Improved Crowd Counting Method Based on Scale-Adaptive Convolutional Neural Network
论文地址
论文翻译
Abstract
由于各种因素的影响,例如场景变换,复杂的人群分布,照明不均匀和遮挡,人群计数是一项具有挑战性的任务。为了克服这些问题,规模自适应卷积神经网络(SaCNN)使用卷积神经网络来获得高质量的人群密度图估计,并集成密度图以获得估计的人数。为了获得更好的人群计数性能,提出了一种基于SaCNN的改进人群计数方法。优化了用于SaCNN的几何自适应高斯核的扩展参数(即标准方差),以生成用于训练的更高质量的地面真实密度图。权重为4e-5的绝对计数损失用于与密度图损失联合优化,以提高行人少的人群场景的网络泛化能力。另外,采用随机裁剪方法来改善训练样本的多样性,以增强网络泛化能力。在上海科技大学公共数据集上的实验结果表明,与SaCNN相比,该方法在人群计数上可以获得更准确,更可靠的结果。
SECTION I. Introduction
人群计数旨在估算人群场景中的行人数量,同时获得人群密度。当人群密度超过特定阈值1时,人群将很容易失控,并将严重威胁公共安全。因此,对人群计数的研究在安全领域具有重要意义,并广泛应用于视频监控,交通监控,城市规划和建设。它也是对象分割2,3,行为分析4,5,对象跟踪6,7,场景感知8,9,异常检测的组成部分10,11和其他相关任务。它可能是高水平认知能力的基础12。与其他计算机视觉问题一样,人群计数面临许多挑战,例如遮挡,人口分布不均,照明不均,比例和视角变化以及复杂的场景变化。任务的复杂性及其实际意义已引起研究人员的越来越多的关注。此外,人群计数方法可以轻松地转移到计算机视觉的其他任务,例如在显微镜下进行细胞计数13,14,车辆计数15和环境调查16。
与通常使用滑动窗口来检测每个行人并计算行人数量的基于检测的人群计数方法相比17,18,基于回归的方法在高人群计数方面很受欢迎并且性能良好人群和严重阻塞场景19 ,20, 21。对于基于回归的方法,初期的研究人员建议学习低级特征与从局部图像块中提取的人群计数之间的直接映射19,20。但是,这种基于直接回归的人群计数方法忽略了重要的空间信息。2010年,Lempitsky和Zisserman19提出要学习图像块的局部特征与其对应的密度图之间的线性映射,其中包括空间信息。然后,可以通过对密度图中的任何区域进行积分来获得该区域中对象的总数。在2015年,Pham 等人20提出学习图像块的局部特征和密度图之间的非线性映射。2016年,Wang和Zou14提出了一种基于子空间学习的快速密度估计方法,以解决现有人群密度估计方法计算效率低的问题。同年,受其他研究领域的高维特征启发,例如面部识别,徐和邱21提出了一种通过使用更丰富的特征集来提高人群计数估计性能的方法。由于最初的高斯过程回归或山脊回归太复杂而无法处理高维特征,因此采用随机森林作为回归模型。
近年来,卷积神经网络在许多计算机视觉任务中都取得了巨大的成功,这激发了研究人员使用卷积神经网络来学习从人群图像到其密度图或相应计数的非线性函数。2015年,Wang 等22首先通过使用Alexnet架构将卷积神经网络应用于人群计数任务23,将4,096个神经元的完整连接层替换为仅一个神经元的层,以估算人群图像中行人的数量。但是,该方法只能用于人群计数估计,并且不能获得图像的浓度分布信息。Fu 等24建议将人群密度分为五个等级:超高密度,高密度,中密度,低密度和极低密度。他们通过参考Sermanet 等人提出的多尺度卷积神经网络来估计人群的密度水平25,26。张等27相信当将现有方法应用于不同于训练数据集的新场景时,其性能会急剧下降。为了克服这个问题,提出了一种数据驱动的方法,用训练数据对预训练的CNN模型进行微调,以适应未知的应用场景。但是,此方法很大程度上取决于准确的角度,并且需要大量的训练数据。在2016年,Zhang 等28通过构建一个包含三列带有不同大小(大型,中型和小型)过滤器的网络,提出了多列CNN(MCNN)。它适应于由图像分辨率,透视图或行人头部尺寸引起的变化。然而,由于繁琐的训练过程和太多的参数,使得网络训练困难。2017年,Sam 等人29提出了一种交换式CNN,它根据图像中的不同人群密度通过使用一组特定的训练数据图像补丁来训练返回者。张和施30提出了规模自适应的CNN(SaCNN)来估计人群密度图并整合密度图以获得估计的人数,这在2017年获得了最新的人群计数性能。在SaCNN中,几何自适应的高斯模型优化内核以生成用于训练的高质量地面真实密度图。而且,密度图和相对人群计数损失函数用于联合优化。
为了获得更好的人群计数性能,提出了一种基于SaCNN的改进人群计数方法。优化了几何自适应高斯核的扩展参数(即标准方差),以生成更高质量的地面真实密度图。使用权重为4e-5的绝对计数损失与密度图损失共同优化,以提高行人少的人群场景的网络泛化能力。同样,原始图像被裁剪为256 × 256 随机提高训练样本的多样性,可能会增强网络泛化能力。
一般而言,我们工作的主要贡献包括:
- 通过对SaCNN中用于几何自适应高斯核的头部尺寸估计的参数设置进行分析,发现头部尺寸估计在相对稀疏的场景中导致较大的误差,这可能会影响地面真密度图的质量并降低精度人群计数。因此,对几何自适应高斯核的标准方差进行了优化,以获得更准确的磁头尺寸估计以及更高质量的地面真实密度图。
- 使用绝对计数损失函数与密度图损失共同进行优化,以提高行人少的人群场景的网络泛化能力。
- 在ShanghaiTech公开数据集上进行的实验表明,我们改进的SaCNN的性能优于原始SaCNN。
本文的组织如下。在第二部分中,将详细介绍SaCNN。第三节介绍了改进的SaCNN用于人群计数,而第四节则进行了实验并分析了结果。最后的结论在第五节中介绍。
SECTION II. Introduction on SaCNN
在SaCNN 30中,将人群图像映射到相应的密度图,然后对密度图进行积分以获得人群计数。在本节中,将详细介绍SaCNN,包括地面真密度图的生成,体系结构和实现。
A. 生成地面真相密度图
在SaCNN中,使用几何自适应的高斯核生成高质量的地面真实密度图进行训练。
假设像素处有行人头部
,用
函数
表示。三角函数应使用高斯核转化为连续密度函数
用于网络训练。考虑到场景中的透视变化,头部大小是不一致的。头部到头部的平均距离
近邻被用来估计几何畸变以获得高质量的密度图。对于给定的头部坐标
距离
最近的邻居是
,平均距离是
,因此,具有几何自适应高斯核的连续密度函数可以表示为:
其中
表示人群图像中的总头部数,散布参数
表示几何自适应高斯核的标准方差,取决于与
的平均距离(在参考文献28中,
设置为2) 每个头部坐标的近邻和系数
(在参考文献28中,它设置为0.3)。
另外,对于人群分布相对稀疏的人群场景,一些行人与其他行人之间的距离较远,这会导致较大的误差。 因此,需要将每个行人的头部的大小(高斯内核的内核大小)限制在100个像素以内(当
时,让
)。
B. Architecture
SaCNN的结构如图1所示,包括网络和损耗函数。

SaCNN的网络是通过参考VGG设计的31,保留了VGG中的前5个卷积块,下采样系数为8。为了融合
和
的特征图,将池5的步长设置为1,并采用解卷积运算上采样定影功能为原始图像的1/8。然后,使用
