分析流程
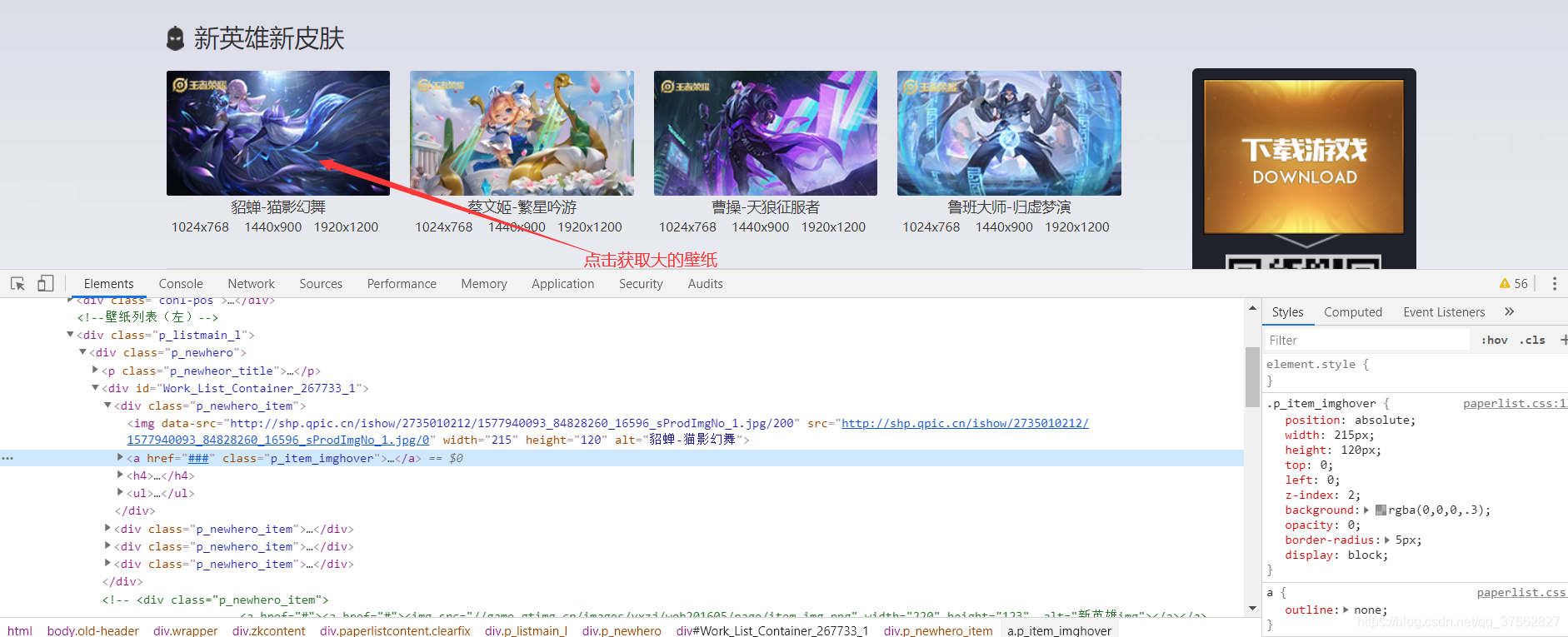
目标网站
 http://shp.qpic.cn/ishow/2735010212/1577940093_84828260_16596_sProdImgNo_2.jpg/0 1024768壁纸
http://shp.qpic.cn/ishow/2735010212/1577940093_84828260_16596_sProdImgNo_2.jpg/0 1024768壁纸
http://shp.qpic.cn/ishow/2735010212/1577940125_84828260_1263_sProdImgNo_3.jpg/0 1280720壁纸
http://shp.qpic.cn/ishow/2735010212/1577940125_84828260_1263_sProdImgNo_5.jpg/0 1440900壁纸
http://shp.qpic.cn/ishow/2735010212/1577940125_84828260_1263_sProdImgNo_6.jpg/0 19201080壁纸
http://shp.qpic.cn/ishow/2735010212/1577940125_84828260_1263_sProdImgNo_7.jpg/0 19201200壁纸
http://shp.qpic.cn/ishow/2735010212/1577940094_84828260_16596_sProdImgNo_8.jpg/0 19201440壁纸
图片链接变化地址在于sProdlmgNo_数字
分析该网站
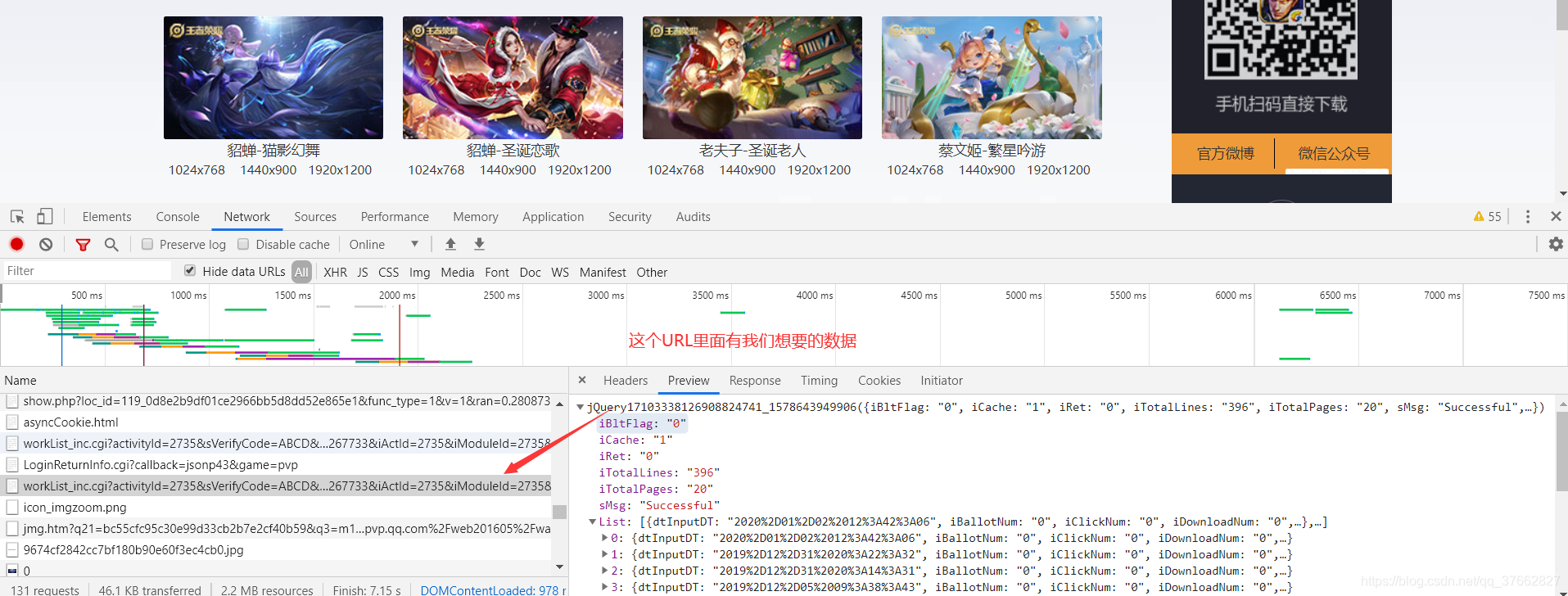
https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=0&iOrder=0&iSortNumClose=1&jsoncallback=jQuery17103338126908824741_1578643949906&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1578643950203
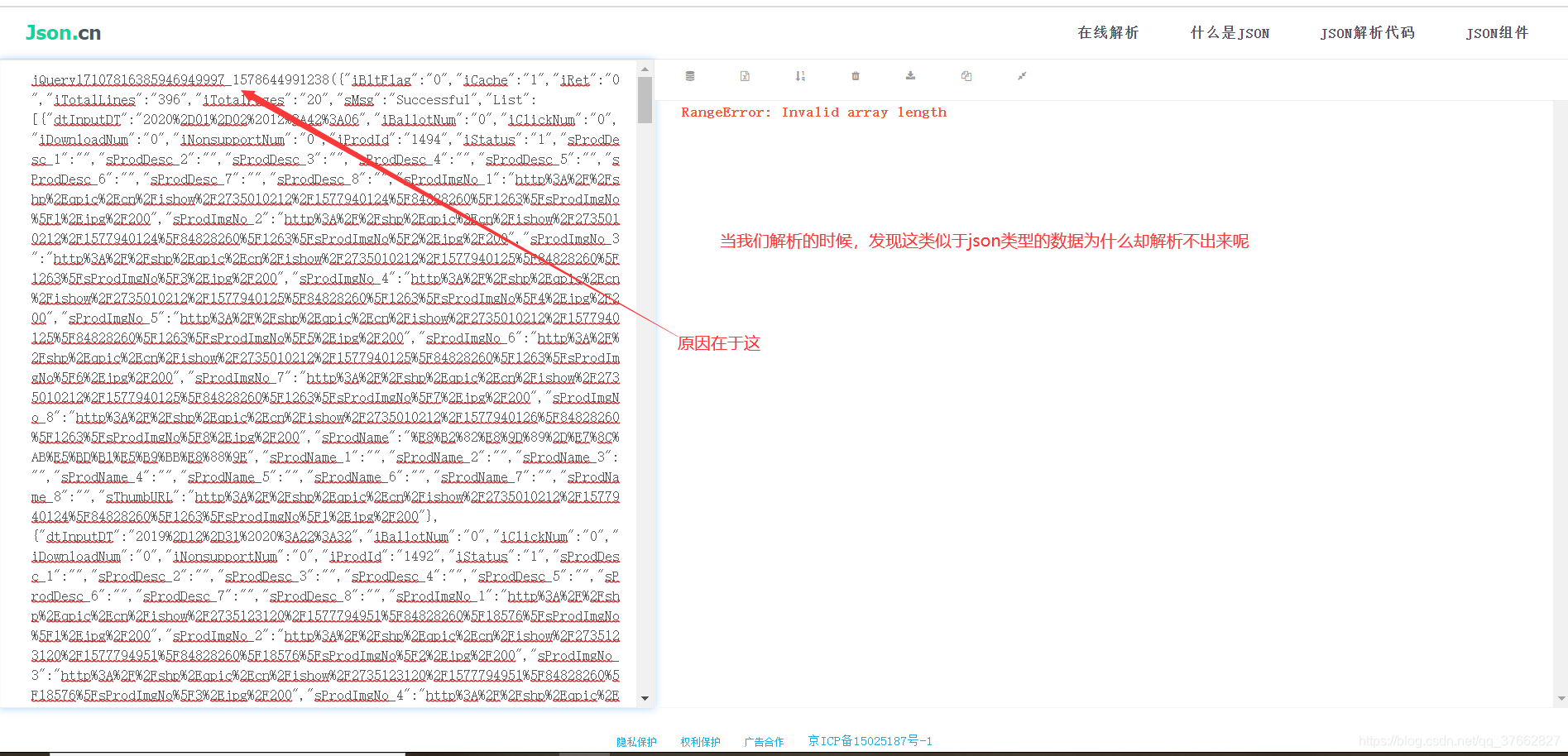
怎么解决呢?暴力解决
在URL中删除该值,前端是以&符来分割数据
删除后的目标网站为: https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=0&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1578643950203

requests.utlis.unquote():解码
requests.utils.quote():编码
# -*- coding: utf-8 -*-
# @Time : 2020/1/15 20:58
# @Author : 大数据小J
import requests
from urllib import request
import os
class wallpaper():
def __init__(self):
for i in range(20):
self.url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page={}&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1579093407070'.format(i)
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36',
'referer': 'https://pvp.qq.com/web201605/wallpaper.shtml'}
def get_url(self):
response = requests.get(self.url, headers=self.headers).json()
data = response['List']
return data
def get_data(self, data):
list_data = []
for index, jpg_url in enumerate(range(1, 9)):
jpg_url = data['sProdImgNo_{}'.format(jpg_url)]
jpg_url = requests.utils.unquote(jpg_url).replace('200', '0')
name = requests.utils.unquote(data['sProdName'])
list_data.append((index, jpg_url, name))
return list_data
def write_data(self, index, jpg_url, name):
path = 'demo'
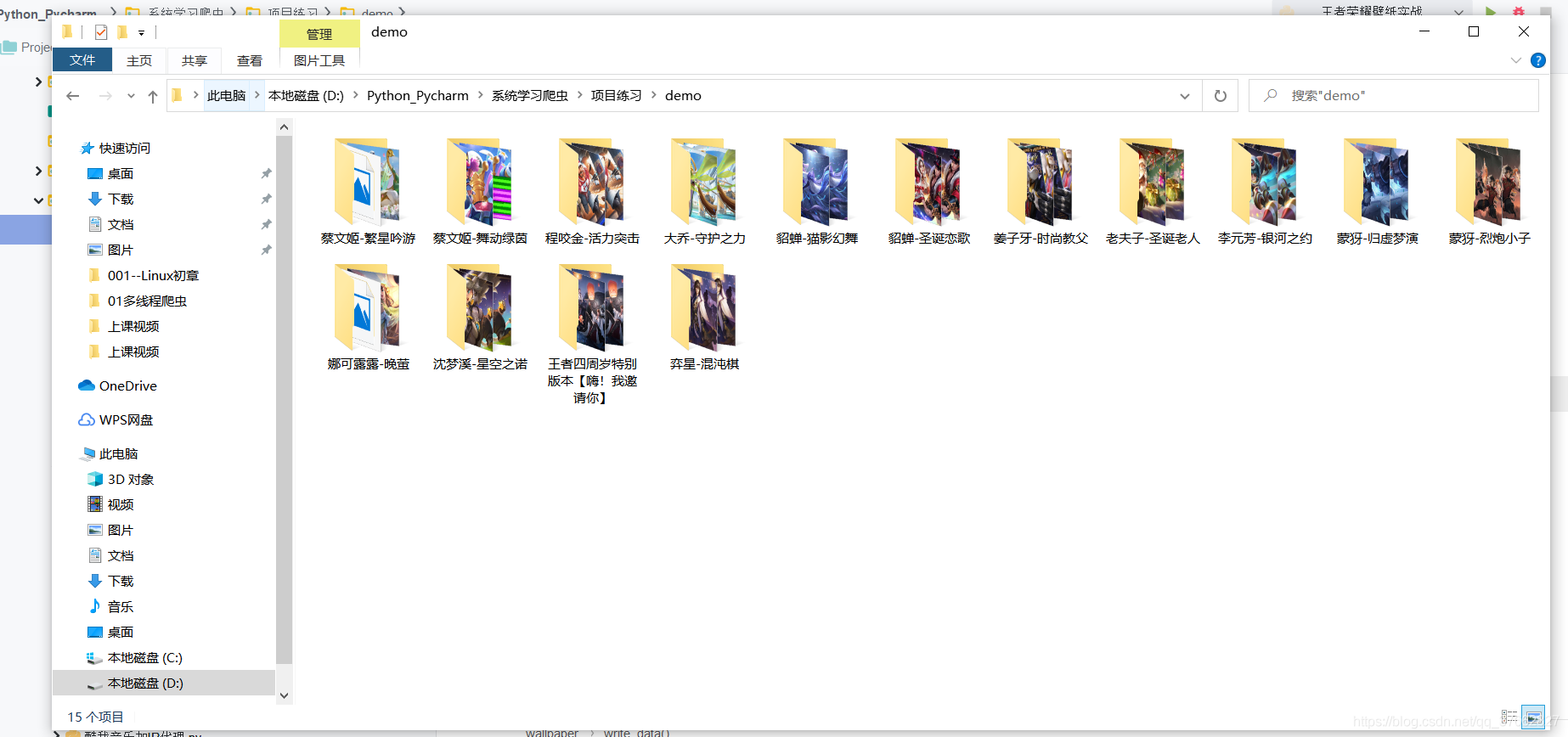
dir_path = path + '/' + name
if not os.path.exists(dir_path):
os.mkdir(dir_path)
request.urlretrieve(jpg_url, os.path.join(dir_path + '/' + '%d.jpg' % (index + 1)))
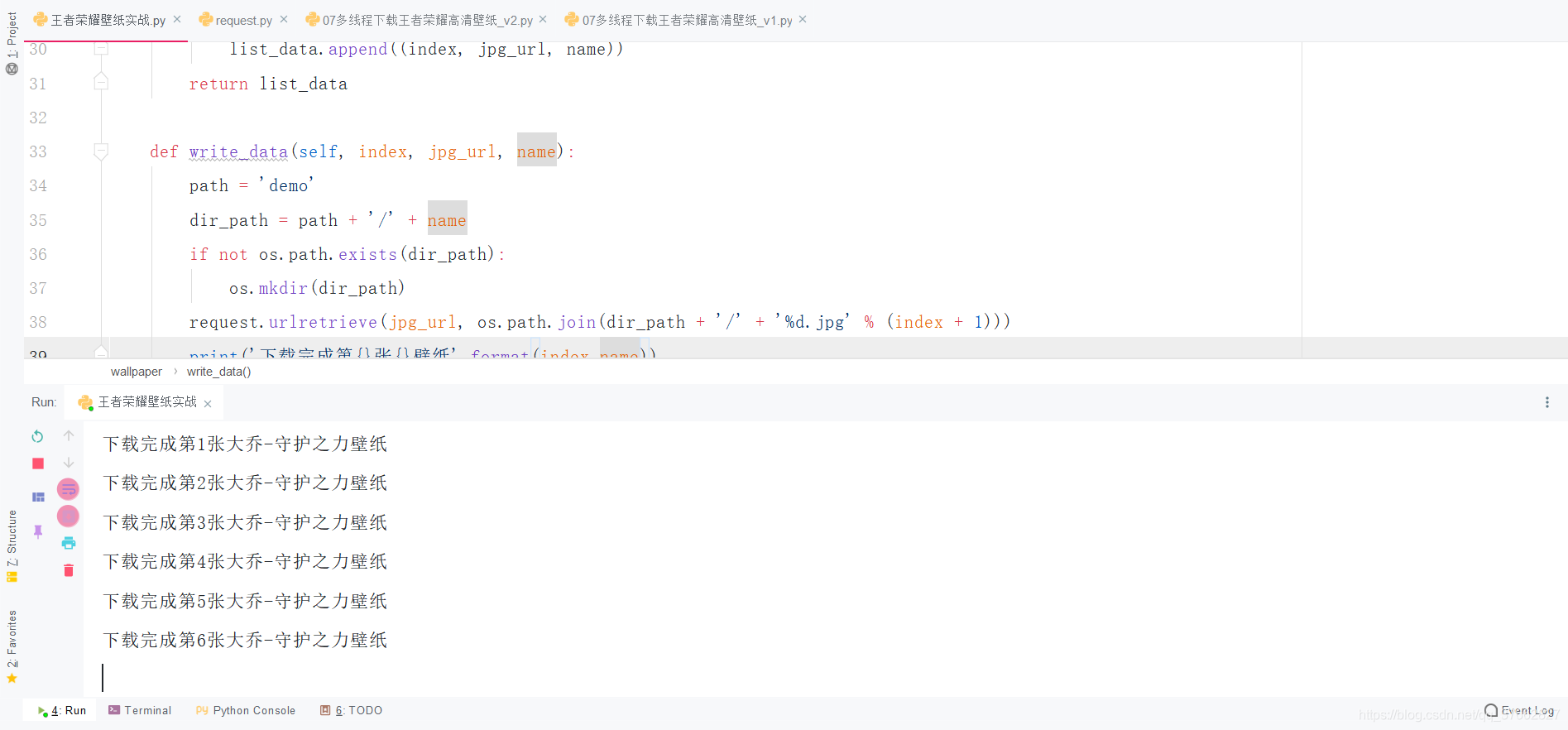
print('下载完成第{}张{}壁纸'.format(index,name))
# 主要的业务逻辑
def run(self):
for data in self.get_url():
for i in self.get_data(data):
index = i[0]
jpg_url = i[1]
name = i[2]
self.write_data(index, jpg_url, name)
if __name__ == '__main__':
data = wallpaper()
data.run()
运行结果: