文章目录
Flow Sequence-Based Anonymity Network Traffic Identification with Residual Graph Convolutional Networks
中文题目:基于流序列的匿名网络流量识别残差图卷积网络
发表会议:2022 IEEE/ACM 30th International Symposium on Quality of Service (IWQoS)
发表年份:2022-6-10
作者:Ruijie Zhao, Xianwen Deng, Yanhao Wang, Libo Chen, Ming Liu, Zhi Xue, and Yijun Wang
latex引用:
@article{shen2021accurate,
title={Accurate decentralized application identification via encrypted traffic analysis using graph neural networks},
author={Shen, Meng and Zhang, Jinpeng and Zhu, Liehuang and Xu, Ke and Du, Xiaojiang},
journal={IEEE Transactions on Information Forensics and Security},
volume={16},
pages={2367--2380},
year={2021},
publisher={IEEE}
}
摘要
从网络流量中识别匿名服务是网络管理和安全的重要任务。目前,一些基于深度学习的研究在交通分析方面取得了很好的效果,特别是基于流序列(FS)的研究,它利用了交通流的信息和特征。
然而,这些模型仍然面临着严峻的挑战,因为缺乏考虑流之间关系的机制,导致错误地将FS中不相关的流视为识别流量的线索。
在本文中,我们提出了一种基于FS的匿名网络流量识别框架,该框架利用残差图卷积网络(ResGCN)利用流之间的关系进行FS特征提取。此外,我们设计了一种实用的方案对真实交通的原始数据进行预处理,进一步提高了识别性能和效率。
在两个真实交通数据集上的实验结果表明,我们的方法在很大程度上优于目前最先进的方法。
存在的问题
- 目前的一些基于人工智能的流量分析方法忽略了流之间的一些关键关系,导致错误地将流序列中不相关的流作为流量识别的线索。由于目前基于DL算法实现的方法(如CNN和LSTM)在结构上的限制,在特征提取过程中不能考虑下面这两种关系。
关键关系:
属性关系。同一应用请求生成的正向流(F-flow)和相应的反向流(R-flow)具有属性关系。
时间关系。时间关系表示流之间的时间间隔。区间越长,二者之间的相关性越低。解决方案:
图卷积网络(GCN)通过不同权重的边连接邻居节点,通过计算邻居节点的特征和更新特征表示,提供了一种根据流之间的关系连接流的方法来解决这一问题。
论文贡献
- 提出利用流之间的属性和时间关系,实现更合理有效的流序列特征提取,用于交通识别。我们假设图卷积网络(GCN)适合我们的目的,并提出了一种新的RESGCN模型来识别不同的网络服务。
- 设计了一个实用的方案来处理真实世界的原始交通数据。它考虑了流量分割,用于生成和丰富原始流量的流量特征,以及基于lightgbm的特征组合,避免了不重要的特征降低模型性能和效率。