的跨层融合和反卷积特征图。
和
卷积层逐渐减少了特征图的数量。最后,使用带
滤波器的卷积层获得密度图,可以将其集成以获得人数计数估计。
在SaCNN中,使用密度图损失函数和相对计数损失函数共同训练网络。
密度图损失函数表示为:
其中
是要在网络中学习的一组参数,
是训练图像的总数,
是输入图像,而
是相应的地面真实密度图,
表示
的估计密度图。 欧几里得距离应用于每个像素,然后累加。
相对计数损失函数用于获得高质量的人群密度分布以进行准确的人群计数,可以将其表示为:
其中
是通过积分获得的估计头数,
是地面真头数。
SECTION III. The Improved SaCNN for Crowd Counting
本文提出的方法是基于SaCNN的,同时对几何自适应高斯核的参数设置,损失函数和实现进行了改进。在本节中,将详细介绍改进之处。
A. 改进的SaCNN的地面真相密度图的生成
地面真实密度图的质量对于基于CNN的训练模型如SaCNN具有重要意义。在SaCNN中生成用于训练的地面真实密度图的几何自适应高斯核是有效的。但是,代表磁头估计大小的内核大小和确定磁头估计大小精度的散布参数设置都可能影响地面真密度图的质量。
通过分析SaCNN中适应几何的高斯核的参数设置以生成地面真实密度图,我们发现距高斯核的平均距离
即使最近的邻居估计每个行人的头部大小也不适合稀疏人群场景,即使头部大小限制在100像素以内。如图2所示(包围框代表估计的头部大小),在密集人群中估计的头部大小是适当的。例如,对于由于透视变换而导致的较小头部大小,则到
最近的邻居也很小。但是,它不适合人群稀疏的场景。如图3所示(边界框代表估计的头部大小),估计的头部大小稍大,这导致估计值与地面实况之间存在相当大的误差,并进一步影响了生成的地面实况密度图的质量。

 因此,我们尝试优化头大小的最大限制(即
限制)和高斯核的扩展参数
(标准方差),以估计头大小。不幸的是,通过实验,我们没有找到
限制的另一种适当设置。然而,找到了高斯核的扩展参数
的适当设置。扩展参数
描述高斯概率分布的离散度。
值越大,分布越分散,而
值越小,分布越集中。因此,应将
值优化为适当较小,以使概率分布更加集中在中心区域。如图1方程式所示,
取决于系数
和
。根据我们的实验,通过将
的最大限制设置为与SaCNN的最大限制相同,同时将系数
设置为0.12,可以实现最佳性能。
因此,我们尝试优化头大小的最大限制(即
限制)和高斯核的扩展参数
(标准方差),以估计头大小。不幸的是,通过实验,我们没有找到
限制的另一种适当设置。然而,找到了高斯核的扩展参数
的适当设置。扩展参数
描述高斯概率分布的离散度。
值越大,分布越分散,而
值越小,分布越集中。因此,应将
值优化为适当较小,以使概率分布更加集中在中心区域。如图1方程式所示,
取决于系数
和
。根据我们的实验,通过将
的最大限制设置为与SaCNN的最大限制相同,同时将系数
设置为0.12,可以实现最佳性能。
B. 改进的SaCNN的体系结构
图4显示了本文使用的架构。将我们的架构与图1中的SaCNN架构进行比较,可以看出:
- (1)两种架构使用相同的网络;
- (2)在两种架构中都使用了密度图损失函数和计数损失函数来优化网络;
- (3)但是,使用SaCNN架构的计数损失函数与我们改进的SaCNN不同。
SaCNN中使用的人头计数损失函数是相对计数损失函数。如图3所示,虽然我们改进的SaCNN中使用的人员数损失函数是绝对数损失,用等式表示4。
其中 是通过积分获得的估计头数, 是地面真头数。
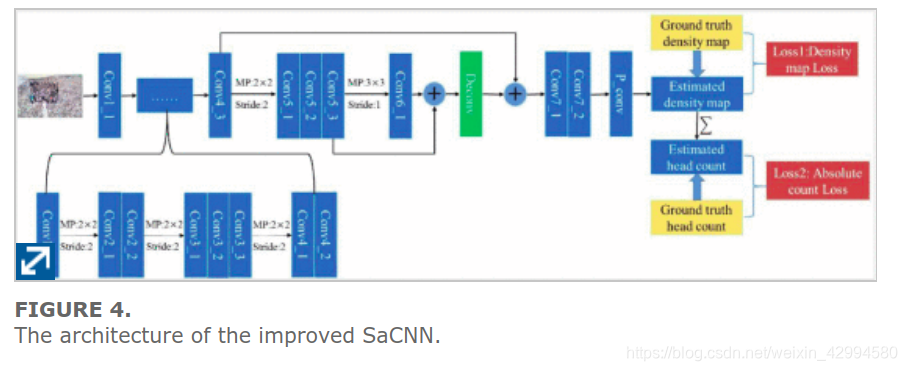
