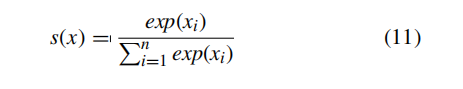An Improved convolutional network architecture based on Residual Modeling for Person Re-identification in Edge computing 论文学习记录
论文链接: https://ieeexplore.ieee.org/document/8788519
文章目录
Introduction
传统的方法不能够快速的检索行人的信息,边缘计算解决的了长延时问题得到越来越多的关注,行人重识别行人匹配任务在多个监控摄像头中,给出一个probe/target 图片,从图片库里边寻找相同人的任务。应用在很多领域,比如智能监控分析,图片数据操作,人机交互等。行人重识别技术应用边缘计算大大提高了行人信息提取的速度。
然而,每个监控摄像头被很多因素影响,比如,光照,角度,行人姿势,所以有可能导致相同行人被认为是不同人,而相似的不同人别认为是相同的人。而且,图片比较还可以用在其他领域,物体识别或检索。行人的图片经常是低分辨率并且图片的质量很差,所以行人重识别任务很困难。
近些年,主要的方法有两种,第一种,将图片分解为更小的部分。然后利用设计的模型来提取部分的特征,总得特征由部分特征组成,但是,图片的分辨率低,导致提取的特征不是很好,影响精度。而且部分特征不好提取。**第二种,改变模型的复杂度,例如,增加模型的层数,从全局的观点来看,从整个图片上提取特征是主要的方式,**但是增加太多的层数会使梯度减小甚至消失。导致提取的特征无效。
为了解决这个问题,我们利用了卷积神经网络来研究问题,采用上述的第二种方法来进行研究(改变模型复杂度),设计的结构保持了低级别的复杂度,可以运行更快在边缘设备上。
主要贡献
(1) 提出了残差模块层(residual model layers)具有两个残差模块, 可以学习到输入两张图片的高级别的特征,不仅增加了模块的深度,而且尽可能的减小梯度消失问题。残差模块包括了 ==‘直连块(identity block)’ 和 ‘卷积块(conv block)==两张图片的residual block 权重一样
(2) 采用了 全局平均池化在全连接层前 ,在一定程度上减小了模型复杂度
Related work
A. previous work on re-identification
特别的,行人重识别方法分为两类,特征提取从图像里 和 度量学习(图像提取的特征) ,一些研究集中于特征提取【4–6】,一些研究注重度量学习【7–14】,还有一些是两者的结合,【15–17】
搜索更好的特证背后的基本思想是 寻找至少部分不受灯光、姿态和视角变化影响的特性。所使用的特征包括颜色直方图[10]、[17]和局部二值模式[10]、[17]的变化。
度量学习方法的基本思想是找到一个从特征空间到新空间的映射,其中来自相同图像对的特征向量比来自不同图像对的特征向量更接近
我们的方法是学习一个有残差块的深度网络,同时找到一组有效的特征和相应的相似函数。
B 深度学习领域的person re-id
目前很多方法都是基于深度的方法来研究这些领域的课题,再此不做过多的总结了
本篇论文方法,首先用一个层包含了 填充,卷积,batch normalization(BN)批归一化,最大池化来预处理两张输入图片。为了更加快速有效的提取特征,我们利用了两个残差模块(residual block)七次,包括了五次identity block 和 conv block 来学习特征。使用一个cross input邻域差分层来比较来自一个输入图像的特征和来自另一个图像的邻域计算的特征。然后是后续的一层,它将这些局部差异提炼为更小的补丁总结特性。这一层包括一层卷积和最大池。然后,采用一种新的全局平均层对特征图进行平滑处理,并在此基础上建立两个具有softmax输出的全连通层。
Our network architecture
网络结构分为 preprocessing layers, residual model layers, a neighborhood difference layer , a feature summary layer , (global average layer ), a fully connected layer,
整体结构图

A. Preprocessing Layers
我们需要知道两张输入图片的关系来判断他们是否是同样一个人,利用深度学习可以获得高级别的特征,但是对比度和其他属性会影响特征的提取,因此,我们需要对输入图片进行预处理操作,来减小不相关因素在深度学习过程中的影响,预处理层包括 ==填充、卷积、BN层、最大池化层,==每一个卷积之后都跟着一个BN层,目标是对结果进行不同程度的归一化,提高网络正向传播的效率,减少过拟合。
其中 BN 层的计算过程如下:

B. Residual Model Layers
这一部分是整篇文章的核心点,思想来源于resnet网络结构,作者很巧妙的借鉴。
主要是如果网络结构过于深,会有梯度减小或者甚至有消失的可能出现,所以,作者,设计了残差模块层。用来提取特征用在本文中,我们基于残差建模的概念,提出了两个不同的模块:“identity”模块和“conv块”模块。“恒等块”是指输入层的值的维数与经过N次卷积后输出层中间值的维数相同。dims(ai) = dims(zi+N)
其中a为初始激活值,z为N次卷积后的中间值,i为第i层

一个identity block 模块包含了三个卷积层,权重相同,取保用相同的权重来提取特征。总共用了五次identity block ,前两次的参数一样,(卷积核大小和层数),后边三个也是一样,前后参数的变化是为了更加显著的提取特征,减小过拟合,加强稳定性

architecture of the ’identity block‘
术语“conv块”是指初始激活值“a”的维数与经过N次卷积后输出层的中间状态值“z”的维数不同,根据以往知识,需要做一个卷积来变化不同的维度使其相同,这样才可以相加。
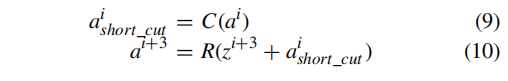
所以,conv相比于identity block 来说,多一层卷积进行维度变换,共有四个卷积层。前三层是为了提取特征,第四个卷积需要调整初始输入维度的大小。

两次conv模块使用的参数不一样!!!
C. Neighborhood Difference Layer(找差异)
涉及了相关邻域差异方法链接: https://blog.csdn.net/weixin_41427758/article/details/80253955?utm_source=blogxgwz5
经过了residual block 之后,得到了高级别的特征,64深度,接下来,我们就要找寻得到的两张图片的特征的关系。For this purpose, we use the method
of neighborhood difference processing presented in [16]

D. Feature Summary Layer
通过前边的操作,我们得到了两张图片不同差异的复杂表征。然后,利用特征总结层对邻域差分层计算出的复杂关系进行总结,学习邻域差分图之间的空间关系。
具体操作:

Fully Connected Layer
最后,我们使用一个全连接层来组合特征表示,并将学习到的分布式特征表示映射到样本标签空间,在应用全连通层之前,为了获得高阶关系,我们将feature map G和G’ 结合起来,得到一个尺寸为27×9×128的摘要feature map。我们不使用传统的扁平化方法将128个特征映射简化为单个特征向量。相反,我们对每个功能映射应用一个全局平均池层。因此,每个特征映射被简化为特征向量中的一个值。这种全局平均池操作不会破坏原始特征矩阵的空间结构信息。然后,将得到的64维特征向量通过ReLU函数传递。最后,我们将特征向量传递到一个包含2个softmax单元的全连通层,以计算这两幅图像代表同一个人或不同人的概率。softmax函数描述如下: