目录
论文:https://arxiv.org/abs/1907.05740
代码:GitHub - nv-tlabs/GSCNN: Gated-Shape CNN for Semantic Segmentation (ICCV 2019)
自己看文章的记录,难免有错误之处,望大家指点。
简单不看版:
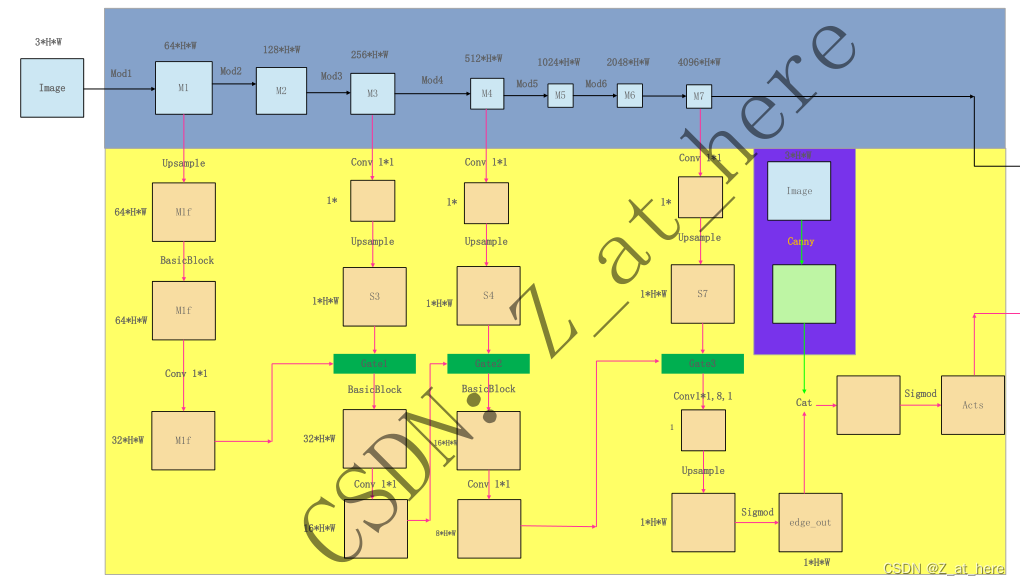
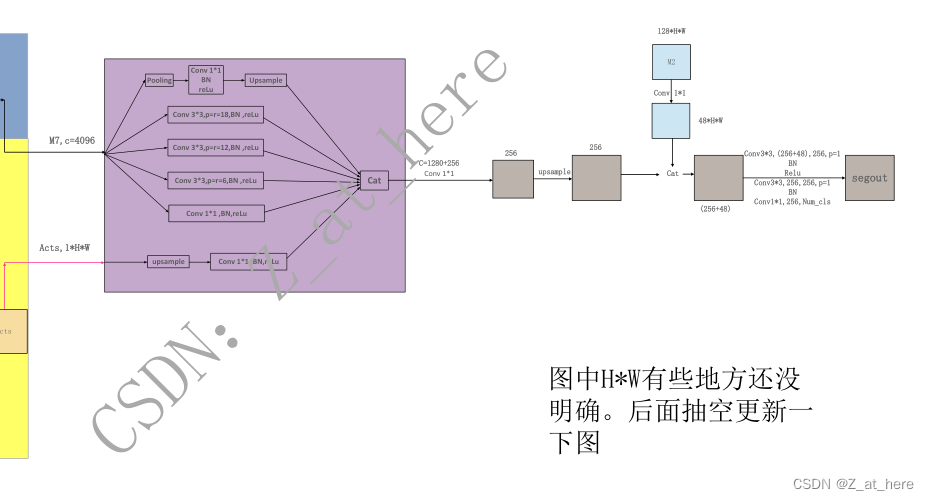
作者提出之前的模型都是将纹理、颜色、形状等信息送到同一个CNN中进行处理,但这样不太理想,因为这个过程中包含了很多和识别相关的不同的信息。所以作者就提出了该双分支的模型,称之为shape stream,与classical stream。Classical stream是常规的CNN。作者在文章中采用了resnet50,resnet101,和widerenset38作为backbone。widerenset38效果最好,代码中也是widerenset38。作者提出该shape stream分支可以即插即用在任何一个CNN模型中,只要将channel和HW统一即可。Shape stream中输入为CNN中不同阶段的feature map和将图像做canny操作之后的二值化边缘图像,处理过程主要采用gate结构(代码附后)和残差结构,如下图所示,最终输出记作acts(1*H*W)。代码中的Classical stream产生了7个feature map,分别记作m1-m7,m7应该是(4096* H/8 *W/8)。在fusion module中,将m7和acts传递到ASPP中,分两路做处理,最后做cat操作输出。作者在代码中还将CNN中的浅层feature map(m2)与fusion module输出的做了融合,最后输出分类图像。作者用二分类交叉熵损失函数来监督shape stream.
有关Dual Task Regularizer和损失函数的说明,没太看懂,代码也还没来得及仔细看,代码正在跑。过程中遇到了很难受的问题----->跑起来特别慢,一个epoch就要35分钟,GPU显存很高,利用率超级低,我猜想可能和加载进来的数据分辨率有关,这一问题我还不能很好的验证,求大佬指点。
更新关于结构图中的分辨率和通道大小问题:使用CNN是wideresnet,分辨率从m1-m7分别是720,360,180,90,90,90,90。通道分别是64,128,256,512,1024,2048,4096.图片中我就不做更改了。shape stream中的分辨率和通道我没有详细去看。
图中的H和W两个信息没有做详细的查看,仅供参考,确定的是shape输出大小为(1*720*720),cnn stream中输出是(4096*90*90)。
勘误:代码中ASPP模块中是先将两个stream中的特征进行了融合,然后再将融合后的特征传递进了ASPP模块中,所以我画的这个网络结构中的ASPP模块是错误的。
这个代码我详细读了,并做了大量的修改,对代码理解有问题可以评论区提问。

摘要
当前先进的语义分割CNN都是从稠密的图像表示获取的,其中颜色,纹理,形状都是在一个深度CNN中一起处理的。这样的处理方式不太理想,因为这个过程中包含了很多和识别相关的不同的信息。在此,我们提出一个双分支结构的语义分割模型,一个分支专门用来处理形状信息,称之为shape stream,与classical stream并行处理信息。这种架构的关键是一种新型的Gate,它连接两个流的中间层。具体地说,我们利用classical stream中的高级激活(higher-level activations)对形状流中的低级激活(lower-level activations)进行门控,有效地消除了噪声,帮助形状流只专注于处理相关的边界相关信息。这使我们能够在图像级分辨率上使用非常浅的形状流架构。我们的实验表明,这导致了一个高效的架构,产生更清晰的对象边界预测,并显著提高性能的薄和较小的对象。我们的方法在Cityscapes benchmark上取得了最先进的性能,在mIoU和边界评价指标(f-score)方面,比baselines提高了2%和4%。
一、介绍
语义图像分割是计算机视觉中研究最广泛的问题之一,在自动驾驶中的应用[42,17,57],三维重建[38,30]和图像生成[22,47]等。近年来,卷积神经网络(cnn)在几乎所有主要分割基准的准确性方面都取得了显著的进步。一种标准的做法是通过将全连通层转换为卷积层[37],使图像分类CNN结构适应语义分割的任务。然而,使用分类体系结构进行密集像素预测存在一些缺陷[DPV3+、FCN、PSPnet]。一个突出的缺点是由于使用pooling的输出空间分辨率的损失。这促使多篇文章[Multi-scale context aggregation by dilated convolutions. ICLR, 2016;Pyramid scene parsing network. In CVPR, 2017.;Learning affinity via spatial propagation networks.In NIPS, pages 1520–1530, 2017;Densely connected convolutional networks. In CVPR, pages4700–4708, 2017;]提出了专门的CNN模块,帮助恢复网络输出的空间分辨率。
我们认为也要很多无用之处在这些结构中,因为颜色、形状、纹理等信息也同时在一个深度CNN中处理。请注意,这些可能包含非常多类的大量的与识别相关的信息,Note that these likely contain very different amounts of information that are relevant for recognition. For example, one may need to look at the complete and detailed object boundary to get a discriminative encoding of shape [2, 33],while color and texture contain fairly low-level information. 这也可以帮助我们了解为什么剩余的[19]、skip[19,52]甚至密集的连接[21]会导致最显著的性能提升。结合附加的连接性有助于不同类型的信息在网络深度的不同尺度上流动。然而,通过设计去除这些表示可能会导致更自然和有效的识别流程。
在这项工作中,我们提出了一种新的双流CNN结构的语义分割,将形状信息单独作为一个stream处理。特别地,我们将经典的CNN保持在另一个流中,并添加一个shape stream,以平行的方式处理信息。两个stream中的信息在最高层之前不会融合。
