IMMC2020:熵权TOPSIS
笔记整理来自清风老师的数学建模课程:TOPSIS教程
1. 层次分析法的局限性(主观求权重方法)
层次分析法真正的核心是判断矩阵的填写,但是判断矩阵受人为因素比较大,所以最后计算得出的权重也比较主观。如果在有数据的情况下最好不要使用层次分析法。
(1)评价的决策层不能太多,太多的话n会很大,判断矩阵和一致性差异可能会很大。(可能会通过不了一致性检验)

(2)如果决策层中指标的数据是已知的,那么我们如何利用这些数据来使得评价更加准确呢?
可以分析数据内在的特征就行评价。(熵权法、TOPSIS法)
2. TOPSIS法引入
2.1 一个指标的情况
小明同宿舍共有四名同学,他们第一学期的高数成绩如下表所示:

请你为这四名同学进行评分,该评分能合理的描述其高数成绩的高低。
(注:这里要求的评分可以类比于上一讲层次分析法中要求的那个权重)

修正后的排名表示数字越大越好,评分用排名的得分/总得分

可以随便修改成绩,只要保证排名不变,那么评分就不会改变!
【矛盾】评分没变说明结果有问题,说明这种评分方式不能够全部反应原始数据的全部信息。
想法1:把数都减去一个最小值。结果通过与(max-min)相处,将数字变为【0,1】之间的数。

将数归一化:

需要说明的问题:如果用下面这种方法,虽然结果更加精确,能够反应更多的原始信息;比如60分时,我们得到的结果是0.6,而不是0。但是需要知道理论的最大值和最小值。
但是大多数情况下,我们是无法知道理论的最大值与最小值的,只能得到1组数据中的最大值与最小值,所以常用的评分方法是上一种。

为什么不用上面表格这个理论最大值最小值的公式:

2.2 2个指标的情况
新增加了一个指标,现在要综合评价四位同学,并为他们进行评分。

成绩是越高(大)越好,这样的指标称为极大型指标(效益型指标)。
与他人争吵的次数越少(越小)越好,这样的指标称为极小型指标(成本型指标)。
在进行分析的时候我们需要将指标统一为一个类型,一般都转为极大型指标。
2.2.1 指标正向化
将所有的指标转化为极大型称为指标正向化(最常用)

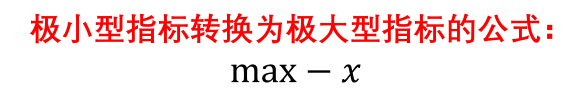
可以在excel中进行计算。比如折扣需要正向化处理。
2.2.2 指标标准化处理
只有一个指标的时候不需要消除量纲的影响,但是2个指标及以上呢?
由于成绩和争吵次数的量纲不同(单位不同),所以需要消除指标对不同量纲的影响。
为了消去不同指标量纲的影响,需要对已经正向化的矩阵进行标准化处理。

可以发现标准化后不会影响到指标的相对大小。
matlab代码:B = repmat(A,m,n):将矩阵A复制m×n块,即把A作为B的元素,B由m×n个A平铺而成。
X = [89 1; 60 3; 74 2; 99 0]
[n,m] = size(X)
X./repmat(sum(X.*X).^0.5,n,1)代码分解:
X.*X得到![]()

sum(X.*X)得到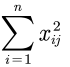

sum(X.*X).^0.5 得到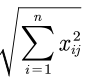

由于矩阵(点除)除法的运算需要行列一致。
repmat(sum(X.*X).^0.5,n,1)
X./repmat(sum(X.*X).^0.5,n,1) 得到

所以:


2.2.3 计算得分

计算多个指标的得分时,可以类别只有一个指标时的得分。

先求出每一列的最大值最小值,再求每个元素与最大值(最小值)的距离(欧式距离)。最后求得分即可。(和只有一个指标时的解法一样)
2.2.4 实例计算



3. TOPSIS简介
C.L.Hwang 和 K.Yoon 于1981年首次提出 TOPSIS (Technique for Order Preference by Similarity to an Ideal Solution),可翻译为逼近理想解排序法,国内常简称为优劣解距离法。
TOPSIS 法是一种常用的综合评价方法,能充分利用原始数据的信息,其结果能精确地反映各评价方案之间的差距。
基本过程为:(1)将原始数据矩阵统一指标类型(一般正向化处理)得到正向化的矩阵;
(2)再对正向化的矩阵进行标准化处理以消除各指标量纲的影响;
(3)并找到有限方案中的最优方案和最劣方案;
(4)然后分别计算各评价对象与最优方案和最劣方案间的距离;
(5)获得各评价对象与最优方案的相对接近程度,以此作为评价优劣的依据。
该方法对数据分布及样本含量没有严格限制,数据计算简单易行。
4. TOPSIS法步骤(后面更新....)
