论文地址:https://arxiv.org/pdf/2102.10662.pdf
Abstract.
由于卷积体系结构中存在的固有的归纳偏差,它们缺乏对图像中的随机依赖性的理解。最近提出的基于转换器的架构,利用自注意机制对远程依赖关系进行编码,取得了十分优异的结果。大多数基于transformer的网络架构需要大规模数据集进行正确训练。然而,与视觉应用的数据集相比,医学成像中的数据样本数量相对较少,这使得很难有效地训练用于医学成像应用的变压器。为此,我们提出了一种门控的轴向注意模型,它通过在自注意模块中引入一个额外的控制机制来扩展现有的体系结构。此外,为了在医学图像上有效地训练模型,我们提出了一种局部-全局训练策略(LoGo),进一步提高了模型的性能。具体来说,我们分别对整个图像和补丁进行操作,以学习全局特征和局部特征。在三种不同的医学图像分割数据集上对所提出的医学transformer(MedT)进行了评估,结果表明,该transformer比基于卷积和其他基于相关transformer的架构具有更好的性能。
1 Introduction
卷积神经网络是目前大多数图像分割方法的基本构件。然而,它们缺乏建模图像中存在的长期依赖关系的能力。更准确地说,在ConvNets中,每个卷积核只关注整个图像中像素的一个局部子集,并迫使网络关注局部模式,而不是全局上下文。已经有一些工作集中于使用图像金字塔[29]、空洞卷积[3]和注意机制[9]的长期依赖建模。然而,可以注意的是,由于以往的大多数方法都没有集中在医学图像分割任务的这方面,因此对远程依赖关系的建模仍有改进的空间。
为了首先理解为什么远程依赖对医学图像很重要,我们以一个早产儿的超声扫描为例,并从图1中可视化了脑室的分割预测。为了使网络提供有效的分割,它应该能够理解哪些像素对应于掩模,哪些像素对应于背景。由于图像的背景是分散的,学习与背景对应的像素之间的长期依赖关系有助于网络中防止将一个像素误分类为掩模,从而减少假阳性(以0为背景,1为分割掩模)。同样,当分割掩模很大时,学习与掩模对应的像素之间的长期依赖关系也有助于做出有效的预测。在图1 (b)和图(c)中,我们可以看到卷积网络错误地将背景分类为脑室,而所提出的基于transformer的方法没有犯这种错误。这是在我们提出的方法学习像素区域与背景的长期依赖关系时发生的。

基于transformer的模型只有在大规模数据集[6]上进行训练时才能工作良好。这在医学成像任务中采用转换器时成为一个问题,因为在任何医学数据集中可用于训练的带有相应标签的图像数量相对稀缺。贴标签的过程也很昂贵,而且需要专家的知识。具体来说,用更少的图像进行训练会导致学习图像的位置编码的困难。为此,我们提出了一种门控的位置敏感的轴向注意机制,其中我们引入了四个门,它们控制位置嵌入提供给键、查询和值的位置编码的信息量。这些门是可学习的参数,它使所提出的机制可以应用于任何大小的数据集。根据数据集的大小,这些门将了解图像的数量是否足以学习适当的位置嵌入。根据通过位置嵌入学习到的信息是否有用,门参数要么收敛到0,要么收敛到一些更高的值。此外,我们提出了一种局部-全局(LoGo)训练策略,其中我们使用一个浅层全局分支和一个深层局部分支来操作医学图像的补丁。这种策略提高了分割性能,因为我们不仅操作整个图像,而且关注局部补丁中更精细的细节。最后,我们提出了医学transformer(MedT),它使用了我们的门控位置敏感的轴向注意作为构建模块,并采用了我们的LoGo训练策略。
综上所述,本文(1)提出了一个门控位置敏感轴向注意机制,甚至在较小的数据集,(2)介绍全球(LoGo)训练方法变压器是有效的,(3)提出医疗变压器(MedT)建立在上述两个概念专门为医学图像分割,和(4)成功地提高了医学图像分割任务在卷积网络和完全注意架构在三个不同的数据集。
2 Medical Transformer (MedT)
2.1 Self-Attention Overview
就是transformer的经典公式,虽然不同的论文有不同的写法

Axial-Attention 这个模块参加我的上篇博客:
论文精读:Axial-DeepLab: Stand-Alone Axial-Attention forPanoptic Segmentation_樱花的浪漫的博客-CSDN博客
核心思想就是对q,k,v均加上位置编码

2.2 Gated Axial-Attention
对于门控单元,我觉得更多是一种放缩,放缩位置编码的影响。源码中门控单元的值都设置得特别小。
上面的轴向注意能够以良好的计算效率计算非局部上下文,能够将位置偏差编码到机制中,并能够在输入特征图中编码长期交互。 然而,他们的模型是在大规模的分割数据集上进行评估的,因此轴向注意更容易学习在关键、查询和值上的位置偏差。作者认为,对于小规模数据集的实验,这是医学图像分割的常见情况,位置偏差很难学习,因此在编码远程交互时并不总是准确的。在学习到的相对位置编码不够准确的情况下,将它们添加到各自的键、查询和值张量中,会导致性能降低。因此,作者提出了一种改进的轴向注意块,它可以控制位置偏差在非局部上下文编码中所产生的影响。通过所提出的修改,应用于宽度轴上的自注意机制可以正式地写为:

论文增加了门控机制。此外,门控机制GQ、GK、GV 1、GV 2∈R是可学习的参数,控制学习到的相对位置编码对编码非局部上下文的影响。通常,如果一个相对位置编码被准确地学习,门控机制将为其分配给那些没有准确学习的高权重。图2 (c)显示了一个典型的门控轴向注意层的前馈图。

2.3 Local-Global Training
很明显,基于patch的transformer速度更快,但仅凭补丁训练并不足以完成像医学图像分割这样的任务。补丁式训练限制了网络学习补丁间像素的任何信息或依赖关系。为了提高对图像的整体理解,我们建议在网络中使用两个分支,即一个处理图像原始分辨率的全局分支,和一个处理图像补丁的局部分支。在全局分支中,我们减少了门控轴向transformer层的数量,因为我们观察到,所提出的变压器模型的前几个块足以建模长期依赖关系。 在local分支中,我们创建了16个大小为I/4×I/4的补丁,其中I是原始图像的尺寸。在local分支中,每个补丁通过网络进行馈送,并根据其位置对输出特征图进行重新采样,得到输出特征图。然后添加这两个分支的输出特征图,并通过1×1的卷积层生成输出分割掩码。该策略提高了性能,因为全局分支可以关注更精细的细节,而本地分支可以关注高级信息。所提出的MedT使用门控轴向注意层作为基本构件,并使用LoGo策略进行训练。如图2 (a).所示关于该架构的更多细节和关于该架构的消融研究可以在补充文件中找到。


3 Experiments and Results
3.1 Dataset details
Brain anatomy segmentation (ultrasound) Gland segmentation (microscopic) MoNuSeg (microscopic)
3.2 Implementation details
使用BCE损失:

提出的模型:
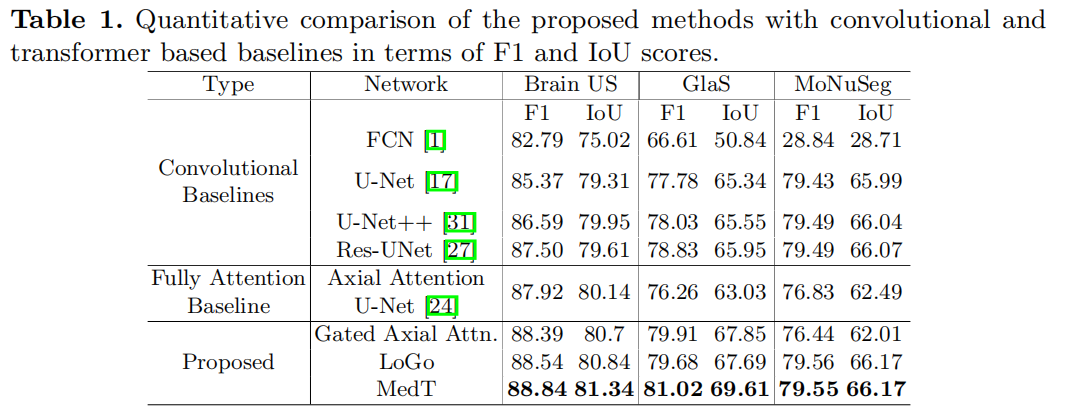
在门控轴向注意网络中,我们使用axial attention U-Net,其所有的轴向注意层都被所提出的门控轴向注意层所取代。在LoGo中,我们不使用门控轴向注意层,对axial attention U-Net进行局部全局训练。在MedT中,我们使用门控轴向注意作为全局分支的基本构件,局部分支使用轴向注意而不对进行位置编码。
此外,作者将图3中的U-Net [17]、Res-UNet [27]、axial attention U-Net [24]和作者提出的方法MedT方法的预测可视化。可以看出,MedT的预测确实很好地捕捉到了长期的依赖关系。例如,在图3的第二行中,我们可以观察到在红色框上突出显示的小分割掩码在所有的卷积基线中都没有被检测到。然而,由于完全注意模型编码了长期依赖关系,由于编码的全局上下文,它学会了很好地分割。在第一行和第四行,其他方法在高亮的区域做出错误的预测,因为这些像素接近分割掩模。由于我们的方法考虑了用门控机制编码的像素级依赖关系,因此它能够比轴向注意U-Net更好地学习这些依赖关系。这使得我们的预测更加精确,因为它们不会错过分类分割掩模附近的像素。
