会议:ICASSP 2018
论文:DEEP RESIDUAL LEARNING FOR SMALL-FOOTPRINT KEYWORD SPOTTING、链接2、GitHub
作者:Raphael Tang ; Jimmy Lin
ABSTRACT
我们以最近发布的Google Speech Commands数据集为基准,探索了深度残差学习和散布卷积在关键字发现任务中的应用。 就准确性而言,我们最好的残差网络(ResNet)实施明显优于Google以前的卷积神经网络。 通过改变模型的深度和宽度,我们可以获得的紧凑型模型的性能也优于以前的小尺寸变体。 据我们所知,我们是第一个研究这些关键词发现方法的人,我们的结果建立了一个开源的最新技术参考,以支持未来基于语音的界面的开发。
1. INTRODUCTION
关键字发现的目的是通常在移动电话或消费者“智能家居”设备上的智能代理的情况下,在用户话语流中检测相对较小的一组预定义关键字。这种功能补充了通常在云中执行的全自动语音识别。由于基于云的语音输入解释需要从用户的设备传输录音,因此存在很大的隐私隐患。因此,设备上的关键字发现有两个主要用途:首先,可以直接在用户设备上识别常见命令(例如“ on”和“ off”)以及其他常见单词(例如“ yes”和“ no”) ,从而避免了任何潜在的隐私问题。其次,关键字搜寻可用于检测“命令触发器”,例如“嘿Siri”,它为针对设备的交互提供了明确的提示。另外期望这样的模型具有较小的占用空间(例如,以模型参数的数量测量),因此它们可以被部署在低功率和性能受限的设备上。
近年来,神经网络已被证明可以为小尺寸关键词发现问题提供有效的解决方案。研究通常侧重于在实现高检测精度和具有较小占用空间之间进行权衡。Compact models通常是从完整模型派生而来的变体,通常会通过某种形式的稀疏性牺牲较小的模型覆盖区的精度。
在这项工作中,我们关注于卷积神经网络(CNNs),这是近年来成功应用于小足迹关键词识别的一类模型。特别是,我们探索了剩余学习技术和扩张卷积的使用。在最近发布的Google Speech Commands数据集上,我们的全残差网络模型优于Google以前最好的CNN[1](准确率为95.8%,而非91.7%)。我们可以调整我们网络的深度和宽度,以在模型的足迹和准确性之间达成一个理想的折衷:一个变种只能达到略低于谷歌最好的CNN的精度,模型参数减少50倍,前馈推理过程中的倍数减少18倍。这种模式远远超过以前的紧凑型CNN变种。
2. RELATED WORK
深度残差网络(ResNets)[2]代表了深度学习方面的突破性进展,使研究人员能够成功地训练深度网络。 它们首先应用于图像识别,在此方面它们极大地促进了最新技术的性能[2]。 ResNets随后被应用于说话人识别[3]和自动语音识别[4,5]。 本文探讨了深度残差学习技术在关键词发现任务中的应用。
当然,神经网络在关键词发现中的应用并不新鲜。 Chen等。 [6]应用标准的多层感知器来实现对以前基于HMM的方法的重大改进。 Sainath和Parada [1]在这项工作的基础上,使用卷积神经网络(CNN)获得了更好的结果。 他们特别提到减少模型占用空间(针对低功率应用)是转向CNN的主要动机。
尽管在将递归神经网络(RNN)应用于关键字发现任务[7,8]方面进行了更多的最新工作,但出于几个原因,我们还是将重点放在CNN模型家族上。 今天的CNN仍然是小足迹关键词发现的标准基准-它们具有简单的架构,相对易于调整,并在多个深度学习框架中实现(至少TensorFlow [9]和PyTorch [10])。 我们不知道要与之比较的任何公开架构的重复实现。 我们相信,残余学习技术( residual learning techniques)构成了关键字发现任务的一个尚未探索的方向,并且我们使用膨胀卷积(扩展卷积 dilated convolutions)达到了与循环体系支持者吹捧的相同目标,即能够捕获较远范围的依赖性。

3. MODEL IMPLEMENTATION
3.1. Feature Extraction and Input Preprocessing
对于特征提取,我们首先将20Hz / 4kHz的带通滤波器应用于输入音频,以降低噪声。 然后使用30ms的窗口和10ms的帧偏移构建并堆叠四维梅尔频率倒谱系数(MFCC)帧。 所有帧都以1s的间隔堆叠,以形成模型的二维输入。
3.2. Model Architecture
