1. Residual Networks(残差网络)
残差网络 就是为了解决深网络的难以训练的问题的。
In this assignment, you will:
-
Implement the basic building blocks of ResNets.
-
Put together these building blocks to implement and train a state-of-the-art neural network for image classification.
This assignment will be done in Keras.
1.1 导入库
import numpy as np
from keras import layers
from keras.layers import Input, Add, Dense, Activation, ZeroPadding2D, BatchNormalization, Flatten, Conv2D, AveragePooling2D, MaxPooling2D, GlobalMaxPooling2D
from keras.models import Model, load_model
from keras.preprocessing import image
from keras.utils import layer_utils
from keras.utils.data_utils import get_file
from keras.applications.imagenet_utils import preprocess_input
import pydot
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
from keras.utils import plot_model
from resnets_utils import *
from keras.initializers import glorot_uniform
import scipy.misc
from matplotlib.pyplot import imshow
%matplotlib inline
import keras.backend as K
K.set_image_data_format('channels_last')
K.set_learning_phase(1)
2. The problem of very deep neural networks
-
使用深层网络最大的好处就是它能够完成很复杂的功能,它能够从边缘(浅层)到 非常复杂的特征(深层)中不同的抽象层次的特征中学习。
-
然而,深层神经网络会出现梯度消失,非常深的网络通常会有一个梯度信号,该信号会迅速的消退,从而使得梯度下降变得非常缓慢。
-
更具体的说,在梯度下降的过程中,当你从最后一层回到第一层的时候,你在每个步骤上乘以权重矩阵,因此梯度值可以迅速的指数式地减少到0(在极少数的情况下会迅速增长,造成梯度爆炸)。
-
在训练的过程中,你可能会看到开始几层的梯度的大小(或范数)下降到0 十分的快速,如下图:
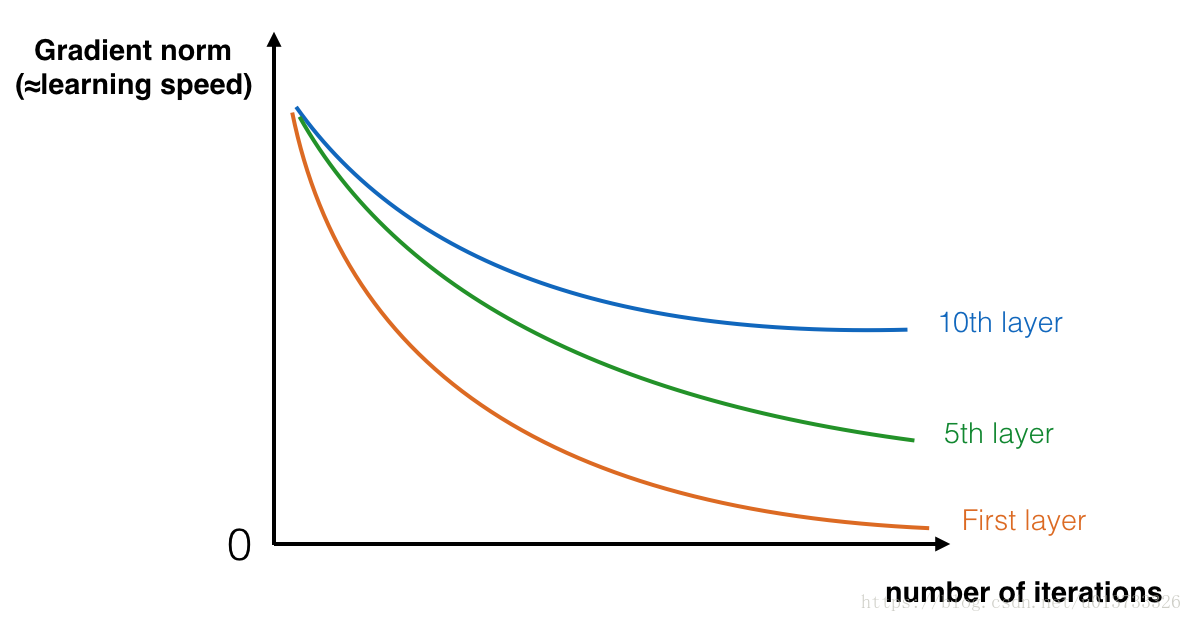
在前几层中随着迭代次数的增加,学习的速度会下降的非常快。
3. Building a Residual Network
In ResNets, a "shortcut" or a "skip connection" allows the gradient to be directly backpropagated to earlier layers:

图像右边是添加了一条 shortcut 的主路,通过把 these ResNet blocks 堆叠在一起,可以形成一个非常深的网络。
ResNet blocks有两种类型,主要取决于输入输出的维度是否相同:
3.1 Identity block (恒等块)
输入的激活值 \(a^{[l]}\) 与 输出的激活值 \(a^{[l+2]}\) 具有相同的维度
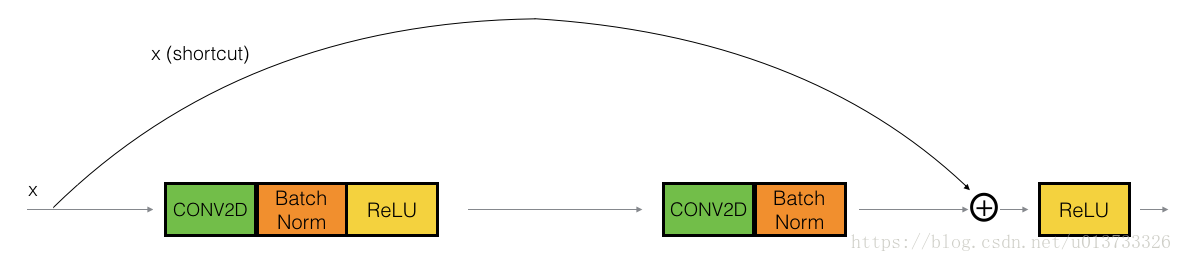
-
在上图中,我们依旧把 CONV2D 与 ReLU 包含到了每个步骤中
-
为了提升训练的速度,我们在每一步也把数据进行了 归一化(BatchNorm)
在实践中,我们要实现: skip connection 会跳过3个隐藏层而不是两个,就像下图:

Here're the individual steps.
First component of main path:
-
