基于在自然图像上训练的卷积神经网络的HEVC的感知量化策略
局部失真可见性和局部质量的快速预测模型可以潜在地使现代的spatiotem-porally自适应编码方案对于实时应用是可行的。本文提出了一种基于快速卷积神经网络的HEVC量化策略。通过对从我们改进的对比度增益控制模型导出的数据训练的网络预测本地伪像可见性。对比度增益控制模型在我们最近的自然场景中局部失真可见性数据库中进行了训练[Alam et al。 JOV 2014]。此外,提出了结构促进模型,以通过对比度增益控制模型捕获可识别结构对失真可见性的影响。我们的结果为HEVC的空间亮度通道提供了平均11%的压缩效率改进,同时需要几乎百分之一的等效增益控制模型的计算时间。我们的工作为类似的技术打开了大门,这些技术可能适用于不同的压缩标准。
大多数数字视频都经历过某种形式的有损编码,这种技术可以传输和存储大量具有越来越高分辨率的视频。现代有损编码的一个关键属性是能够将得到的比特率与得到的视觉质量进行权衡。最新的编码标准,高效视频编码(HEVC),1已成为H.264的有效继承者,特别是对于高质量视频。在这种高质量的制度中,经常寻求的目标是用尽可能少的比特数来编码每个时空区域,以保持所产生的失真不可察觉。然而,实现这样的目标需要能够准确有效地预测编码伪像的局部可见性,这是目前仍然难以实现的目标。
估计失真可见性的最常用技术是采用仅有明显失真(JND)的模型; 2 {4并且这种JND型模型已被用于设计用于图像编码的改进的量化策略。{8但是,这些方法主要基于使用非自然视频的高度控制的心理物理学研究的结果。例如,Peterson等人进行了一项实验,以确定RGB和YCrCb色彩空间中DCT基函数的视觉灵敏度;并且,这些结果已被用于开发失真可见性模型.5,10 {12但是,视频的存在可能会引起视觉掩蔽,从而改变对DCT基函数的视觉灵敏度。