通过使用权重为4e-5的绝对计数损失代替相对计数损失,并将其与密度图损失进行联合训练,可以提高行人少的人群场景的网络泛化能力。
C. 改进的SaCNN的实施
为了提高训练样本的多样性,增强网络泛化能力,在训练过程中,采用随机裁剪方法对原始训练数据集图像中的patch进行每次迭代裁剪。由于输入图像的高度和宽度应该是8的倍数,所以裁剪后的图像块大小固定为256×256,而裁剪位置是随机的。动量优化器用于训练。初始学习率设置为1e-5,动量设置为0.9。学习率从1e-5开始,并随着均匀的等间隔变化策略而下降到1e-8。动量和batch大小与SaCNN中的相同。
SECTION IV. Experiments
实验的实施基于伯克利视觉与学习中心(BCVL)提供的Caffe框架。 用于实验的计算机是Intel(R)Xeon CPU E5-2683 v3 @ 2.00Ghz,而GPU是NVIDIA TESLA K80。 实验平台配备了64位ubuntu14.04,Anaconda3.4,CUDA Toolkit8.0和Opencv2.7.0。
A. Dataset
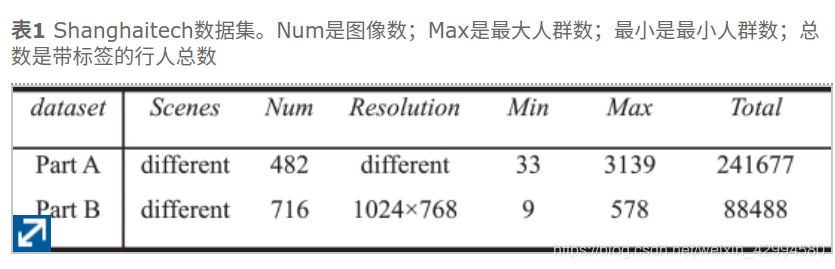
实验是在具有挑战性的ShanghaiTech数据集14上进行的,该数据集不仅具有不同的密度级别,而且具有不同的复杂场景,例如不同的比例和不同的透视变形。ShanghaiTech数据集包括两个部分:A部分和B部分,总共包括1,198张图像和330,165个带有标签的头部。A部分包括从Internet上随机选择的482张图像。B部分中的图像取自上海的街头摄影。与B部分相比,A部分包含更高密度的图像。在我们的实验中,这两个部分都分为训练集和测试集。A部分中的300和182图像分别用于训练和测试,而B部分中的400和316图像分别用于训练和测试。
B. Evaluation Metrics
平均绝对误差(MAE)和均方误差(MSE)用于评估人群计数的效果26 – 27 28。MAE反映了预测的准确性,MSE反映了预测的鲁棒性。定义如下:
其中
是测试图像的数量,
和
分别表示第
个图像中的地面真实人数和估计人数。使用较小的MAE和MSE值,性能会更好。
C. Results and Analysis
并与MCNN28、switch - cnn29和SaCNN30进行了比较,实验结果如表2所示。
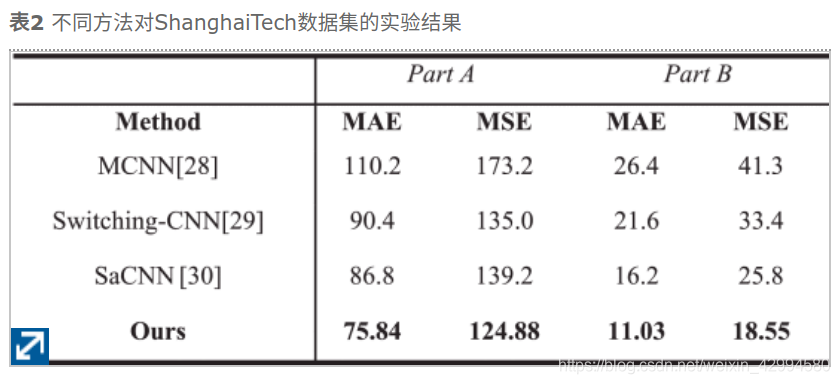
根据表2,我们改进的SaCNN的MAE和MSE对于A部分分别仅为75.84和124.88,而对于B部分,MAE和MSE分别仅为11.03和18.55。改进后的SaCNN的所有结果均优于比较方法,这表明改进后的SaCNN具有更好的估计精度和更强的鲁棒性。
图5显示了A部分的182个测试图像的地面真实头数和估计的头数。图6显示了B部分的地面的真实头计数和316个测试图像的估计的头数。带有数据标记的折线图用来显示每个测试图像的结果,这些图像根据地面真实性的值按升序排序。其中,标有菱形的蓝线代表地面真实人数。用正方形标记的橙色线表示估计的人数。用三角形标记的灰线表示估计的人数与地面真实人数之间的偏差。从图5和图6可以看出 说明我们的方法可以有效地适应不同的浓度水平,并且大多数图像的估计结果都是准确的。
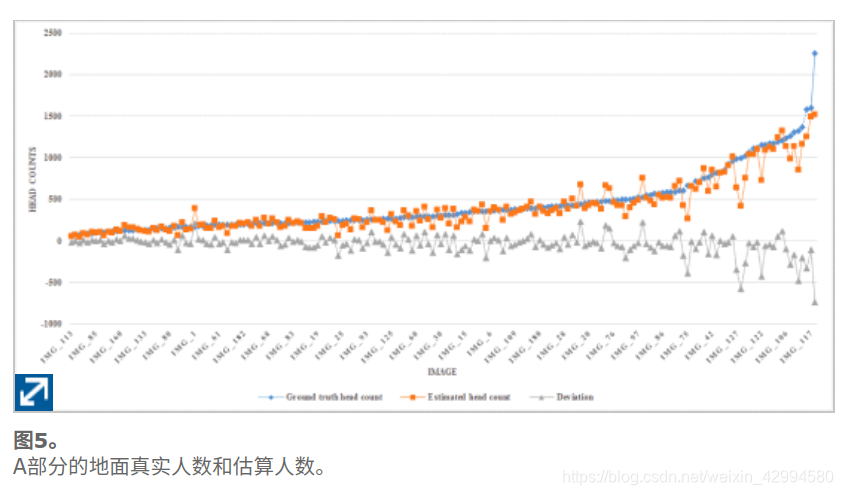
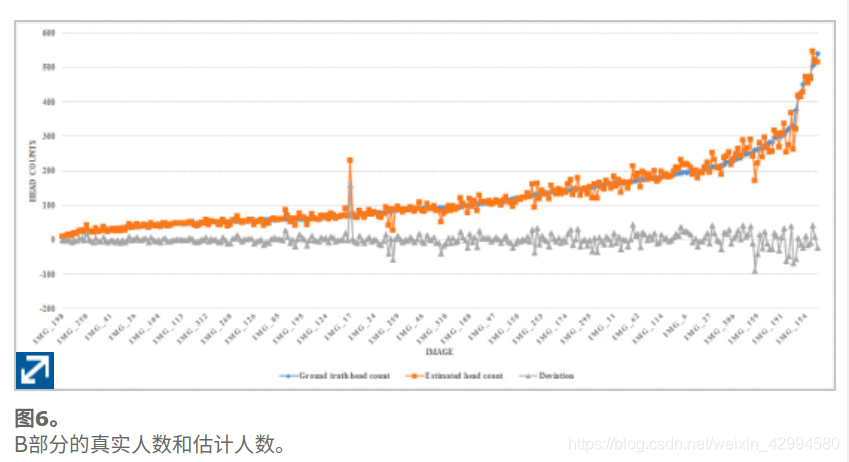 然而,对A部分和B部分(参考图5和图6)的结果的进一步分析表明,对于高密度人群图像更可能出现大的估计误差。当行人的数量超过约600时,模型的估计性能将降低并导致较大的误差。同样,估计的人数通常低于实际情况。我们对其进行了分析,发现在A部分的训练集中不同的浓度水平(大量的低浓度水平训练图像样本,而少量的高浓度水平训练图像样本)使测试结果倾向于低浓度级别,这可以作为我们未来提高人群计数性能的工作之一。
然而,对A部分和B部分(参考图5和图6)的结果的进一步分析表明,对于高密度人群图像更可能出现大的估计误差。当行人的数量超过约600时,模型的估计性能将降低并导致较大的误差。同样,估计的人数通常低于实际情况。我们对其进行了分析,发现在A部分的训练集中不同的浓度水平(大量的低浓度水平训练图像样本,而少量的高浓度水平训练图像样本)使测试结果倾向于低浓度级别,这可以作为我们未来提高人群计数性能的工作之一。
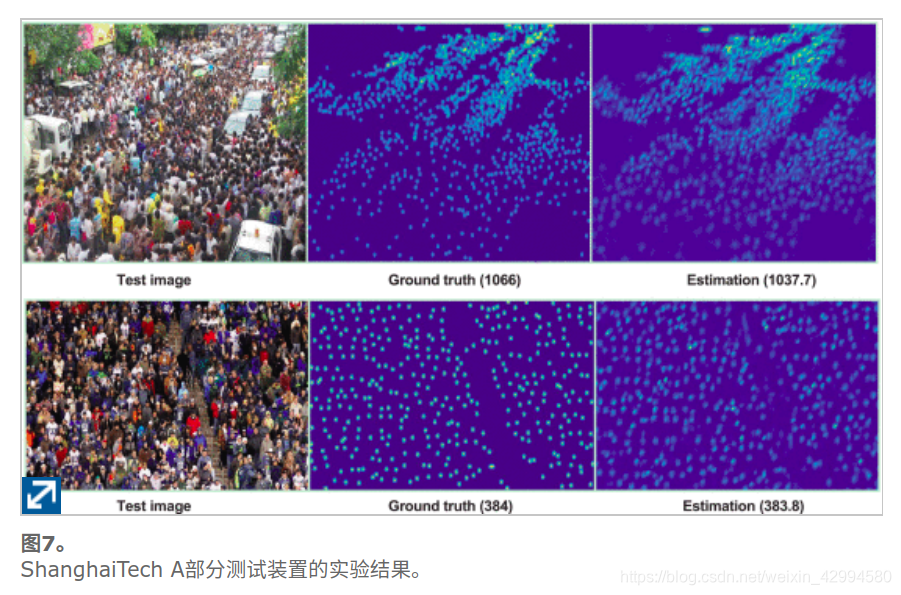
图7和图8显示了在A部分和B部分的测试集上的一些实验结果,分别包括测试图像,地面真实密度图/地面真实头数和估计密度图/估计头数。从地面真实密度图和估计密度图可以看出,我们的方法可以很好地指示图像中的人群分布是密集场景还是相对稀疏场景,而估计的人头数非常接近地面真实情况。

SECTION V. Conclusions
提出了一种基于尺度自适应卷积神经网络(SaCNN)的改进的人群计数方法,以解决密集场景中的人群计数和密度估计问题。在对SaCNN的研究和分析的基础上,对数据的预处理,损失函数等方面进行了优化,以获得更好的人群计数性能。优化了几何自适应高斯核的参数设置,以生成更高质量的地面真密度图,该图用于估计人群数。在每次迭代期间随机裁剪训练图像,以提高训练样本的多样性。使用权重为4e-5的绝对计数损失与密度图损失共同优化,以提高行人少的人群场景的网络泛化能力。
通过对现有方法的分析和我们的实验结果,我们认为:(1)密集连接的方法可增强底层特征的可重用性和传播,有利于进一步提高人群计数和密度估计的准确性;(2)在生成地面真实密度图时使用的最大头大小限制的适当设置将有助于生成高质量的密度图;(3)图像语义分割和高分辨率重建工作将是乌鸦计数的可行方法,例如使用膨胀卷积运算来增加不合并的接收场;(4)对具有更多图像的数据集进行训练可能会获得更好的结果。所有这些将是我们未来工作的重点。
J. J. Fruin, Pedestrian Planning and Design, New York, NY, USA:Metropolitan Association of Urban Designers and Environmental Planners, 1971. ↩︎
L. Dong, V. Parameswaran, V. Ramesh, I. Zoghlami, “Fast crowd segmentation using shape indexing”, Proc. Int. Conf. Comput. Vis. (ICCV), pp. 1-8, Oct. 2007. ↩︎
K. Kang, X. Wang, Fully convolutional neural networks for crowd segmentation, 2014, [online] Available: https://arxiv.org/abs/1411.4464. ↩︎
B. Zhou, X. Wang, X. Tang, “Understanding collective crowd behaviors: Learning a mixture model of dynamic pedestrian-agents”, Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), pp. 2871-2878, Jun. 2012. ↩︎
