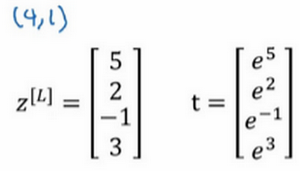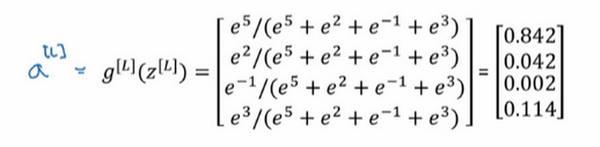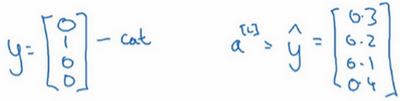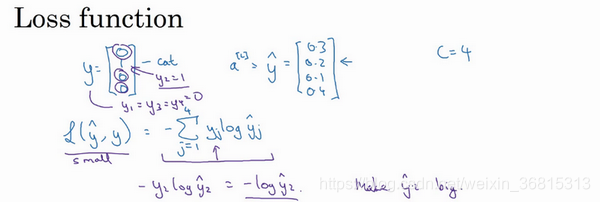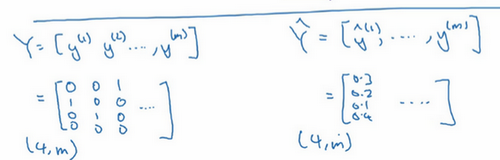上一个视频中我们学习了Softmax 层和Softmax 激活函数,在这个视频中,你将更深入地了解Softmax 分类,并学习如何训练一个使用了Softmax 层的模型。
回忆一下我们之前举的的例子,输出层计算出的
z
[
l
]
z^{[l]}
z [ l ]
z
[
l
]
=
[
5
2
−
1
3
]
z^{[l]}=\left[\begin{matrix}5\\2\\-1\\3\end{matrix}\right]
z [ l ] = ⎣ ⎢ ⎢ ⎡ 5 2 − 1 3 ⎦ ⎥ ⎥ ⎤
C
=
4
C=4
C = 4
z
[
l
]
z^{[l]}
z [ l ]
t
t
t
t
=
[
e
5
e
2
e
−
1
e
3
]
t=\left[\begin{matrix}e^5\\e^2\\e^{-1}\\e^3\end{matrix}\right]
t = ⎣ ⎢ ⎢ ⎡ e 5 e 2 e − 1 e 3 ⎦ ⎥ ⎥ ⎤
g
(
L
)
(
)
g^{(L)}()
g ( L ) ( ) Softmax 激活函数,那么输出就会是这样的:
简单来说就是用临时变量
t
t
t
a
[
L
]
a^{[L]}
a [ L ]
z
z
z
Softmax 这个名称的来源是与所谓hardmax 对比,hardmax 会把向量
z
z
z
[
1
0
0
0
]
\left[\begin{matrix}1\\0\\0\\0\end{matrix}\right]
⎣ ⎢ ⎢ ⎡ 1 0 0 0 ⎦ ⎥ ⎥ ⎤ hardmax 函数会观察
z
z
z
z
z
z hard max ,也就是最大的元素的输出为1,其它的输出都为0。与之相反,Softmax 所做的从
z
z
z softmax 这一名称背后所包含的想法,与hardmax 正好相反。
有一点我没有细讲,但之前已经提到过的,就是Softmax 回归或Softmax 激活函数将logistic 激活函数推广到
C
C
C
C
=
2
C=2
C = 2
C
=
2
C=2
C = 2 Softmax 实际上变回了logistic 回归,我不会在这个视频中给出证明,但是大致的证明思路是这样的,如果
C
=
2
C=2
C = 2 Softmax ,那么输出层
a
[
L
]
a^{[L]}
a [ L ]
C
=
2
C=2
C = 2 logistic 回归计算单个输出的方式。这算不上是一个证明,但我们可以从中得出结论,Softmax 回归将logistic 回归推广到了两种分类以上。
接下来我们来看怎样训练带有Softmax 输出层的神经网络,具体而言,我们先定义训练神经网络使会用到的损失函数。举个例子,我们来看看训练集中某个样本的目标输出,真实标签是
[
0
1
0
0
]
\left[\begin{matrix}0\\1\\0\\0\end{matrix}\right]
⎣ ⎢ ⎢ ⎡ 0 1 0 0 ⎦ ⎥ ⎥ ⎤
y
^
\hat{y}
y ^
y
^
\hat{y}
y ^
y
=
[
0.3
0.2
0.1
0.4
]
y=\left[\begin{matrix}0.3\\0.2\\0.1\\0.4\end{matrix}\right]
y = ⎣ ⎢ ⎢ ⎡ 0 . 3 0 . 2 0 . 1 0 . 4 ⎦ ⎥ ⎥ ⎤
a
[
l
]
a^{[l]}
a [ l ]
a
[
l
]
=
y
=
[
0.3
0.2
0.1
0.4
]
a^{[l]}=y=\left[\begin{matrix}0.3\\0.2\\0.1\\0.4\end{matrix}\right]
a [ l ] = y = ⎣ ⎢ ⎢ ⎡ 0 . 3 0 . 2 0 . 1 0 . 4 ⎦ ⎥ ⎥ ⎤
那么你想用什么损失函数来训练这个神经网络?在Softmax 分类中,我们一般用到的损失函数是
L
(
y
^
,
y
)
=
−
∑
j
=
1
4
y
j
log
y
^
j
L(\hat{y},y)=-\sum_{j=1}^4y_j\log\hat{y}_j
L ( y ^ , y ) = − ∑ j = 1 4 y j log y ^ j