该结构的关键是允许两个分支进行交互的新型Gate。特别的,我们利用classical stream中的得到的高级语义信息去噪之后,作为shape stream的输入。通过这样做,shape stream只集中处理相关形状信息。这样子就可以使得形状流采用一个非常有效的较浅的架构,操作全图像分辨率。我们定义一个语义边界损失函数来实现将形状信息定向流动到所需的stream。我们还开发了一个新的损失函数用来鼓励预测的分割结果与ground truth对齐,这进一步鼓励fusion layer利用来自于shape stream的信息。我们称该模型为GSCNN。
我们对Cityscapes benchmark进行了广泛的评估。并且GSCNN可以即插即用的使用在任何一个CNN的backbone中。在我们的实验中,我们探索了ResNet-50 [19], ResNet-101[19]和WideResnet[56],并显示了所有的显著改进。我们提出的模型的表现比当前先进的deeplabv3+在miou方面高出了1.5%,在F-boundary score高出了4%。对于更薄、更小的物体(如电线杆、交通灯、交通标志),我们的收益尤其显著,在miou上提高了7%。
我们进一步评估在不同距离下的性能,使用先验作为距离的代理。实验表明,我们始终优于最先进的水平,在最大距离(即更远的物体)达到6%的改善在miou方面。
二、相关工作
Semantic Segmentation
一些工作(如Bottom-up instance segmentation using deep higher-order crfs. In arXiv:1609.02583, 2016.;Fast, exact and multi-scale inference for semantic image segmentation with deep gaussian crfs. In ECCV, pages 402–418. Springer, 2016;DeeplabV2: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. T-PAMI, 40(4):834–848, April 2018;等)建议使用结构化预测模型,如CRF条件随机场来提高语义分割的表现,尤其是边缘信息。为了避免太接近DenseCRF,这个文章[6](Semantic image segmentation with task-specific edge detection using cnns and a discriminatively trained do-main transform. In CVPR, pages 4545–4554, 2016.)使用fast do-main transformer对网络输出进行滤波,同时从中间CNN层预测边缘映射。与[6]使用边缘信息来细化网络输出不同,我们将学习到的边界信息注入到CNN的中间层。此外,我们提出了专门的网络结构和双任务规整器,以获得高质量的边界。
此外,我们提出了专门的网络结构和双任务规整器,以获得高质量的边界。例如,PSPNet[58]和DeepLab[9,11]提出了一种特征金字塔池化模块,该模块通过聚合多尺度上的特征来整合多尺度上下文。与我们类似,[42](特性Full-resolution residual networks for semantic segmentation instreet scenes. CVPR, 2017)提出了一个双流网络,然而,在他们的情况下,第二个流的主要目的是恢复在池层中丢失的高分辨率。一些著作[15,35,48]提出了使用学习到的像素亲和度跨中间CNN表示进行结构化信息传播的模块。我们建议通过精心设计的网络和损失函数来学习高质量的形状信息,而不是学习专业的信息传播模块。与语义和边界信息只在损失函数上相互作用这些工作不同的是,我们明确地将边界信息注入分割CNN,并提出了一个双重任务的损失函数来细化语义掩模和边界预测
Gated Convolutions
最近在语言建模方面的工作也提出了在卷积中使用门控机制的想法。在我们的例子中,我们使用一个门控卷积算子来完成语义分割的任务,并定义形状流和常规流之间的信息流。
三、Gated Shape CNN
在本节中,我们将介绍我们提出的语义分割架构。如图2所示,我们的网络由两个网络流和一个融合模块组成。一个是标准的语义分割CNN,另一个是以语义边界的形式处理边界信息的shape stream。我们通过精心设计的门控卷积层(GCL)和局部监督来强制形状流只处理与边界相关的信息。然后,我们在fusion模块中融合regular stream的语义特征和shape stream的边界特征,产生一个精细的分割结果,尤其是边界附近。接下来,我们将详细描述框架中的每个模块,然后是我们新颖的GCL(Gated Convolution Layer)。
Regular Stream
输入H*W*3的image产生稠密的像素特征。Regular stream可以是任意前馈全连接卷积网络,比如基于VGG,resnet的语义分割网络。由于ResNets是最新的语义分割技术,我们使用类似resnet的架构,如ResNet-101[19]和WideResNet[56]用于regular stream。我们用H/m * W/m * C表示输出的特征,其中m是regular stream的步距长度。