J. Shao, C. C. Loy, X. Wang, “Scene-independent group profiling in crowd”, Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), pp. 2219-2226, Jun. 2014. ↩︎
S. Yi, X. Wang, C. Lu, J. Jia, H. Li, " $L_{0}$ regularized stationary-time estimation for crowd analysis ", IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, pp. 981-994, May 2017. ↩︎
M. Rodriguez, I. Laptev, J. Sivic, J.-Y. Audibert, “Density-aware person detection and tracking in crowds”, Proc. Int. Conf. Comput. Vis. (ICCV), pp. 2423-2430, Nov. 2011. ↩︎
F. Zhu, X. Wang, N. Yu, “Crowd tracking with dynamic evolution of group structures”, Proc. Eur. Conf. Comput. Vis. (ECCV), pp. 139-154, Sep. 2014. ↩︎
J. Shao, K. Kang, C. C. Loy, X. Wang, “Deeply learned attributes for crowded scene understanding”, Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), pp. 4657-4666, Jun. 2015. ↩︎
V. Mahadevan, W. Li, V. Bhalodia, N. Vasconcelos, “Anomaly detection in crowded scenes”, Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), pp. 1975-1981, Jun. 2010. ↩︎
W. Li, V. Mahadevan, N. Vasconcelos, “Anomaly detection and localization in crowded scenes”, IEEE Trans. Pattern Anal. Mach. Intell., vol. 36, no. 1, pp. 18-32, Jan. 2014. ↩︎
V. A. Sindagi, V. M. Patel, “A survey of recent advances in CNN-based single image crowd counting and density estimation”, Pattern Recognit. Lett., vol. 107, pp. 3-16, May 2018. ↩︎
K. Chen, C. C. Loy, S. Gong, T. Xiang, “Feature mining for localised crowd counting”, Proc. Brit. Mach. Vis Conf. (BMVC), vol. 1, no. 2, pp. 3, Sep. 2012. ↩︎
Y. Wang, Y. Zou, “Fast visual object counting via example-based density estimation”, Proc. Int. Conf. Image Process. (ICIP), pp. 3653-3657, Sep. 2016. ↩︎ ↩︎ ↩︎
D. Oñoro-Rubio, R. J. López-Sastre, “Towards perspective-free object counting with deep learning”, Proc. Eur. Conf. Comput. Vis. (ECCV), pp. 615-629, Oct. 2016. ↩︎
G. French, M. Fisher, M. Mackiewicz, C. Needle, “Convolutional neural networks for counting fish in Fisheries surveillance video”, Proc. Mach. Vis. Animals Behav. (MVAB), pp. 1-10, Sep. 2015. ↩︎
T. Zhao, R. Nevatia, B. Wu, “Segmentation and tracking of multiple humans in crowded environments”, IEEE Trans. Pattern Anal. Mach. Intell., vol. 30, no. 7, pp. 1198-1211, Jul. 2008. ↩︎
W. Ge, R. T. Collins, “Marked point processes for crowd counting”, Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), pp. 2913-2920, Jun. 2009. ↩︎
V. Lempitsky, A. Zisserman, “Learning to count objects in images”, Proc. Adv. Neural Inf. Process. Syst. (NIPS), pp. 1324-1332, Dec. 2010. ↩︎ ↩︎ ↩︎
V.-Q. Pham, T. Kozakaya, O. Yamaguchi, R. Okada, “COUNT forest: Co-voting uncertain number of targets using random forest for crowd density estimation”, Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), pp. 3253-3261, Dec. 2015. ↩︎ ↩︎ ↩︎
B. Xu, G. Qiu, “Crowd density estimation based on rich features and random projection forest”, Proc. IEEE Winter Conf. Appl. Comput. Vis. (WACV), pp. 1-8, Mar. 2016. ↩︎ ↩︎
C. Wang, H. Zhang, L. Yang, S. Liu, X. Cao, “Deep people counting in extremely dense crowds”, Proc. ACM Int. Conf. Multimedia, pp. 1299-1302, Oct. 2015.v ↩︎
