会议:ICASSP 2019
论文:ADVERSARIAL EXAMPLES FOR IMPROVING END-TO-END ATTENTION-BASED SMALL-FOOTPRINT KEYWORD SPOTTING
作者:Xiong Wang ; Sining Sun ; Changhao Shan ; Jingyong Hou ; Lei Xie ; Shen Li ; Xin Lei
ABSTRACT
在本文中,我们探索了利用对抗性的例子来改进一个基于神经网络的关键词识别(KWS)系统。特别地,在我们的系统中,使用了一个有效的、基于小足迹注意的神经网络模型。对抗性例子被一个模型定义为一个错误分类的例子,但它与最初正确分类的例子只有轻微的偏差。在KWS任务中,将虚警或虚拒绝查询看作是一种对抗性的例子是一种自然的想法。在我们的工作中,给出了一个训练良好的基于注意力的KWS模型,我们首先使用快速梯度符号法(FGSM)生成对抗性例子,发现这些例子会显著降低KWS的性能。利用这些对抗性的例子作为增强数据来重新训练KWS模型,我们最终在从一个智能扬声器收集的数据集上以每小时1.0个错误报警率(FAR)实现了45.6%的相对和错误拒绝率(FRR)降低。
CONCLUSIONS
在本文中,我们探索了使用对抗性示例来提高基于注意力的端到端KWS模型的性能。我们首先验证了使用基于FGSM的对抗示例生成方法可以轻松创建虚假警报和虚假拒绝查询。然后,我们使用这些生成的对抗示例来扩充训练数据,以重新训练基于注意力的NN KWS模型。总而言之,我们发现,在我们的语料库上进行测试,使用对抗性查询来扩充训练数据是提高模型稳健性的有效方法。将来,我们将在更大的数据集上测试对抗性数据增强方法,以检查性能。此外,由于语音是顺序数据,因此我们计划考虑顺序信息,并开发新的方法来生成专门针对语音数据的对抗性示例。
INTRODUCTION
智能设备通常会聆听用户和周围环境生成的大量音频数据。为了激活设备与用户之间的语音交互,备用关键字发现(KWS)或唤醒单词检测模块对于检测音频流中的预定义关键字以触发语音交互特别重要。一个好的KWS系统需要保持高鲁棒性,低错误拒绝和错误警报,同时还要高效,低功耗和占用空间小。
已经提出了各种KWS方法,包括基于大词汇量连续语音识别(LVCSR)的格搜索方法[1],[2],[3],基于隐马尔可夫模型(HMM)的关键字/填充方法[4],[5],[6]和基于示例查询(QbyE)的模板匹配方法[7],[8]。近年来,随着深度学习的发展及其在语音识别中的成功应用,将深度神经网络(DNN)引入了KWS [9],[10],[11],[12]。这种方法非常适合在占用空间小且延迟低的设备上运行,因为DNN的大小可以轻松控制,并且不涉及复杂的图形搜索。最近,基于注意力的端到端方法也已被引入KWS任务[13],并且观察到了进一步的性能改进。仍然遵循DNN框架,这种方法大大简化了模式结构和解码过程。
KWS系统的性能通常由FRR和FAR两个标准评估。尽管许多DNN模型以较低的FRR和FAR达到了相当高的性能,但是当查询与关键字完全无关时,仍然可以错误地触发现实世界的应用程序系统,或者当关键字显然与查询无关时,可以被拒绝。更糟糕的是,由于复杂的声学环境和许多其他不可预测的原因,触发错误警报(FA)或错误拒绝(FR)的查询是不可重现的。因此,这种不可复制的属性使得难以进一步改善KWS性能。有趣的是,这种错误警报或错误拒绝的查询可以视为机器学习领域中的对抗性示例 [14]。