几位研究人员也采用了失真可见性模型speci适用于HEVC和H.264。 Naccari和Pereira通过考虑亮度,频率,模式和时域中的视觉掩蔽,为H.264提出了一个明显差异(JND)模型.13然而,编码方案基于Foley和Boynton的14对比增益 - 控制模型,不考虑V1神经元的增益控制。在另一项研究中,Naccari等人。提出了一种用于HEVC的量化方案,以基于像素强度的测量来捕获亮度掩蔽.15 Blasi等。提出了HEVC的量化方案,该方案通过根据输入模式选择性地丢弃残留信号的频率分量来考虑视觉掩蔽。然而,频率信道丢弃的方案不是基于心理物理测量。其他研究人员,例如Yu等人17和Li等人,18使用显着性信息而不是视觉掩蔽来实现HEVC的更高压缩。因此,改进编码的一个潜在领域是开发和使用不仅仅为自然主义设计的可见性模型。掩模(自然视频),但也设计为适应个人视频特征(参见,例如,参考文献19 {23,其目的在于图像的这种自适应方法)。另一个需要改进的方面是运行时性能。以块为基础的方式操作更全面的失真可见性模型以实现局部预测由于过高的计算和存储器需求而经常是不切实际的。因此,以比现有模型同时更准确和更有效的方式预测局部失真可见性仍然是一个开放的研究挑战。
在这里,我们提出了一种基于HEVC的量化方案,该方案基于为自然视频特别设计的局部伪像可见性的快速模型。该模型使用卷积 - 神经网络(CNN)架构来预测视频的每个时空区域的局部伪影可见性和质量。我们使用我们最近发布的自然场景中的局部掩蔽和质量数据库来训练CNN模型.24,25当与HEVC编码器结合使用时,我们的结果在视觉质量匹配时比基线HEVC提供了11%的压缩,同时需要百分之一等效增益控制模型的计算时间。我们的工作为类似的技术打开了大门,这些技术可能适用于不同的压缩标准。
2.变形可见性预测模型-1:具有结构促进的对比增益控制(CGC + SF)
本文描述了两种用于预测失真可见性的独立模型:(1)通过模拟具有对比度增益控制(CGC)的V1神经反应来操作的掩蔽模型;; (2)采用卷积神经网络(CNN)的模型。 CNN模型的训练数据来自CGC模型。
对比度掩模26已被广泛用于预测图像和视频中的失真可见性.5,11,12,27在许多现有的对比度掩模模型中,模拟V1神经元的对比度增益控制响应特性的模型被最广泛地使用。尽管在先前的研究中已经提出了几种增益控制模型(例如,参考文献26,28 {31),但是在大多数情况下,基于使用非自然掩模31或仅使用非常有限数量的自然图像获得的结果来选择模型参数。 20,22在这里,我们使用了Watson和Solomon提出的对比度掩蔽模型.31该模型非常适合使用通用失真可见性预测器,因为:(1)模型模拟V1神经元,因此理论上是失真类型 - 不可知的; (2)模型参数可以调整到生物学上合理的范围内; (3)模型可以直接将图像作为输入,而不是图像的特征作为输入; (4)该模型可以以空间本地化的方式运行。
我们以两种方式改进了CGC模型。首先,我们使用我们最近开发的自然场景中的局部掩蔽数据集24(目前是同类中最大的数据集)来优化CGC模型。其次,我们将结构促进模型纳入CGC模型,该模型更好地捕获了在结构化区域中观察到的减少的掩蔽。
2.1 Watson-Solomon31对比度增益控制(CGC)模型
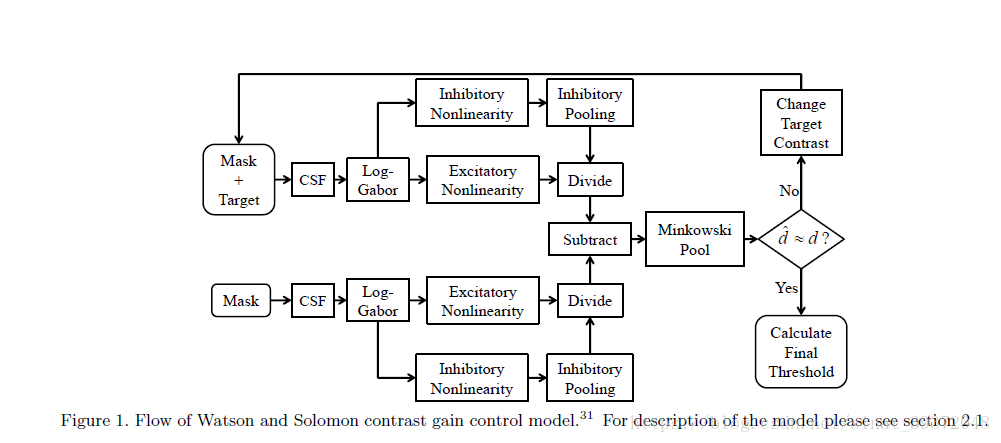
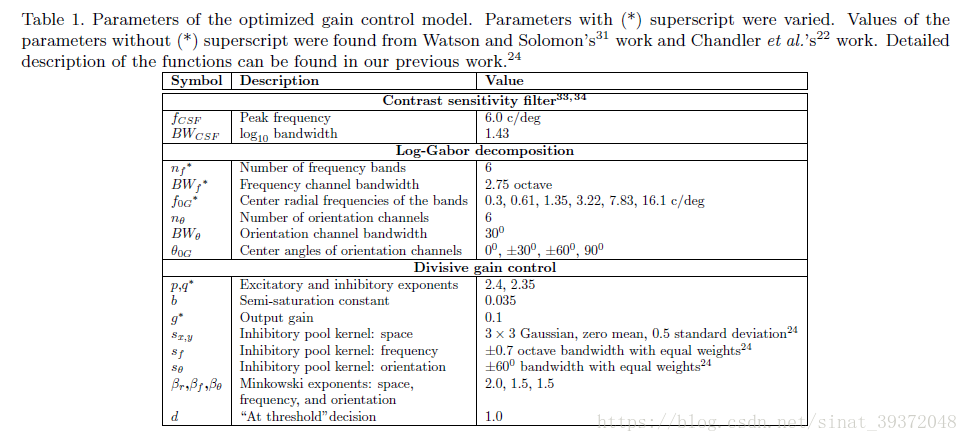
2.2结构促进(SF)模型
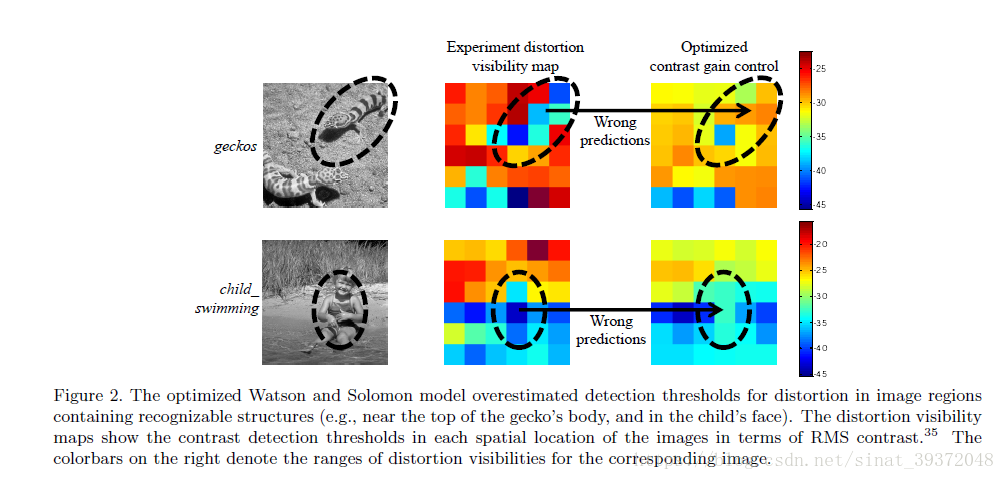
2.2.1通过减少抑制促进
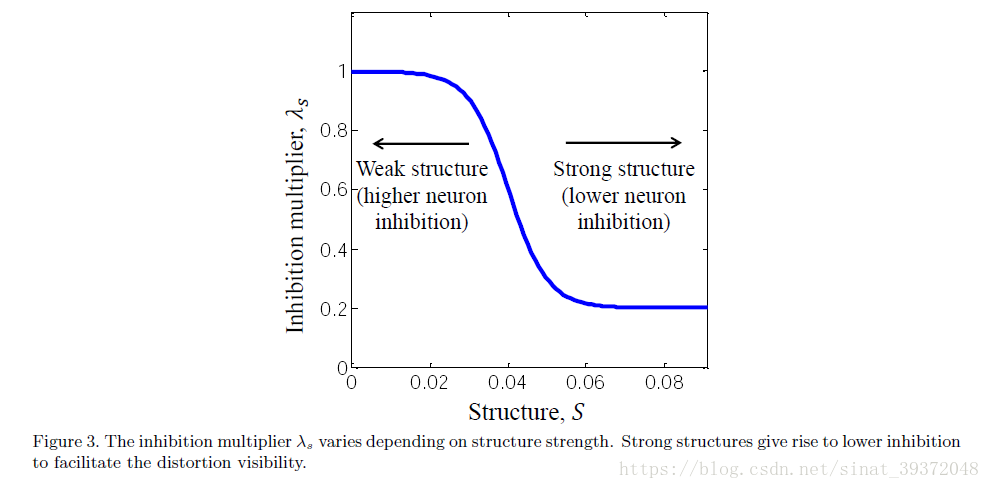

2.2.3组合(CGC + SF)模型的性能
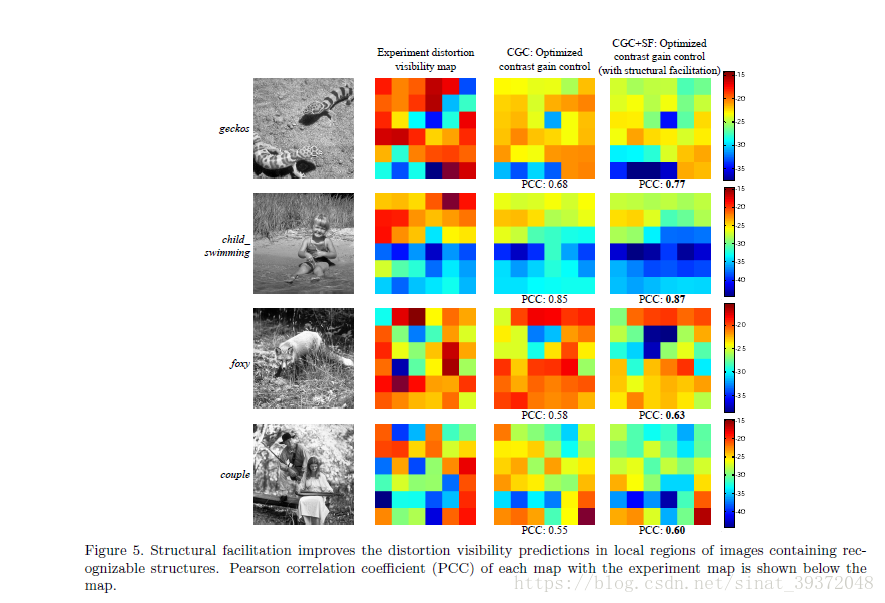
3.变形可见性预测模型-2:卷积神经网络(CNN)模型
准确性方面,CGC + SF模型在预测局部失真可见性方面表现良好。 然而,这种预测精度是以大量计算和存储器需求为代价的。
3.1 CNN Network architecture
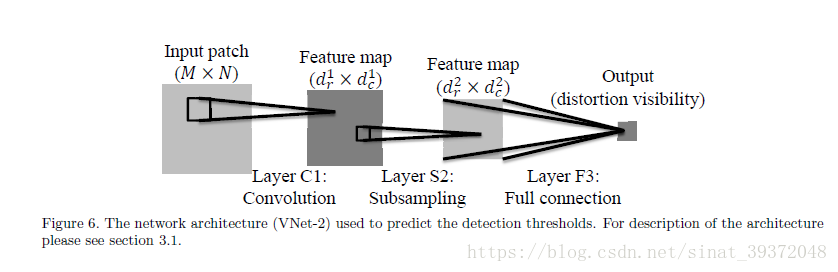
3.2 CNN training parameters
3.3 Prediction performance of CNN model
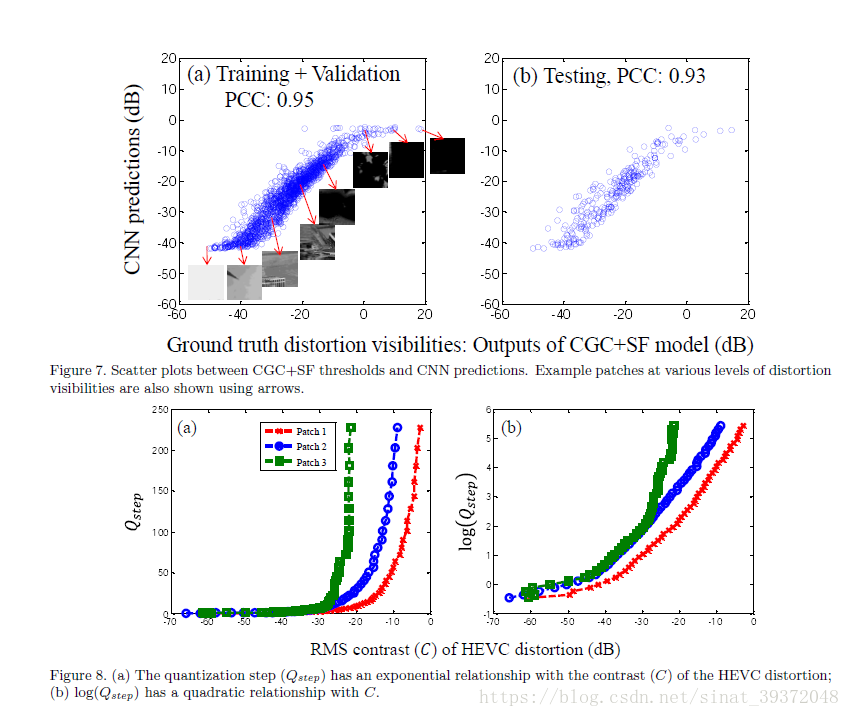
CNN模型提供了来自CGC + SF模型的阈值的合理预测。图7显示了CGC + SF阈值和CNN预测之间的散点图。对于训练+验证和测试数据,Pearson相关系数分别为0:95和0:93。从图7中,观察到散点图在可见度阈值范围的两端都是饱和的。 低于-40 dB,patch非常光滑,高于0 dB,patch非常暗。 在这两种情况下,块都没有可见内容,因此如果多个块被类似地编码,则编码伪像将是不可察觉的。
3.4使用神经网络进行QP预测
为了在HEVC编码器中使用该模型,我们因此需要预测HEVC量化参数QP,使得所得到的失真在CT处或CT下表现出对比度。