- 在两个真实的流量数据集上评估该框架。实验结果表明,该方法具有较好的分类性能,适用于不同网络服务的识别。
1. 问题和方法概述
-
流生成器

由于同一类型的网络行为通常会持续一段时间,建立流序列进行分析成为提高分类性能的有效方法。显然,每个序列中的流之间存在一些关系(即属性和时间关系)。如果在特征提取过程中能够考虑到这些关系,分类器网络的设计将更加合理有效。不幸的是,目前还没有相关的工作将这些关系结合起来进行特征提取。难点:
- 在流生成过程中,许多变量会影响生成的结果。首先,流量可以根据不同的持续时间或数据包大小进行分段,直接影响相关统计的计算结果。需要找到一个最优的参数来分割流量。
- 生成的流量包含不同的统计特征,但有些可能对流量识别没有意义。需要筛选其中比较重要的特征。
解决方案的考虑因素:
- 有效性:有效性是指分类器可以利用生成的流获得优秀的分类性能。
- 时效性:时效性意味着匿名服务可以尽快被识别出来。
-
LightGBM用于特征选择
在有效性方面,不重要的特征在一定条件下会被表征为噪声,这会影响识别结果。
在时效性方面,去掉这些特征可以减少流量生成过程中统计量的计算,加快流量生成速度。此外,低维特征也会降低特征提取网络的复杂度和分类时间。使用LightGBM的原因:
- LightGBM是一种基于梯度增强决策树(GBDT)的ML算法。由于GBDT算法在训练过程中对特征的重要性进行排序,因此非常适合于特征选择任务。
- 传统的基于GBDT的算法(如XGBoost,PGBRT)都是耗时的,因为他们必须扫描每个特征的所有样本点,以选择最佳分割点。LightGBM通过基于梯度的单边采样(GOSS)算法大大降低了处理样本的时间复杂度。(GOSS算法的主要思想是,具有较大梯度的样本在计算信息增益时起主要作用,这意味着这些具有较大梯度的样本将贡献更多的信息增益。因此,为了保持信息增益评价的准确性,在对样本进行下采样时,可以保留梯度大的样本,对梯度小的样本按比例随机采样。由于减少了大量梯度小的数据样本,计算量大大减少。)
-
用于特征提取的GCN
在本研究中,我们将流序列看作一个图,每个流是图中的一个节点。根据不同流之间的关系形成连接关系。有关GCN的相关数学推理和用法,可以看我的另一篇文章
-
论文方法
- 第一步: 配置交换机镜像端口,使用流量捕捉工具tcpdump获取实时流量,并保存为一系列pcap文件。流量采集频率根据实际情况而定。
- 第二步:利用流生成器实现对pcap文件的快速实时分析。根据预先设定的规则,抽取pcap文件中的流。流序列由多个连续流组成,在此步骤中还将生成不同流之间的关系图。然后,采用基于lightgbm的特征选择方法选择最优特征组合。
- 第三步:提出的RESGCN分类器利用生成的关系图实现了有效的匿名网络流量识别。
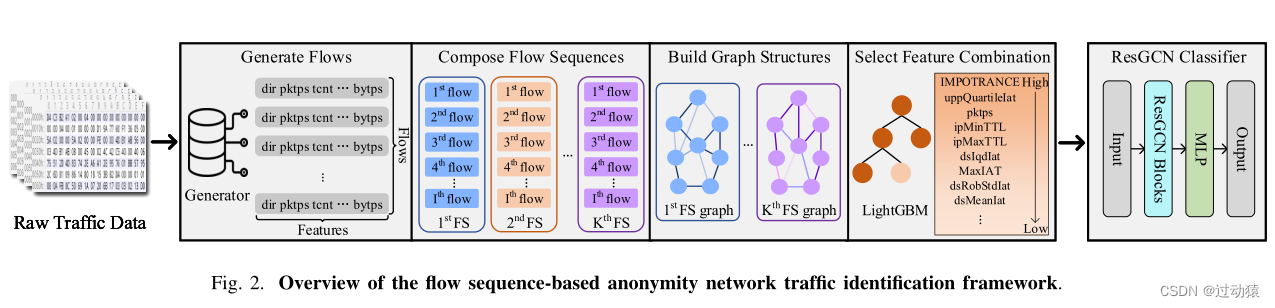
2. 匿名网络流量识别框架
-
原始流量数据处理方案
- 生成流:
任务:从pcap包中提取流
在真实的流量中,例如BitTorrent提供的服务会导致非常长的流量持续时间。如果不对长时间流进行分段,将会影响分类效率。
流量分割方案可以分为两类:
(1)基于时间的:基于时间的分割方案设置了流量持续时间的上限
(2)基于规模的:基于大小的分割方案设置了最大报文大小的上限因此,我们首先使用生成器通过基于时间或基于大小的流量分割方案从原始流量中生成丰富的特征。然后,采用以下标准归一化方法来提高数据的可靠性:
z = ( x − μ ) / σ z = (x-\mu)/\sigma z=(x−μ)/σ- Compose Flow Sequences
任务:对生成的流进行分组,形成流序列
如果流序列中的flow过少:会导致信息不足,无法达到理想的分类性能
如果流序列中的flow过多:会增加计算量,降低效率因此,我们将每个流序列设置为包含八个连续流。
- Build Graph Structures
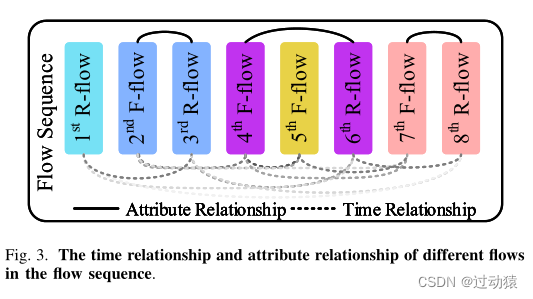
任务:对每个流序列都分别产生一个图
图的生成是GCN成功应用的关键。我们希望通过图形结构对流序列进行更有效、合理的分析。显然,每个序列中的不同流之间存在许多关系。我们从以下两个方面构建图结构。
- 属性关系图(Attribute Relationship Graph,ARG):
应用程序请求生成的F-flow和Rflow之间的关系被定义为属性关系。
三元组:(flow index,transmitted bytes, received bytes)
flow index:根据(源/目的IP、源/目的端口、协议)来生成连接两个flow的条件:
(1)两个流具有相同的流索引
(2)并且交换了发送字节数和接收字节数基于三元组,我们将F-flow和R-flow连接起来,并将它们的属性关系权值设为1。
G a ( V , E ) = 3 T u p l e M a t c h i n g . G_a(V, E) = 3TupleMatching. Ga(V,E)=3TupleMatching.- 时间关系图(Time Relationship Graph, TRG):
连续的多个流根据流的产生时间依次排列。流量产生时间越近,证明它们的相关性越强,权重设置得就越高。
连接两个flow的条件:
(1)同为F-flow或同为R-flow假设排序后的第a个流为 f l o w a flow_a flowa,第b个流为 f l o w b flow_b flowb。那么两个流之间的距离为 ∣ B − A ∣ |B−A| ∣B−A∣,初始权值为: 1 / ∣ B − A ∣ 1/|B−A| 1/∣B−A∣,即 G t ( V , E ) = d i s t a n c e − 1 G_t(V, E) = distance^{−1} Gt(V,E)=distance−1
为了更合理地设置各流程的时间关系权重,我们将各流程的时间关系权重输入到Softmax函数中,使新权重之和为1。假设我们在一个流中有n个时间关系权重,我们可以将这个过程表示为: w 1 ′ , w 2 ′ , . . . , w n ′ = S o f t m a x ( w 1 , w 2 , . . . , w n ) w^′_1, w^′_2, ..., w^′_n = Sof tmax(w_1, w_2, ..., w_n) w1′,w2′,...,wn′=Softmax(w1,w2,...,wn)
在建立ARG和TRG后,我们对这两个图的邻接矩阵进行归一化,得到融合图。
- Select Feature Combination
任务:使用lightGBM来计算flow中每个特征的重要性,进行特征选择
输入:所有流:flows,形状:[flows_num,features_num]
输出:所有流的label(流的类别),形状:[flows_num,1]
中间产物:flow中每个特征的重要性 -
基于流序列的RESGCN分类器
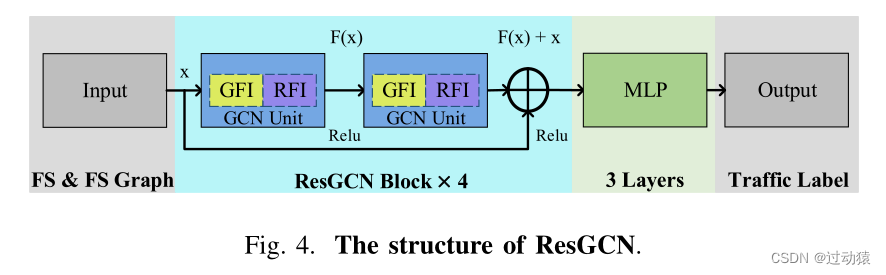
输入:FS & FS Graph。由8个连续流组成的流序列,其中每个流都被视为图中的一个节点。
ResGCN block:由2个GCN Unit组成。
GCN Unit:包括两个关键组件,即生成的特征交互模块(GFI)和相关流程交互模块(RFI)
- GFI是一个完全连接的无偏置层。它对每个流的特征(例如包间隔、包大小等)执行线性转换,允许不同的特征相互作用。
- RFI允许相关流基于关系图交换信息。
根据上述的融合图,这两个模块可以在不同的特征和相关流程上进行有效的信息交互。
这里论文写得不太清晰,我的理解是:
(1)首先上面得到了两个图,即ARG和TRG,假设ARG得邻接矩阵为 A 1 A_1 A1,TRG的邻接矩阵为 A 2 A_2 A2,那么最终得到的融合邻接矩阵就是: A = A 1 + A 2 A = A_1 + A_2 A=A1+A2
(2)假设一个流序列的特征矩阵为H(形状为[8,features_num])
(3)首先要经过GFI模块。GFI是一个无偏置的全连接层,用公式表示为: H ′ = W T ∗ H H' = W^T * H H′=WT∗H 其中, W : [ f e a t u r e s n u m , e m b e d d i n g n u m ] H ′ : [ 8 , e m b e d d i n g n u m ] \\W:[features_num, embedding_num]\\H':[8, embedding_num] W:[featuresnum,embeddingnum]H′:[8,embeddingnum]
(4)然后再经过RFI模块,用公式表示为:
H ′ ( l + 1 ) = δ ( D ~ − 1 / 2 A ~ D ~ − 1 / 2 H ′ ( l ) W ′ ( l ) ) H'^{(l+1)} = \delta(\widetilde{D}^{-1/2}\widetilde{A}\widetilde{D}^{-1/2}H'^{(l)}W'^{(l)}) H′(l+1)=δ(D −1/2A D −1/2H′(l)W′(l))使用dropout层提高模型泛化能力,减少过拟合。最后,对退出层输出进行平化处理
使用2个隐藏层和1个输出层的3层MLP进行流分类。第一个隐藏层由输出大小为220的线性层组成,后面是整流线性单元(ReLU)。第二个隐藏层具有类似的结构,但输出大小为110。
总结:
Input层 -> 4 * ResGCN block -> dropout -> flattern -> linear1(xx*220)-> ReLU -> linear2(220*110)-> ReLU -> output(110*类别)
注意:根据与作者的沟通得知,该GCN模型是一个graph-level的模型,即每个图只生成一个label,这就需要先对原始pcap包按照label进行划分,得到多个不同类别的pcap包,再使用Tranalyzer2对每个pcap包各自提取流特征,然后各自生成图结构。
3. 效果评估
评估目标:
- RQ1:流量数据处理方案在处理真实世界的原始流量时效果如何?
- RQ2:ResGCN在真实网络流量中如何识别不同的网络服务?
- RQ3:RESGCN是否比最先进的方法获得更好的性能?
-
评估数据集
匿名网络流量分析:SJTU-AN21数据集
真实世界的流量数据集:ISCXVPN2016数据集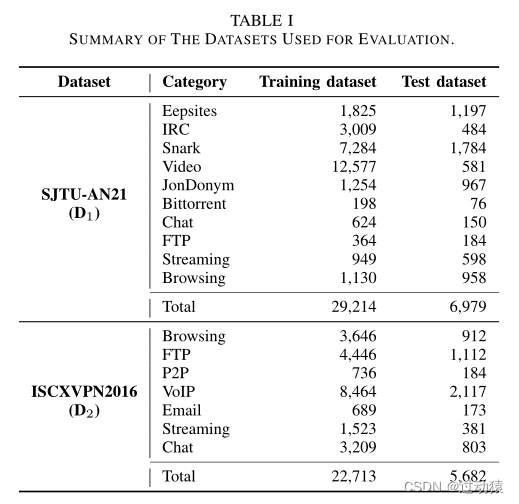
-
实验设置
- RQ1:评估了所提出的原始交通数据处理方法在不同流量分割方案和特征选择方法上的性能,并确定了后续实验的最优组合。
- RQ2:分析了ResGCN的训练过程,并讨论了测试数据集上分类结果的混淆矩阵。
- RQ3:在测试数据集上比较了ResGCN的分类性能和当前的流量分类方法。
实验环境:
python3.7 + pytorch。
硬件:Intel®Core™[email protected] GHz, 64 GB RAM、NVIDIA GeForce RTX3090 GPU。评估指标:
模型效果:Recall,Precision,F1
模型复杂度:FLOPs超参数设置:
epoch:>=100
优化器:SGD
初始学习率(initial learning rate):0.01
batch_size:80
momentum:0.9 -
原始流量数据处理方案的成效(回答RQ1)
3个影响因素:流分割方式、特征组合、流序列长度
-
流分割方式
评估了6种分割方案(即基于时间的5s、10s、15s和基于大小的5MB、10MB和15MB) -
特征组合
和3种特征选择方法(即基于pca、基于xgboost和基于lightgbm)的性能。
使用训练数据集进行特征选择,并评估我们的方法在测试数据集上的准确性 -
流序列长度
之前已经确定了,流序列长度取8,即流量切割后的8个连续的流组成一个流序列


从图中可以看出,在两个数据集上,10s特征分割方案的分类性能最好,15MB分割方案的分类性能最差。此外,通过对15MB流量分割方案的数据分析发现,使用该分割方案的许多流量的持续时间都很长,流量之间的时空相关性明显减弱,这也验证了论文中所提到的时间间隔越长,两个流之间的相关性越差的理论。
从表中可以看出,PCA进行特征提取的方法在速度上有优势,但是精度不如LightGBM。基于对速度和精度的考虑,选择LightGBM方法进行特征选择。
-
-
RESGCN分类器性能(回答RQ2)
训练过程:

注意:原图中横坐标是Number of Features,我觉得他应该是写错了,所以我就改成了Number of Epoch混淆矩阵:

ResGCN的消融实验(即删除其中某一模块后的模型效果):

-
与其他方法的比较(回答RQ3)
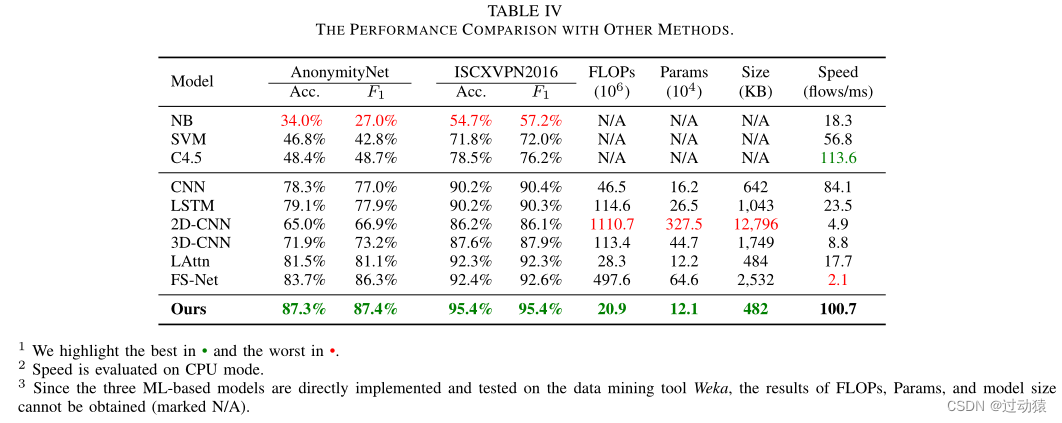
- 传统的基于ml的分类方法的分类结果通常不理想,这表明这些方法对复杂网络流量的分类能力有限
- 2D-CNN和3D-CNN模型的分类性能(即直接读取pcap文件而不计算统计特征)是非常有限的。
- CNN, LSTM和LDAE都使用统计特征和流序列来实现显著的性能改进。但由于缺乏对流序列内在关系的挖掘,仍不能达到较高的精度。
- LAttn模型通过注意机制学习了流序列之间的内在关系,从而进一步提高了模型的性能。
- FS-Net通过引入重构损失实现了对加密流量更好的特征表示,有效地提高了分类性能。但是,这种模型结构也带来了较大的参数量。
RESGCN从全新的角度设计模型结构。利用生成的关系图对流序列进行特征提取,显著提高了匿名网络流量的分类性能。
-
模型复杂度
我们分析了模型的复杂性,模型参数大小,模型大小和速度。这些评估对于某些部署非常重要,在这些部署中,一个更小的模型(或可以实时分析流量的更快的模型)比一个模型的性能分类更重要,因为如果模型过大,这个模型无法在某些设备上运行。因为内存和CPU的使用很容易受到其他程序的干扰,我们使用FLOPs来反映模型的复杂性,以评估运行模型的硬件消耗。
模型参数大小还会影响模型推断期间的内存使用。模型大小表示该模型占用的磁盘空间,速度表示该模型每毫秒可以处理的流的数量。
- 由于使用二维卷积进行特征提取,2D- cnn和3D-CNN模型都非常复杂。
- 基于lstm模型的栅极结构复杂,导致计算效率很低。
- C4.5具有快速的速度,但低于标准的分类性能限制了它的部署。
得益于GCN对流序列的有效特征提取,RESGCN可以在不需要大参数的情况下实现精确分类。
总结
本文提出了一种新的基于流序列的网络流量识别框架,该框架利用RESGCN利用流之间的属性关系和时间关系,成功地识别了不同匿名网络服务。此外,作为一种端到端的实时流量识别方法,我们的框架可以有效地处理真实的流量。它考虑了流量分割,利用原始流量生成和丰富流量特征,以及基于lightgbm的特征组合,避免了不重要的特征降低模型性能和效率。实验结果表明,RESGCN分类器由于结构设计优良,具有较高的分类精度、较低的复杂度和较快的分类速度。
1. 论文亮点
-
准确率:
(1)通过评估各种参数:比如流量分割方法(基于时间的方法:多少秒分割一次流量),特征选择的数量等等。来确认适合模型的最优参数。
(2)提出了一种ResGCN的方法来提高模型的准确率:分别从时间和属性两个角度进行构图,使得模型能够充分提取每个流之间的信息。 -
实时性:
(1)使用lightGBM来提取特征,从而保证模型提取特征的速度够快。
(2)得益于GCN对流序列的有效特征提取,RESGCN可以在不需要大参数的情况下实现精确分类。
2. 论文缺点
- 模型只能应用于对正常网络应用流量的分类,没有考虑网络中存在的恶意流量的情况,因此可以加入对正常与异常流量的分类模块,对模型进行进一步拓展。
- 模型的鲁棒性有待进一步提高,即当模型受到恶意攻击者投放的一些精心制作的流量攻击时,还能否正确对流量进行分类。
3. 工具
- 流量分析工具Tranalyzer2,安装教程
- 数据挖掘工具Weka,安装教程
4. 数据集
SJTU-AN21 dataset:https://github.com/iZRJ/The-SJTU-AN21-Dataset
ISCXVPN2016:https://www.unb.ca/cic/datasets/vpn.html