A. Krizhevsky, I. Sutskever, G. E. Hinton, “ImageNet classification with deep convolutional neural networks”, Proc. Adv. Neural Inf. Process. Syst. (NIPS), pp. 1097-1105, Dec. 2012. ↩︎
M. Fu, P. Xu, X. Li, Q. Liu, M. Ye, C. Zhu, “Fast crowd density estimation with convolutional neural networks”, Eng. Appl. Artif. Intell., vol. 43, pp. 81-88, Aug. 2015. ↩︎
P. Sermanet, Y. LeCun, “Traffic sign recognition with multi-scale convolutional networks”, Proc. Int. Joint Conf. Neural Netw. (IJCNN), pp. 2809-2813, Jul./Aug. 2011. ↩︎
P. Sermanet, S. Chintala, Y. LeCun, “Convolutional neural networks applied to house numbers digit classification”, Proc. Int. Conf. Pattern Recognit. (ICPR), pp. 3288-3291, Nov. 2012. ↩︎ ↩︎
C. Zhang, H. Li, X. Wang, X. Yang, “Cross-scene crowd counting via deep convolutional neural networks”, Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), pp. 833-841, Jun. 2015. ↩︎ ↩︎
Y. Zhang, D. Zhou, S. Chen, S. Gao, Y. Ma, “Single-image crowd counting via multi-column convolutional neural network”, Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), pp. 589-597, Jun. 2016. ↩︎ ↩︎ ↩︎
D. B. Sam, S. Surya, R. V. Babu, “Switching convolutional neural network for crowd counting”, Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), pp. 6, Jul. 2017. ↩︎ ↩︎
L. Zhang, Q. Chen, M. Shi, Crowd counting via scale-adaptive convolutional neural network, 2018, [online] Available: https://arxiv.org/abs/1711.04433. ↩︎ ↩︎ ↩︎
K. Simonyan, A. Zisserman, Very deep convolutional networks for large-scale image recognition, 2015, [online] Available: https://arxiv.org/abs/1409.1556. ↩︎
