会议: ICASSP 2019
论文:Federated Learning for Keyword Spotting
作者:David Leroy、Alice Coucke、Thibaut Lavril、Thibault Gisselbrecht、Joseph Dureau
ABSTRACT
提出了一种基于联合学习的实用方法,以通过连续运行基于嵌入式语音的模型(例如唤醒词检测器)来解决域外问题。我们基于模仿“唤醒词用户”联盟的众包数据集,对“ Hey Snips”唤醒词的联合平均算法进行了广泛的经验研究。我们凭经验证明,使用由Adam启发的自适应平均策略代替标准加权模型平均可以极大地减少达到目标性能所需的通信轮次。每个用户的相关上游通信成本估计为8 MB,这对于智能家居语音助手而言是合理的。
INTRODUCTION
唤醒词检测用于启动与语音助手的交互。在关键字发现(KWS)的特定情况下,它会连续收听音频流以检测预定义的关键字或一组关键字。唤醒词的著名示例包括Apple的“ Hey Siri”或Google的“ OK Google”。一旦检测到唤醒词,语音输入就会被口语理解引擎激活和处理,从而增强语音助手的感知能力[1]。
唤醒字检测器通常以始终在线的方式在设备上运行,这带来了两个主要困难。首先,它应以最小的内存占用量和计算成本运行。我们的唤醒词检测器的资源约束是200k参数(基于[2]中提出的中型模型)和20 MFLOPS。
其次,唤醒字检测器在任何使用设置下均应表现一致,并且对背景噪声表现出鲁棒性。音频信号对录制接近度(近场或远场),录制硬件以及房间配置非常敏感。健壮性还意味着强大的说话人可变性覆盖范围。尽管使用数字信号处理前端可以帮助减轻与不良录音条件有关的问题,但扬声器的可变性仍然是一个主要挑战。由于可以随时触发模型,因此高精度尤为重要:因此,可以捕获大多数命令(高召回率),而又不会无意间触发(低误报警率)。
如今,唤醒词检测器通常在以实际使用情况设置的数据集中进行训练,例如在语音助手的情况下,用户在家中。语音数据本质上非常敏感,集中收集,这引起了主要的隐私问题。在这项工作中,我们研究了嵌入式唤醒词检测器中联合学习(FL)[3]的使用。FL是一种分散式优化程序,可在许多用户的本地数据上训练中央模型,而无需将该数据上传到中央服务器。训练工作量被移向对本地数据执行训练步骤的用户设备。然后,由参数服务器对用户的本地更新进行平均,以创建全局模型。
RELATED WORK
历史上,关于分散式学习的大多数研究都是在高度受控的群集/数据中心设置的背景下完成的,例如,以iid方式均匀划分的数据集。在[4]中的语音识别的背景下,专门研究了多核和多GPU分布式训练设置。在分散式培训中,采用高度分散,不平衡和非iid数据的工作相对较新,因为在[3]中引入了联邦平均法(FedAvg)算法及其在一组计算机视觉(MNIST,CIFAR-10)和语言建模任务中的应用(适用于莎士比亚和Google Plus帖子数据集)。就我们所知,目前的工作是针对特定用户语音数据的此类实验。
在[5]中研究了凸目标函数情况下的联合优化问题。作者提出了一种随机方差降低梯度下降优化程序(SVRG),该方法具有局部和全局按坐标的梯度缩放比例,以提高收敛性。他们的全局每坐标梯度平均策略依赖于用户本地数据集中给定坐标的稀疏性度量,并且仅适用于稀疏特征线模型。对于基于语音的应用,后一种假设在神经网络中不成立。
已经提出了一些针对初始FedAvg算法的改进,重点是客户选择[6],预算受限的优化[7]和客户的上传成本降低[8]。最近在[9]中引入了一种基于局部模型发散准则的对概念漂移鲁棒的动态模型平均策略。尽管这些贡献提出了减少联邦优化所固有的通信成本的有效策略,但据我们所知,目前的工作是第一个引入动态每坐标梯度更新来代替全局平均步骤的工作。
下一节将描述联合优化过程,以及如何用Adam启发的自适应平均规则来代替其全局平均。接下来是实验部分,其中介绍了用于训练唤醒词检测器的开源众包数据和模型。接下来是结果,并提供了通信成本分析。最后,描述了在真正分散的用户数据上训练唤醒词检测器的下一步。
FEDERATED OPTIMIZATION(联合优化)
这一节没太看懂

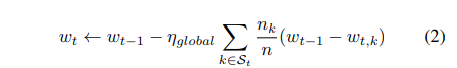
EXPERIMENTS
1、Dataset
与一般语音识别任务不同,没有用于唤醒词检测的参考数据集。用于多类别关键词识别的参考数据集是语音命令数据集[11],但是语音命令任务通常在唤醒单词检测器之前,并且专注于最大程度地减少类间的混淆,而不是对错误警报的鲁棒性。我们为Hey Snips唤醒词构成了一个众包数据集。我们公开发布1此数据集[12],希望它对关键字发现社区有用。

此处使用的数据是从1.8k贡献者那里收集的,他们使用自己的麦克风将自己记录在设备上,同时说出“ 嘿狙击”唤醒单词的出现以及来自各种文本源(例如,字幕)的否定短句。
这种由众包引起的数据分发模仿了真实世界中的非iid,不平衡和高度分布式的设置,因此,在众包提供者和语音助手用户之间的后续工作中得出了相似之处。表1汇总了有关支持该类比的数据集的统计信息。培训,开发人员和测试部门专门针对不同的用户而构建,其中77%的用户仅用于培训,其余用户用于参数调整和最终评估,从而衡量了模型对新用户的推广能力。
2、模型
声学特征是基于在每个25ms的窗口中计算出的40维梅尔频率倒谱系数(MFCC)生成的。输入窗口由32个堆叠的框架组成,在左右上下文中对称分布。该架构是一个CNN,具有5个堆叠的扩张卷积层,其扩张速率不断提高,其后是两个完全连接的层以及一个受[13]启发的softmax 。使用Xavier初始化[14]初始化的参数总数为190,852。。在帧预测中使用交叉熵损失来训练模型。神经网络有4个输出标签,通过专门针对目标话语“ Hey Snips”的自定义对齐器分配:“ Hey”,“ sni”,“ ps”和“ filler”考虑了所有其他情况(沉默,噪音和也就是说)。后处理[15]通过组合平滑的标签后代,为每一帧生成置信度得分。如果置信度得分达到某个阈值τ,则模型触发,定义了在一定数量的每小时误报警(FAH)下最大化召回率的操作点。我们将每小时错误警报的数量设置为5作为开发集的停止标准。开发集在涉及虚假警报时是一个“硬”数据集,因为它与用于训练的数据属于同一域。最后,根据测试集的肯定数据评估模型的召回率,同时对测试集的否定数据和各种背景否定的音频集计算误报。
3、结果
我们根据表1的众包数据对Hey Snips唤醒词的联邦平均算法进行了广泛的经验研究。将联合优化结果与标准设置进行比较例如,集中式小批量SGD,来自火车用户的数据被随机洗牌。我们的目标是评估为了达到开发人员集合上的停止条件而需要的通信回合数。出于本实验的目的,以集中方式评估了提前停止,并且我们假设开发人员集用户同意与参数服务器共享其数据。在实际产品设置中,提前停止估算将在开发用户的设备上本地运行,他们将在每一轮结束时下载中心模型的最新版本,并根据自己的预测分数评估提前停止标准话语。然后,这些单独的度量将由参数服务器平均,以获得全局模型准则估计。
标准基准线: 我们的基准线(例如,具有单个培训服务器和Adam优化器的标准集中式数据设置)以400步(约2个纪元)达到了提前停止的目标,被视为我们的性能上限。与标准SGD相比,Adam提供了强大的收敛速度,尽管开发集上的学习率和梯度削波调整,但标准SGD在28个纪元后仍低于87%。
用户并行度: 在每个C轮中选择的用户比例越高,假设本地培训的差异不会太大,则用于分布式本地培训的数据就越多,并且预期的收敛速度就越快。图1显示了C对融合的影响:与使用10%的用户相比,使用一半的用户获得的收益有限,特别是在融合的后期。由于选择的用户必须在线,因此在实际设置中,每轮用户只有10%的比例更为现实。参与率较低(C = 1%)时,梯度更加敏感,可能需要使用学习率平滑策略。因此,将C设定为10%。
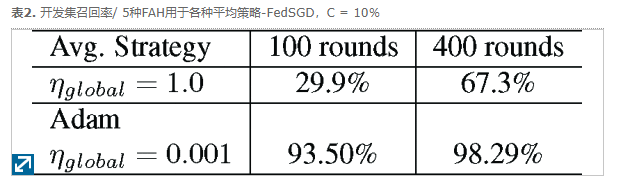
全局平均: 与带有或不带有移动平均值的标准平均策略相比,基于Adam的全局自适应学习率可加快收敛速度。表2总结了在FedSGD设置下具有最佳本地学习率的实验结果。与自适应每参数平均相比,即使在经过400轮通信之后,应用标准全局平均也会产生较差的性能。

本地训练:我们的结果表明,本地培训配置之间具有一致性,而增加本地培训的负荷却带来有限的改进。通信回合的数目需要达到63个112通信轮之间dev的集合范围内的停止准则为ë ∈ [1] ,[3]和乙 ∈[20,50,∞ ]时,使用c ^ = 10%,亚当全球平均有η 全球 = 0.001,和0.01的地方学习率。在我们的实验中,对于E = 1和B可获得最佳性能= 20,表示每个工人平均进行2.4次本地更新,与FedSGD相比,加速了80%。对于100个通信回合,达到停止标准所需的培训步骤总数约为3300,例如,标准设置中所需步骤数的8.25倍,而批次要少得多。尽管如此,我们观察到了随机权重初始化和早期行为方面的实验差异。与[3]中介绍的一些实验不同,由于增加了局部训练步骤而产生的加速并不会导致收敛速度得到数量级的提高,而事实证明,局部学习率和全局平均调整对我们的工作至关重要。我们推测这种差异与跨用户的输入语义可变性有关。在[3]中的MNIST和CIFAR实验中,跨仿真用户的输入语义是相同的。在唤醒词设置中,每个用户对相同的唤醒词发声都有自己的发声,在音调和重音上存在显着差异,这可能会导致发散的较低级表示形式(平均时表现可能较差)。
评估:我们对最佳模型(E = 1和B = 20)的误报率进行了评估,测试集上的固定召回率为95%。我们在阴性测试数据上观察到3.2 FAH,在Librispeech [16]上观察到3.9 FAH,在内部新闻和收集的电视数据集上分别观察到0.2和0.6 FAH。不足为奇的是,在近场连续数据集上,虚假警报比在背景负音频集上更为常见。
4、通讯成本分析
当从分散的数据中学习时,尤其是当用户设备的连接性和带宽有限时,通信成本是一个很大的约束。考虑到宽带速度的非对称性,联合学习的通信瓶颈是从客户端到参数服务器的权重更新[8]。我们假设与每个通信回合中的模型评估所涉及的用户相关的上游通信成本是微不足道的,因为他们每回合只会上传一些比模型大小小得多的浮点度量。下式提供了总的客户端上传带宽要求:
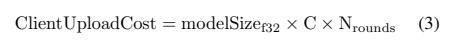
根据我们的结果,如果在100个通信回合中达到停止标准,每个客户端将产生8MB的成本。当C = 10%时,服务器每轮接收137次更新,在整个优化过程中总共有110GB的数据,培训期间涉及1.4k用户。后续收敛阶段(400轮)的进一步实验在测试集上产生了98%的召回率/0.5 FAH,每个用户的上传预算为32 MB。
CONCLUSION AND FUTURE WORK
在这项工作中,我们调查了在众包语音数据上联合学习的使用,以学习资源受限的唤醒词检测器。我们展示了基于Adam代替标准全局平均的基于坐标平均的重新审视的联邦平均算法,该训练可使我们在众包数据集的100个通信回合中达到相关联的上游的每5个FAH 95%召回的目标停止标准每个客户端的通信成本为8MB。我们还将开源Hey Snips唤醒词数据集。
现实生活中的下一步是设计一个用于本地数据收集和标记的系统,因为唤醒词任务需要数据监督。在这项工作中使用的帧标记策略依赖于对齐器,该对齐器不容易嵌入。使用内存有效的端到端模型[12]代替所提出的基于类的模型可以简化本地数据标记的工作。