我们的架构类似于He等人的架构。 [2],他假设对于深度卷积神经网络而言,学习残差可能比学习原始映射要容易。 他们发现,深层网络中的其他层不能仅“附加”到较浅的网络上。 He等人特别提出,由于在模型具有不必要的深度时,由于经验上很难学习F的身份映射,因此建议使用更容易学习残差: H(x)= F(x)+ x 而不是真实映射F(x)。 在残差网络(ResNets)中,残差通过各层之间的连接表示(参见图1),其中层 i 的输入 x 被添加到某些下游层 i + k 的输出中,从而强制残差定义:H(x)= F (x)+ x。


遵循标准的ResNet架构,我们的残差块以权重: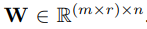 无偏差卷积层开始,其中m和r分别是宽度和高度,n是特征图的数量。卷积层之后是ReLU激活单元,而不是dropout,是批处理归一化[11]层。除了使用残差块,我们还使用
无偏差卷积层开始,其中m和r分别是宽度和高度,n是特征图的数量。卷积层之后是ReLU激活单元,而不是dropout,是批处理归一化[11]层。除了使用残差块,我们还使用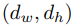 卷积扩展[12]来增加网络的接收场,这使我们可以使用较少的层数来整体考虑一秒钟的输入。 为了扩展残差块的输入,而残差块的输入和输出始终需要相同大小,我们的整个体系结构从权重为的卷积层开始。 如图1和表1所示,一个单独的非残差卷积层和批处理规范化层还附加到残差块链中。
卷积扩展[12]来增加网络的接收场,这使我们可以使用较少的层数来整体考虑一秒钟的输入。 为了扩展残差块的输入,而残差块的输入和输出始终需要相同大小,我们的整个体系结构从权重为的卷积层开始。 如图1和表1所示,一个单独的非残差卷积层和批处理规范化层还附加到残差块链中。
我们的基本模型称为res15,它包含六个这样的残差块和n = 45个特征图(请参见图1)。 为了进行扩展,如图2所示,使用了指数大小调整计划[12]:在第i层,扩展为dw =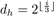 导致总接收场为125×125。 按照ResNet架构的标准,所有输出在每一层都进行零填充,最后平均池化并馈入完全连接的softmax层。 在先前的工作之后,我们用两个数量来衡量模型的“footprint”:模型中的参数数量和完整前馈推理过程所需的乘数数量。 我们的架构使用大约238K参数和894M乘法(确切的细分请参见表1)。
导致总接收场为125×125。 按照ResNet架构的标准,所有输出在每一层都进行零填充,最后平均池化并馈入完全连接的softmax层。 在先前的工作之后,我们用两个数量来衡量模型的“footprint”:模型中的参数数量和完整前馈推理过程所需的乘数数量。 我们的架构使用大约238K参数和894M乘法(确切的细分请参见表1)。
为了获得compact small-footprint model,一种简单的方法是减小网络的深度。 我们尝试将残差块的数量减少一半,减少为三个,从而产生一个称为res8的模型。 由于res15的覆盖区是由宽度和深度决定的,因此紧凑模型在第一个卷积层之后增加了一个4×3的平均池层,从而将时间和频率维度的大小分别减少了四倍和三倍, 分别。 由于平均池化层充分减小了输入维,因此在此变体中我们没有使用膨胀卷积。
在相反的方向上,我们探索了更深层模型的影响。 我们构建了一个模型,该模型具有26层的剩余块数(12)的两倍,我们将其称为res26。 为了使训练易于处理,我们在残差链链的前面添加了一个2×2平均池层。 由于25个3×3卷积滤波器的接收场足够大,可以覆盖我们的输入大小,因此也无需使用扩散。
除了深度,我们还改变了模型宽度。 上面描述的所有模型都使用n = 45个特征图,但我们还考虑了n = 19个特征图的变体,在基本模型名称后附加了-narrow。 表2给出了我们最好的紧凑型模型res8-narrow的占位面积的详细分类。 表3显示了针对我们最深和最宽模型res26的相同分析。

4. EVALUATION
4.1. Experimental Setup
我们使用Google的语音命令数据集[9]评估了模型,该数据集于2017年8月根据知识共享许可发布。数据集包含成千上万的不同人的65,000个一秒钟的长话语,包括30个短词,以及诸如粉红噪声,白噪声和人造声音之类的背景噪声样本。宣布该数据发布的博客文章还引用了Google的Sainath和Parada模型的TensorFlow实现,这为我们进行比较提供了基础。
在Google实验中,我们的任务是区分12个类别:“yes,” “no,” “up,” “down,” “left,” “right,” “on,” “off,” “stop,” “go”,unknown, or silence,我们的实验遵循与TensorFlow参考完全相同的过程。语音命令数据集分为训练集,验证集和测试集,其中80%的训练,10%的验证和10%的测试。这样就产生了大约22,000个培训示例,每个2700个示例用于验证和测试。为了确保运行的一致性,数据集中音频文件的SHA1-hashed名称决定了分割。
为了生成训练数据,我们遵循Google的预处理程序,将每个背景的背景噪声添加到每个样本的概率为0.8,其中从数据集中提供的背景噪声中随机选择背景噪声。在将音频转换为MFCC之前,我们的实现还执行Y毫秒的随机时移,其中Y〜UNIFORM [-100,100]。为了加快训练过程,所有经过预处理的输入都被缓存起来,以便在不同的训练时期重复使用。在每个时期,将驱逐30%的缓存。
准确性是我们的主要质量指标,可以简单地将其作为正确的分类决策的一部分来衡量。 对于每种情况,模型都会输出其最可能的预测,并且不会提供“不知道”选项。 我们还绘制了接收器工作特性(ROC)曲线,其中x和y轴分别显示了错误警报率(FAR)和错误拒绝率(FRR)。对于给定的灵敏度阈值(定义为在评估过程中类别被视为阳性的最小概率),FAR和FRR分别代表获得假阳性和假阴性的概率。 通过扫描敏感度间隔[0.0,1.0],计算每个关键字的曲线,然后垂直平均以生成特定模型的整体曲线。 曲线下面积(AUC)较小的曲线更好。
4.2. Model Training
和ResNet论文[2]一样,我们使用了动量(momentum )为0.9且起始学习率为0.1的随机梯度下降,在谷峰(plateaus)上乘以0.1。 我们还对Nesterov momentum进行了实验,但发现在交叉熵损失和测试准确性方面,学习性能略有下降。 我们使用的mini-batch为64,L2 weight decay 为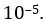 我们的模型总共训练了26个epochs,共进行了9,000个训练步骤。
我们的模型总共训练了26个epochs,共进行了9,000个训练步骤。
4.3. Results
由于我们自己的网络是在PyTorch中实现的,因此我们将Sainath和Parada模型的PyTorch重新实现作为比较点。先前我们已经确认,我们的PyTorch实现可达到与原始TensorFlow参考[10]相同的精度。我们将ResNet模型与Sainath和Parada提出的三个CNN变体进行了比较:trad-fpool3,这是它们的基本模型; tpool2,这是他们探索的最准确的变体;“one-stride1”,这是他们最好的紧凑型变体。这些模型的准确性显示在表4中,该表还显示了来自具有不同随机种子的五项不同优化试验的95%置信区间。该表提供了模型参数的数量以及推理遍中的乘法数量。我们看到tpool2确实是性能最好的模型,比trad-fpool3稍好。one-stride1模型大大减少了模型占用空间,但这在准确性方面付出了高昂的代价。

我们的ResNet变体的性能也显示在表4中。我们的基本res15模型比以前的任何Google CNN都具有明显更高的准确性(置信区间不重叠)。 此模型需要较少的参数,但是需要更多的乘数。 带有较少特征图的res15的“狭窄”变体牺牲了准确性,但仍然明显优于Google CNN(尽管它仍然使用约30% multiplies)。
通过我们紧凑的res8架构,我们可以看到“宽”版本严格控制了所有Google模型,从而以较小的占用空间显着提高了准确性。 尽管与tpool2相比性能有所下降,但“窄”变体可进一步减少占用空间,但所需模型参数减少50倍,乘法运算减少18倍。 两种型号都远远优于Google的紧凑型产品“ one-stride1”。
将注意力转移到更深的变体上,我们发现res26的精度低于res15,这表明我们已经超出了网络深度,因此可以适当地优化模型参数。 从总体上比较窄变体与宽变体,似乎宽度(要素图的数量)对精度的影响大于深度。
我们在图3中绘制选定模型的ROC曲线,将两个竞争基准与res8,res8-narrow和res15进行比较。 其余的模型不那么有趣,因此为清楚起见而省略。 这些曲线与表4中显示的精度结果一致,并且我们发现res15在所有工作点的性能上均主导其他模型。

5. CONCLUSIONS AND FUTURE WORK
本文描述了深度残差学习和扩张卷积在关键词发现问题中的应用。 最近发布的Google语音命令数据集为我们的工作提供了支持,该数据集为此任务提供了通用基准。 以前,相关工作几乎无法比拟,因为论文依赖于私人数据集。 我们的工作在此数据集上建立了新的,最新的,开源的参考模型,我们鼓励其他人在此模型上进行构建。
为了将来的工作,我们计划将基于CNN的方法与基于递归架构的新兴模型系列进行比较。 我们尚未进行此类研究,因为似乎没有此类模型的公开参考实现,并且缺少通用基准也使比较变得困难。 后一个问题已经解决,有趣的是看看递归神经网络如何与我们的方法相提并论。