The first CONV2D has \(F_1\) filters of shape (1,1) and a stride of (1,1). 没有padding操作,padding=0 即"Valid convolutions" and its name should be
conv_name_base + '2a'. 使用0作为随机种子为其random initialization. -
The first BatchNorm is normalizing the channels axis. Its name should be
bn_name_base + '2a'. -
Then apply the ReLU activation function. 它没有命名也没有超参数(no hyperparameters).
Second component of main path:
-
The second CONV2D has \(F_2\) filters of shape \((f,f)\) and a stride of (1,1). 它的填充方式(padding)是 "same" and its name should be
conv_name_base + '2b'. 使用0作为随机种子为其random initialization. -
The second BatchNorm is normalizing the channels axis. Its name should be
bn_name_base + '2b'. -
Then apply the ReLU activation function. 它没有命名也没有超参数(no hyperparameters).
Third component of main path:
-
The third CONV2D has \(F_3\) filters of shape (1,1) and a stride of (1,1). 没有padding操作,padding=0 即"Valid convolutions" and its name should be
conv_name_base + '2c'. 使用0作为随机种子为其random initialization. -
The third BatchNorm is normalizing the channels axis. Its name should be
bn_name_base + '2c'. 注意这里没有ReLU函数
Final step:
-
把 the shortcut 和 the input 加到一起.
-
Then apply the ReLU activation function. 它没有命名也没有超参数(no hyperparameters).
Exercise: Implement the ResNet identity block.
-
实现Conv2D:参见这里
-
实现BatchNorm:参见这里
-
实现
activation(激活):使用Activation('relu')(X) -
To add the value passed forward by the shortcut:参见这里
# GRADED FUNCTION: identity_block
def identity_block(X, f, filters, stage, block):
"""
Implementation of the identity block as defined in Figure 3
Arguments:
X -- input tensor of shape (m, n_H_prev, n_W_prev, n_C_prev)
f -- integer, specifying the shape of the middle CONV's window for the main path
filters -- python list of integers, defining the number of filters in the CONV layers of the main path
stage -- integer, used to name the layers, depending on their position in the network
block -- string/character, used to name the layers, depending on their position in the network
Returns:
X -- output of the identity block, tensor of shape (n_H, n_W, n_C)
"""