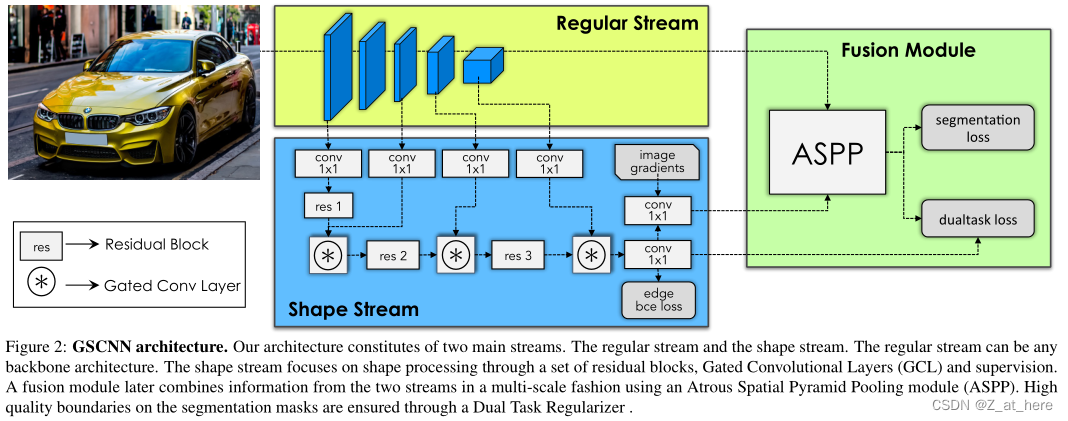 Shape Stream
Shape Stream
以图像梯度∇I和regular stream第一个卷积层的输出作为输入,输出产生语义边界。该网络结构由若干残差块与门控卷积层(GCL)交织而成。GCL确保形状流只处理边界相关的信息。
我们将shape stream的输出表示为H*W。因为我们可以从GT semantic segmentation masks中获得ground truth的二值化边缘,所以我们在输出边界上使用有监督的二分类交叉熵损失函数来监督shape stream。
Fusion Module
将regular stream的feature map作为输入,与shape stream输出的boundary map进行融合,以保持多尺度上下文信息。它结合了区域特征和边界特征,并输出一个精细的语义分割输出。更正式地说,对于K个语义类别的分割预测,它输出一个分类分布,表示像素属于K个类别中每一个的概率。具体来说,我们使用ASPP合并boundary map和feature map。这使得我们能够保存多尺度的上下文信息,并被证明是最先进的语义分割网络的一个重要组成部分。
3.1. Gated Convolutional Layer
由于语义分割和语义边界的任务是密切相关的。我们设计了一个新的促进信息从regular stream流向shape stream的GCL层。GCL是我们架构的核心组件,它帮助shape stream只处理相关信息,而过滤掉其他信息。注意,形状流不包含来自常规流的特征。注意,形状流不包含来自常规流的特征。相反,它使用GCL去停用它自己的那些被包含在常规流中的高级信息里面认为不相关的激活。我们可以把这看作是两个流之间的协作,其中功能更强大的一个shape stream,已经形成了对场景的更高层次的语义理解,帮助另一个shape stream从一开始就只关注相关的部分。这使得形状流能够采用有效的浅层架构,以非常高的分辨率处理图像。
########################################################
########################################################
3.2. Joint Multi-Task Learning
我们通过融合模块以端到端方式共同学习规则流和形状流。在训练过程中,我们共同监督分割和边界地图预测。这里,边界地图是场景中所有对象和类的轮廓的二分类表示,如图六所示。我们使用标准的二分类交叉熵损失函数(BCE)来预测边界maps,用标准的交叉熵损失函数来预测语义分割 f。
![]()
其中s hat是GT boundaries,y hat是GT的语义标签。兰姆达1和兰姆达2是两个控制损失函数权重的超参数。如图二所示,在将boundary maps输入fusion模块之前,对边界图进行BCE监督。因此BCE损失函数更新regular stream和shape stream两个stream的参数。语义类别的最终分类分布f与标准语义分割网络中的CE损失函数一样,在最后进行监督,更新所有的网络参数。在边界上的BCE的情况下,我们遵循[50,54]这两篇文章(Holistically-nested edge detection. In ICCV, pages 1395–1403, 2015;CASENet:
Deep category-aware semantic edge detection. In CVPR,2017),并使用β系数来解释边界/非边界像素之间的类别不均衡问题。
3.3. Dual Task Regularizer
3.3.1 Gradient Propagation during Training
代码
GSCNN模块代码
class GSCNN(nn.Module):
'''
Wide_resnet version of DeepLabV3
mod1
pool2
mod2 str2
pool3
mod3-7
structure: [3, 3, 6, 3, 1, 1]
channels = [(128, 128), (256, 256), (512, 512), (512, 1024), (512, 1024, 2048),
(1024, 2048, 4096)]
'''
def __init__(self, num_classes, trunk=None, criterion=None):
super(GSCNN, self).__init__()
self.criterion = criterion
self.num_classes = num_classes
wide_resnet = wider_resnet38_a2(classes=1000, dilation=True)
wide_resnet = torch.nn.DataParallel(wide_resnet)
wide_resnet = wide_resnet.module
self.mod1 = wide_resnet.mod1
self.mod2 = wide_resnet.mod2
self.mod3 = wide_resnet.mod3
self.mod4 = wide_resnet.mod4
self.mod5 = wide_resnet.mod5
self.mod6 = wide_resnet.mod6
self.mod7 = wide_resnet.mod7
self.pool2 = wide_resnet.pool2
self.pool3 = wide_resnet.pool3
self.interpolate = F.interpolate
del wide_resnet
self.dsn1 = nn.Conv2d(64, 1, 1)
self.dsn3 = nn.Conv2d(256, 1, 1)
self.dsn4 = nn.Conv2d(512, 1, 1)
self.dsn7 = nn.Conv2d(4096, 1, 1)
self.res1 = Resnet.BasicBlock(64, 64, stride=1, downsample=None)
self.d1 = nn.Conv2d(64, 32, 1)
self.res2 = Resnet.BasicBlock(32, 32, stride=1, downsample=None)
self.d2 = nn.Conv2d(32, 16, 1)
self.res3 = Resnet.BasicBlock(16, 16, stride=1, downsample=None)
self.d3 = nn.Conv2d(16, 8, 1)
self.fuse = nn.Conv2d(8, 1, kernel_size=1, padding=0, bias=False)
self.cw = nn.Conv2d(2, 1, kernel_size=1, padding=0, bias=False)
#gate结构
self.gate1 = gsc.GatedSpatialConv2d(32, 32)
self.gate2 = gsc.GatedSpatialConv2d(16, 16)
self.gate3 = gsc.GatedSpatialConv2d(8, 8)
self.aspp = _AtrousSpatialPyramidPoolingModule(4096, 256,output_stride=8)
self.bot_fine = nn.Conv2d(128, 48, kernel_size=1, bias=False)
self.bot_aspp = nn.Conv2d(1280 + 256, 256, kernel_size=1, bias=False)
self.final_seg = nn.Sequential(
nn.Conv2d(256 + 48, 256, kernel_size=3, padding=1, bias=False),
Norm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1, bias=False),
Norm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, num_classes, kernel_size=1, bias=False))
self.sigmoid = nn.Sigmoid()
initialize_weights(self.final_seg)
def forward(self, inp, gts=None):
x_size = inp.size()
# res 1
m1 = self.mod1(inp)
# res 2
m2 = self.mod2(self.pool2(m1))
# res 3
m3 = self.mod3(self.pool3(m2))
# res 4-7
m4 = self.mod4(m3)
m5 = self.mod5(m4)
m6 = self.mod6(m5)
m7 = self.mod7(m6)
s3 = F.interpolate(self.dsn3(m3), x_size[2:],mode='bilinear', align_corners=True)
s4 = F.interpolate(self.dsn4(m4), x_size[2:],mode='bilinear', align_corners=True)
s7 = F.interpolate(self.dsn7(m7), x_size[2:],mode='bilinear', align_corners=True)
m1f = F.interpolate(m1, x_size[2:], mode='bilinear', align_corners=True)
#canny提取图像边缘
im_arr = inp.cpu().numpy().transpose((0,2,3,1)).astype(np.uint8)
canny = np.zeros((x_size[0], 1, x_size[2], x_size[3]))
for i in range(x_size[0]):
canny[i] = cv2.Canny(im_arr[i],10,100)
canny = torch.from_numpy(canny).cuda().float()
cs = self.res1(m1f)
cs = F.interpolate(cs, x_size[2:],
mode='bilinear', align_corners=True)#残差结构中没有执行下采样操作,所以这一步不执行,图片大小没发生变化
cs = self.d1(cs)
cs = self.gate1(cs, s3)
cs = self.res2(cs)
cs = F.interpolate(cs, x_size[2:],
mode='bilinear', align_corners=True)
cs = self.d2(cs)
cs = self.gate2(cs, s4)
cs = self.res3(cs)
cs = F.interpolate(cs, x_size[2:],
mode='bilinear', align_corners=True)
cs = self.d3(cs)
cs = self.gate3(cs, s7)
cs = self.fuse(cs)
cs = F.interpolate(cs, x_size[2:],
mode='bilinear', align_corners=True)
edge_out = self.sigmoid(cs)
cat = torch.cat((edge_out, canny), dim=1)
acts = self.cw(cat)
acts = self.sigmoid(acts)#shape stream的最终输出
# aspp
x = self.aspp(m7, acts)
dec0_up = self.bot_aspp(x)
dec0_fine = self.bot_fine(m2)
dec0_up = self.interpolate(dec0_up, m2.size()[2:], mode='bilinear',align_corners=True)
dec0 = [dec0_fine, dec0_up]
dec0 = torch.cat(dec0, 1)
dec1 = self.final_seg(dec0)
seg_out = self.interpolate(dec1, x_size[2:], mode='bilinear')
if self.training:
return self.criterion((seg_out, edge_out), gts)
else:
return seg_out, edge_outGate模块代码
class GatedSpatialConv2d(_ConvNd):
def __init__(self, in_channels, out_channels, kernel_size=1, stride=1,
padding=0, dilation=1, groups=1, bias=False):
"""
:param in_channels:
:param out_channels:
:param kernel_size:
:param stride:
:param padding:
:param dilation:
:param groups:
:param bias:
"""
kernel_size = _pair(kernel_size)
stride = _pair(stride)
padding = _pair(padding)
dilation = _pair(dilation)
super(GatedSpatialConv2d, self).__init__(
in_channels, out_channels, kernel_size, stride, padding, dilation,
False, _pair(0), groups, bias, 'zeros')
self._gate_conv = nn.Sequential(
mynn.Norm2d(in_channels+1),
nn.Conv2d(in_channels+1, in_channels+1, 1),
nn.ReLU(),
nn.Conv2d(in_channels+1, 1, 1),
mynn.Norm2d(1),
nn.Sigmoid()
)
def forward(self, input_features, gating_features):
"""
:param input_features: [NxCxHxW] featuers comming from the shape branch (canny branch).
:param gating_features: [Nx1xHxW] features comming from the texture branch (resnet). Only one channel feature map.
:return:
"""
alphas = self._gate_conv(torch.cat([input_features, gating_features], dim=1))
input_features = (input_features * (alphas + 1))
return F.conv2d(input_features, self.weight, self.bias, self.stride,
self.padding, self.dilation, self.groups)
def reset_parameters(self):
nn.init.xavier_normal_(self.weight)
if self.bias is not None:
nn.init.zeros_(self.bias)
四、实验
在本节中,我们将对我们的挑战框架的每个组成部分进行广泛的评估Cityscapes。我们进一步展示了我们的方法对几个骨干架构的有效性,并提供了我们的方法的定性结果。
Baseline
使用DPv3+作为baseline,改变了不同的backbone作为DPv3+的特征提取器。
Dataset
Cityscapes dataset,该数据集中有粗糙数据集和精细数据集,我们使用精细数据集。我们根据这三篇文章(Devil is in the edges: Learning semantic boundaries from noisy annotations. In CVPR,2019;CASENet:Deep category-aware semantic edge detection. In CVPR,2017;Simultaneous edge alignment and learning. In ECCV, 2018)来生成ground truth边界并监督我们的shape stream。
Evaluation Metrics.
Miou
F-score:因为我们还需要评价边界相关的信息,主要是根据这篇文章(A benchmark dataset
and evaluation methodology for video object segmentation. In CVPR, pages 724–732, 2016)中提出的。
Distance-based Evaluation:
Distance-based Evaluation
4.1. Quantitative Evaluation

我们将GSCNN的性能与基线在区域精度方面(由mIoU衡量)进行比较。这些数字在验证集上报告,并在完整图像上计算(不裁剪)。在这个集合中,我们实现了2%的改进。特别地,我们注意到我们在小物件上取得了显著的改进:摩托车、交通标志、交通灯和电线杆。

另一方面,将我们的方法的性能与边界精度(由F-score衡量)的基线进行比较。类似地,我们的模型表现得相当好,比基线表现得更接近在最严格的制度下只有4%。请注意,为了公平比较,我们只报告在Cityscapes精细集上训练的模型。所有模型的推理都是在单一尺度上完成的。

我们展示了我们的方法与基线的性能,以下是提出的基于距离的评估方法。在这里,我们发现,随着作物因子的增加,GSCNN的性能越来越好于deeplabv3 +。GSCNN和DeeplabV3+之间的表现差距从作物因子0时的2%(即不种植)增加到作物因子400时的接近6%。这证实了我们的网络在距离摄像机较远的较小物体上取得了显著的改进。
4.2. Ablation
在表3中,我们使用不同的编码器网络对常规流评估了我们的方法的每个组件的有效性。
另一方面,表4展示了边界对齐中以f值表示的双重任务损失。我们在三个不同的阈值上说明了它的影响。
五.总结
在本文中,我们提出gate - scnn (GSCNN),这是一种新的双流CNN结构,用于语义分割,将形状连接成一个单独的并行流。我们使用一种新的门控机制来连接中间层,并使用一种新的损失函数来利用语义分割和语义边界预测任务之间的二重性。我们的实验表明,这是以高效的架构,能产生更清晰的对象边界预测,并显著提高性能的薄和较小的对象。我们的模型在具有挑战性的城市景观数据集上取得了最先进的结果,大大改善了baselines。