对抗示例的概念最早是在[15]中提出的,用于计算机视觉任务,并被许多追随者进一步发展,从对抗示例生成[16]到对抗示例防御[17]。简而言之,对抗性示例是模型的错误分类示例,但仅与原始正确分类的示例略有不同。这些示例可以通过在原始示例中添加不明显的扰动来生成。最近,还提出了音频对抗示例[18],作者试图生成音频示例,这些音频示例很容易误导训练有素的语音识别系统。更具体地说,在给定任何音频波形的情况下,它们都可以产生相似度超过99.9%的另一个音频波形,但可以转录为他们选择的任何短语。这些研究表明,神经网络模型的输出相对于输入而言并不平滑,并且在输入空间中存在“盲点”。
在本文中,我们探索使用对抗性示例来改进基于注意力的DNN KWS系统。这项研究的动机是我们最近在鲁棒语音识别上的工作[19],在该模型中,我们使用对抗性示例作为数据增强方法,而不是攻击语音识别系统,从而在声学模型(AM)训练期间增强鲁棒语音识别。如前所述,由于FA和FR查询的存在,将对抗性示例引入KWS是很自然的。我们的研究表明,存在这样的对抗示例,它们显然可以在训练有素的NN KWS系统中触发FR和FA。因此,遵循我们在[20]中的想法,我们将使用对抗性示例进一步探索增强KWS模型的方法。最后,在从智能扬声器收集的数据集上,我们以每小时1.0 FAR的速度将相对FRR降低了45.6%。
本文的其余部分安排如下。第2节简要介绍了基于注意力的端到端KWS方法。第3节详细介绍了对抗示例的生成。第4节显示了我们的实验和结果,第5节总结了本文。
ATTENTION MODEL
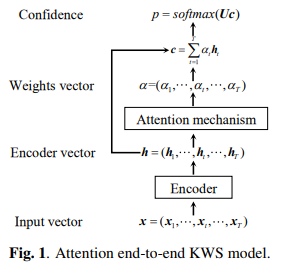
在本文中,我们采用了最近提出的基于注意力的端到端KWS模型[13],如图1所示。这个简单的架构包含两个模块,一个编码器和一个注意模型。编码器通常是递归神经网络(RNN),用于从输入特征中提取表示。注意层将表示形式转换为固定长度的向量。
略~
ADVERSARIAL EXAMPLES
对抗示例可以通过在原始示例中添加一些精心设计的小扰动来生成。我们称这种扰动为对抗性扰动。如何产生对抗性扰动在计算机视觉和语音处理领域引起了很多兴趣。在本文中,我们使用一种流行的方法,即由[16]在我们的KWS系统中提出的快速梯度符号方法(FGSM)。我们想验证当输入是时间序列时此方法是否仍然有效。
略~
EXPERIMENTS
4.1. Corpus preparation
我们使用了从Mobvoi智能扬声器TicKasa Fox 2收集的唤醒数据验证我们的KWS方法。唤醒词由三个普通话音节(“海小文”)组成。我们的数据集涵盖523个不同的说话者,包括303名儿童和220名成人。此外,每个说话人的集合都包括正说话声(带有唤醒词)和负说话声,它们以不同的说话人到麦克风的距离和不同的信噪比(SNR)记录,其中噪音来自典型的家庭环境。总共有20K个阳性样本(〜10小时)和54K个阴性样本(〜57小时)用作训练数据。验证集包括2.3K个阳性示例(〜1.1h)和5.5K个阴性示例(〜6.2h),而测试集包括2K个阳性示例(〜1h)和5.9K个阴性示例(〜6h)。每组中的扬声器没有重叠。
4.2. Experimental setups
在这项工作中,我们遵循[13]中使用的相同模型架构。对于编码器,采用了带有GRU的1层RNN。与正例相比,负例通常会持续很长时间,因此我们在训练过程中将负例的最大长度分割为200帧(2秒)。在测试阶段,将滑动200帧的窗口应用于测试示例,并且窗口移位大小为1帧。如果至少一个部分的分数大于预设阈值,则触发KWS系统。我们使用TensorFlow和ADAM [23]作为优化程序进行了实验。
4.3. Adversarial queries generation
给定一个训练有素的基于注意力的KWS模型,我们想确认是否可以使用FGSM生成对抗性示例。具体来说,我们希望使用FGSM生成基于否定示例的虚假警报查询和基于肯定查询的虚假拒绝查询。如果可以轻松生成这些示例,则可以验证该模型容易受到对抗性示例的攻击。换句话说,该模型并不平滑,因为输入空间中的很小扰动会导致输出空间中的巨大变化。
我们使用FGSM在测试集数据上生成了对抗示例,如图2所示。对于正面示例扰动(即Pos-FGSM),仅将扰动添加到关键字段,如图2(a)所示。对于否定示例扰动(即Neg-FGSM),将扰动直接添加到整个语音中,如图2(b)所示。当我们使用生成的对抗示例测试注意力KWS模型时,我们发现FAR和FRR急剧增加,如图4所示。我们在添加对抗性扰动前后分析了“不良情况”查询的关注层权重。图3给出了这样一个示例,其中附图描述了正面示例(a)和负面示例(b)随时间变化的关注层权重。我们发现,即使频谱上看不见的微小扰动也会导致注意力层发生非常明显的变化。似乎错误会随着时间的推移而累积,因为关注层的权重在查询的最后部分变化得更快。
4.4. Training augmentation using adversarial examples
4.3节的观察表明,当前模型对对抗性扰动非常敏感,确实存在不平稳的问题。为了提高模型的鲁棒性,我们使用对抗性示例进一步增强了训练数据。具体来说,我们使用[19]提出的训练策略对模型进行了训练。在训练阶段,对于每个小批量数据,动态生成对抗示例(正例和/或负例)。然后使用这些示例再次训练模型。在这项工作中,我们还尝试了不同的扩充策略,包括仅扩充肯定查询,仅扩充否定查询或扩充所有查询。仅通过使用正常训练数据的训练有素的模型初始化模型。
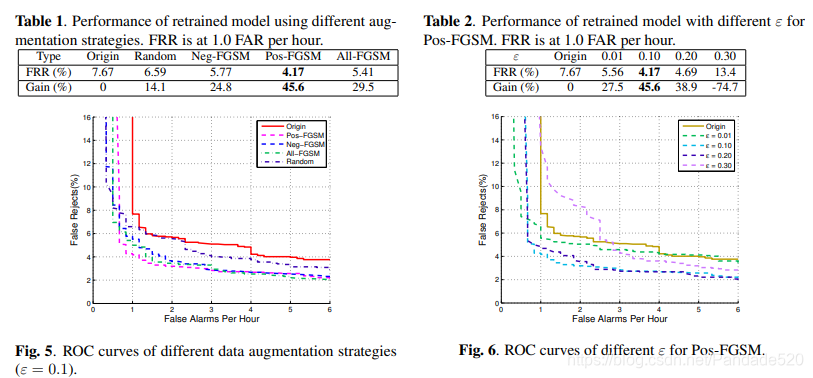
图5显示了ε = 0.1时所有方法的ROC曲线。在这里,Pos-FGSM和Neg-FGSM意味着分别在训练过程中使用正面和负面对抗性示例进行数据增强,而All-FGSM和All-Random意味着分别向所有训练数据添加对抗性和随机符号扰动。表1显示了测试集上FAR为1.0时的FRR。我们可以看到基于Pos-FGSM和Neg-FGSM的数据增强可以显着降低FRR,相对减少分别为45.6%和24.8%。相比之下,基于随机扰动的增强稍微改善了性能。总之,使用对抗性查询来扩充训练数据是提高模型鲁棒性的有效方法。
如在所示图6和表2中,我们也尝试了不同的权重对抗性ε为正对抗性查询增强(POS-FGSM)。当ε = 0.10时,我们可以获得最佳结果。较大的值(例如ε = 0.30)可能会降低性能,因为它会引入较大的扰动。