# defining name basis
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
# Retrieve Filters
F1, F2, F3 = filters
# Save the input value. You'll need this later to add back to the main path.
X_shortcut = X
# First component of main path
X = Conv2D(filters = F1, kernel_size = (1, 1), strides = (1,1), padding = 'valid', name = conv_name_base + '2a', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2a')(X)
X = Activation('relu')(X)
### START CODE HERE ###
# Second component of main path (≈3 lines)
X = Conv2D(filters = F2, kernel_size = (f, f), strides = (1,1), padding = 'same', name = conv_name_base + '2b', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2b')(X)
X = Activation('relu')(X)
# Third component of main path (≈2 lines)
X = Conv2D(filters = F3, kernel_size = (1, 1), strides = (1,1), padding = 'valid', name = conv_name_base + '2c', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2c')(X)
# Final step: Add shortcut value to main path, and pass it through a RELU activation (≈2 lines)
X = Add()([X, X_shortcut])
X = Activation('relu')(X)
### END CODE HERE ###
return X
测试:
tf.reset_default_graph()
with tf.Session() as test:
np.random.seed(1)
A_prev = tf.placeholder("float", [3, 4, 4, 6])
X = np.random.randn(3, 4, 4, 6)
A = identity_block(A_prev, f = 2, filters = [2, 4, 6], stage = 1, block = 'a')
test.run(tf.global_variables_initializer())
out = test.run([A], feed_dict={A_prev: X, K.learning_phase(): 0})
print("out = " + str(out[0][1][1][0]))
out = [0.94822985 0. 1.1610144 2.747859 0. 1.36677 ]
3.2 The convolutional block
The ResNet "convolutional block" is the other type of block. ,它适用于输入输出的维度不一致的情况,它不同于上面的恒等块,与之区别在于,shortcut 中有一个CONV2D层,如下图:
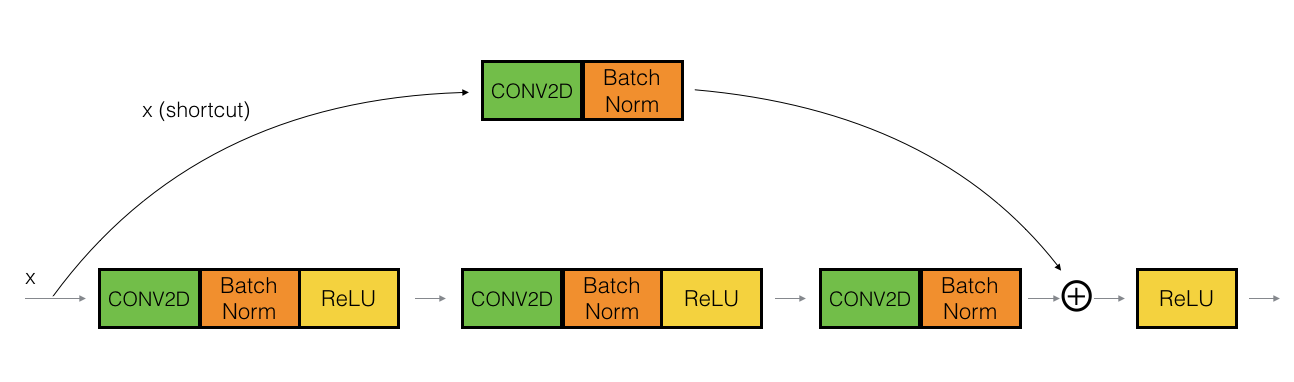
The CONV2D layer in the shortcut path is used to resize the input \(x\) to a different dimension, so that the dimensions match up in the final addition needed to add the shortcut value back to the main path. (\(W_s\))
For example, 把 the activation dimensions's height and width 减少一半, 你可以使用 a 1x1 convolution with a stride of 2. The CONV2D layer on the shortcut path 不使用任何 non-linear activation function. 它主要作用是 应用一个学习后的 linear function 来 reduces the dimension of the input, 以便在后面的加法步骤中的维度相匹配。
The details of the convolutional block are as follows.
First component of main path:
-
The first CONV2D has \(F_1\) filters of shape (1,1) and a stride of (s,s). 没有padding操作,padding=0 即"Valid convolutions" and its name should be
conv_name_base + '2a'. -
The first BatchNorm is normalizing the channels axis. Its name should be
bn_name_base + '2a'. -
Then apply the ReLU activation function. 它没有命名也没有超参数.
Second component of main path:
-
The second CONV2D has \(F_2\) filters of (f,f) and a stride of (1,1). Its padding is "same" and it's name should be
conv_name_base + '2b'. -
The second BatchNorm is normalizing the channels axis. Its name should be
bn_name_base + '2b'. -
Then apply the ReLU activation function. 它没有命名也没有超参数.
Third component of main path:
-
The third CONV2D has \(F_3\) filters of (1,1) and a stride of (1,1). 没有padding操作,padding=0 即"Valid convolutions" and it's name should be
conv_name_base + '2c'. -
The third BatchNorm is normalizing the channels axis. Its name should be
bn_name_base + '2c'. Note that there is no ReLU activation function in this component. -
注意这里没有ReLU函数
Shortcut path:
-
The CONV2D has \(F_3\) filters of shape (1,1) and a stride of (s,s). 没有padding操作,padding=0 即"Valid convolutions" and its name should be
conv_name_base + '1'. -
The BatchNorm is normalizing the channels axis. Its name should be
bn_name_base + '1'. -
注意这里没有ReLU函数
Final step:
-
把 the shortcut 和 the input 加到一起.
-
应用 ReLU activation function. 它没有命名也没有超参数.
Exercise: Implement the convolutional block.