6. REFERENCES
[1] Tara N. Sainath and Carolina Parada, “Convolutional neural networks for small-footprint keyword spotting,” in Interspeech, 2015, pp. 1478–1482.
[2] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep residual learning for image recognition,” in CVPR, 2016, pp. 770–778.
[3] Chunlei Zhang and Kazuhito Koishida, “End-to-end text-independent speaker verification with triplet loss on short utterances,” in Interspeech, 2017, pp. 1487–1491.
[4] Wayne Xiong, Jasha Droppo, Xuedong Huang, Frank Seide, Mike Seltzer, Andreas Stolcke, Dong Yu, and Geoffrey Zweig, “The Microsoft 2016 conversational speech recognition system,” in ICASSP, 2017, pp. 5255–5259.
[5] Wayne Xiong, Lingfeng Wu, Fil Alleva, Jasha Droppo, Xuedong Huang, and Andreas Stolcke, “The Microsoft 2017 conversational speech recognition system,” arXiv:1708.06073v2, 2017.
[6] Guoguo Chen, Carolina Parada, and Georg Heigold, “Small-footprint keyword spotting using deep neural networks,” in ICASSP, 2014, pp. 4087–4091.
[7] Sercan Omer Arik, Markus Kliegl, Rewon Child, Joel¨ Hestness, Andrew Gibiansky, Christopher Fougner, Ryan Prenger, and Adam Coates, “Convolutional recurrent neural networks for small-footprint keyword spotting,” arXiv:1703.05390v3, 2017.
[8] Ming Sun, Anirudh Raju, George Tucker, Sankaran Panchapagesan, Gengshen Fu, Arindam Mandal, Spyros Matsoukas, Nikko Strom, and Shiv Vitaladevuni, “Max-pooling loss training of Long Short-Term Memory networks for small-footprint keyword spotting,” arXiv:1705.02411v1, 2017.
[9] Pete Warden, “Launching the speech commands dataset,” Google Research Blog, 2017.
[10] Raphael Tang and Jimmy Lin, “Honk: A PyTorch reimplementation of convolutional neural networks for keyword spotting,” arXiv:1710.06554v2, 2017.
[11] Sergey Ioffe and Christian Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” arXiv:1502.03167v3, 2015.
[12] Fisher Yu and Vladlen Koltun, “Multi-scale context aggregation by dilated convolutions,” arXiv:1511.07122v3, 2015.
