Introduction
(1)Motivation:
当前CNN无法提取图像序列的关系特征;RNN较为忽视视频序列前期的帧信息,也缺乏对于步态等具体信息的提取;Siamese损失和Triplet损失缺乏对label信息的考虑(???)。
(2)Contribution:
提出一个新的端到端网络框架,称为 CNN and RNN Fusion(CRF),结合了Siamese、Softmax 联合损失函数。分别对全身和身体局部进行模型训练,获得更有区分度的特征表示。
Method
(1)框架:
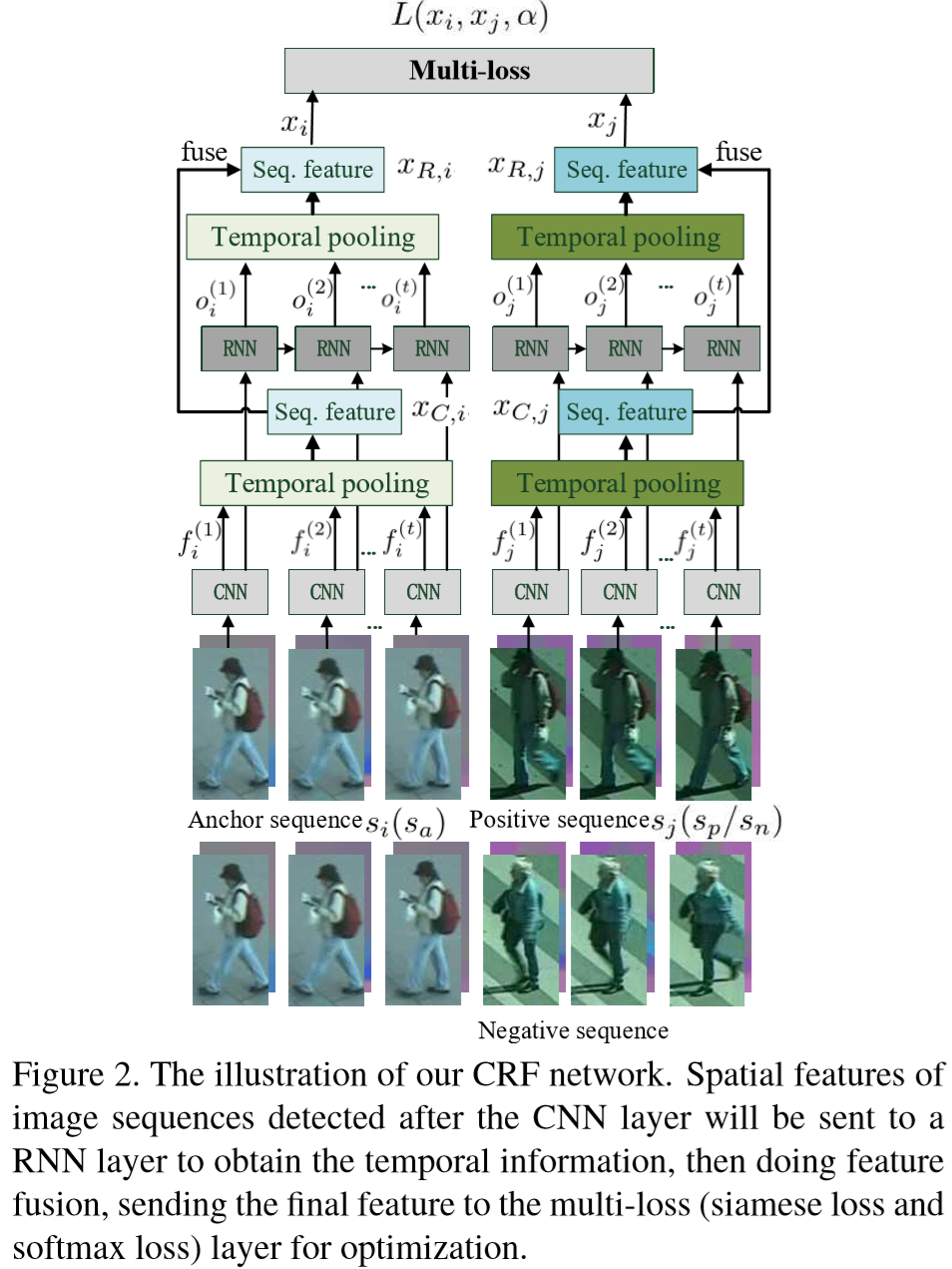
(2)输入:
输入包括两部分,原图像信息、光流信息(使得行人的步态、动作更清晰)。
(3)CNN层:
该层采用参考文献相同的CNN,详情参考【论文阅读笔记(十)【CVPR2016】:Recurrent Convolutional Network for Video-based Person Re-Identification】
包含三个卷积模块,每个模块包含:卷积层(kernel size 为5*5)、最大池化层、ReLU层。输入序列定义为:![]() ,其中 T = 16,则CNN层可以定义为:
,其中 T = 16,则CNN层可以定义为:
![]()
最终得到的特征表示为:![]()
(4)时间池化层:
采用平均池化的操作,定义为:

(5)RNN层:
结点计算如下:
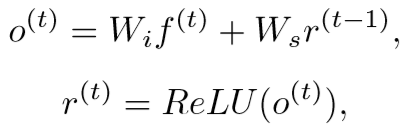
时间池化层:
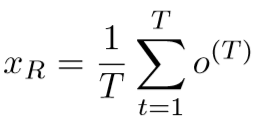
(6)时空特征融合:
由于RNN对前期帧较为忽视,需要对丢失的信息进行弥补,将CNN、RNN两次的输出进行结合,计算如下:![]()
(7)多损失层:
损失函数包含Siamese损失和Softmax损失:

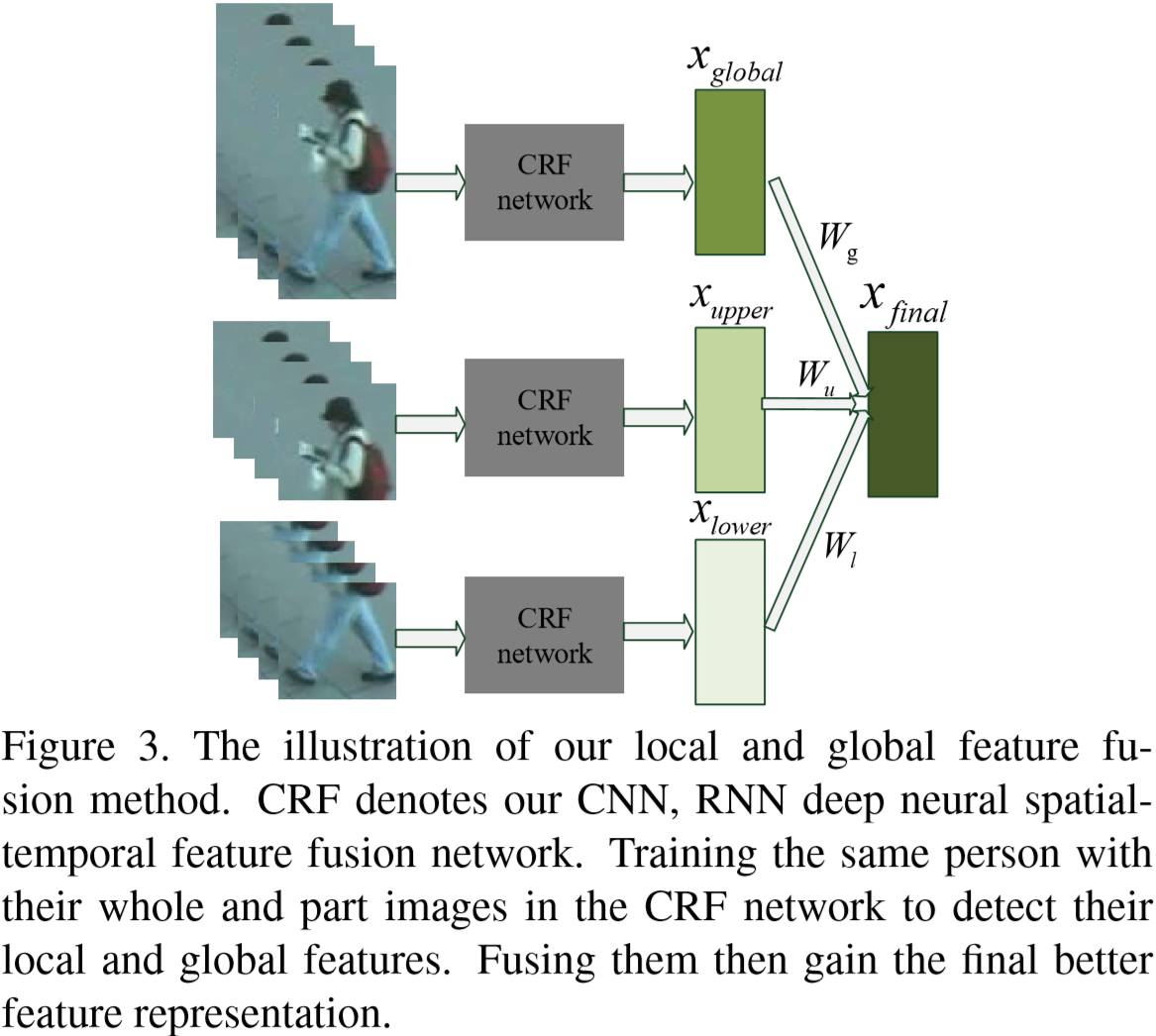
(8)局部/全局特征融合:
将行人身体分为上半部分和下半部分,分别提取特征,在进行整体融合:
![]()
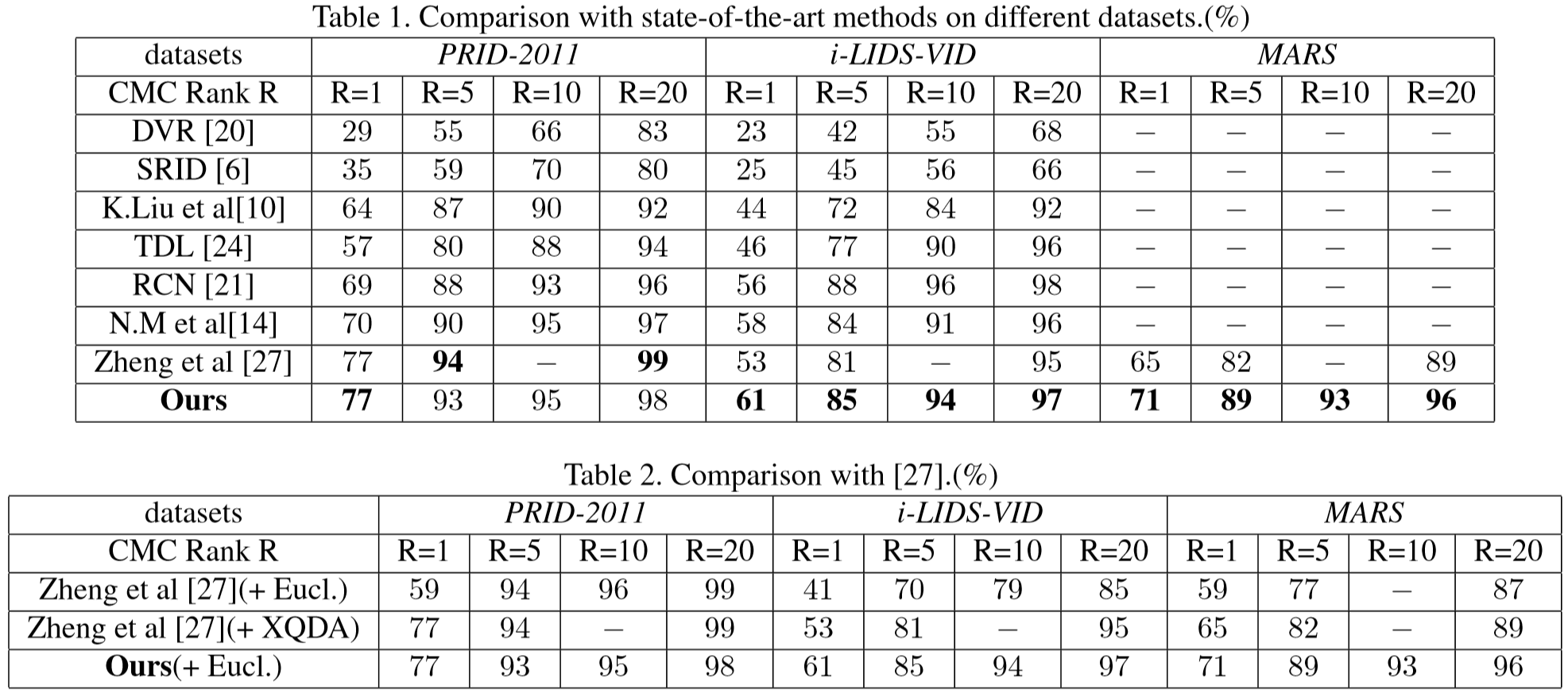
Experiments
(1)实验设置:
① 数据集设置:PRID-2011、iLIDS-VID、MARS;
② 参数设置:epochs > 10,视频序列长度 = 16,W1 = W2 = W3 = 1.
(2)实验结果: