:
(不使用loop计算L2距离就是将距离函数拆开,完成各个单项后再合并
(x - y)^2 = x^2 - 2xy + y^2)


从时间上,比较三种循环方式的优劣性:

8. 交叉验证


取平均精度,画出k-精度图:

选择最好的K,得到准确度:

9. 总结:
由此可见,KNN的分类精确度最高也就是28%左右,分类精度不高,而且是对于像素级的计算,计算量很大,效率较低,一般不在图像分类中使用。