y
1
=
y
3
=
y
4
=
0
y_1=y_3=y_4=0
y 1 = y 3 = y 4 = 0
y
2
=
1
y_2=1
y 2 = 1
y
j
y_j
y j
−
y
2
t
log
y
^
2
-y_2t\log\hat{y}_2
− y 2 t log y ^ 2
j
j
j
j
=
2
j=2
j = 2
y
2
=
1
y_2=1
y 2 = 1
−
log
y
^
2
-\log\hat{y}_2
− log y ^ 2
L
(
y
^
,
y
)
=
−
∑
j
=
1
4
y
j
log
y
^
j
=
−
y
2
log
y
^
2
=
−
log
y
^
2
L(\hat{y},y)=-\sum_{j=1}^4y_j\log\hat{y}_j=-y_2\log\hat{y}_2=-\log\hat{y}_2
L ( y ^ , y ) = − ∑ j = 1 4 y j log y ^ j = − y 2 log y ^ 2 = − log y ^ 2
这就意味着,如果你的学习算法试图将它变小,因为梯度下降法是用来减少训练集的损失的,要使它变小的唯一方式就是使
−
log
y
^
2
-\log\hat{y}_2
− log y ^ 2
y
^
2
\hat{y}_2
y ^ 2
x
x
x
y
=
[
0.3
0.2
0.1
0.4
]
y=\left[\begin{matrix}0.3\\0.2\\0.1\\0.4\end{matrix}\right]
y = ⎣ ⎢ ⎢ ⎡ 0 . 3 0 . 2 0 . 1 0 . 4 ⎦ ⎥ ⎥ ⎤
概括来讲,损失函数所做的就是它找到你的训练集中的真实类别,然后试图使该类别相应的概率尽可能地高,如果你熟悉统计学中最大似然估计,这其实就是最大似然估计的一种形式。但如果你不知道那是什么意思,也不用担心,用我们刚刚讲过的算法思维也足够了。
这是单个训练样本的损失,整个训练集的损失
J
J
J
J
(
w
[
1
]
,
b
[
1
]
,
⋯
)
=
1
m
∑
i
=
1
m
L
(
y
^
(
i
)
,
y
(
i
)
)
J(w^{[1]},b^{[1]},\cdots)=\frac1m\sum_{i=1}^mL(\hat{y}^{(i)},y^{(i)})
J ( w [ 1 ] , b [ 1 ] , ⋯ ) = m 1 ∑ i = 1 m L ( y ^ ( i ) , y ( i ) )
因此你要做的就是用梯度下降法,使这里的损失最小化。
最后还有一个实现细节,注意因为
C
=
4
C=4
C = 4
y
y
y
y
y
y
Y
Y
Y
[
y
(
1
)
y
(
2
)
⋯
⋯
y
(
m
)
]
\left[\begin{matrix}y^{(1)}y^{(2)}\cdots\cdots y^{(m)}\end{matrix}\right]
[ y ( 1 ) y ( 2 ) ⋯ ⋯ y ( m ) ]
Y
=
[
0
0
1
⋯
1
0
0
⋯
0
1
0
⋯
0
0
0
⋯
]
Y=\left[\begin{matrix}0&0&1&\cdots\\1&0&0&\cdots\\0&1&0&\cdots\\0&0&0&\cdots\end{matrix}\right]
Y = ⎣ ⎢ ⎢ ⎡ 0 1 0 0 0 0 1 0 1 0 0 0 ⋯ ⋯ ⋯ ⋯ ⎦ ⎥ ⎥ ⎤
Y
Y
Y
4
∗
m
4*m
4 ∗ m
Y
^
=
[
y
^
(
1
)
y
^
(
2
)
⋯
⋯
y
^
(
m
)
]
\hat{Y}=\left[\begin{matrix}\hat{y}^{(1)}\hat{y}^{(2)}\cdots\cdots \hat{y}^{(m)}\end{matrix}\right]
Y ^ = [ y ^ ( 1 ) y ^ ( 2 ) ⋯ ⋯ y ^ ( m ) ]
y
^
(
1
)
(
a
[
l
]
(
1
)
=
y
(
1
)
=
[
0.3
0.2
0.1
0.4
]
)
\hat{y}^{(1)}(a^{[l](1)}=y^{(1)}=\left[\begin{matrix}0.3\\0.2\\0.1\\0.4\end{matrix}\right])
y ^ ( 1 ) ( a [ l ] ( 1 ) = y ( 1 ) = ⎣ ⎢ ⎢ ⎡ 0 . 3 0 . 2 0 . 1 0 . 4 ⎦ ⎥ ⎥ ⎤ )
Y
^
=
[
0.3
⋯
0.2
⋯
0.1
⋯
0.4
⋯
]
\hat{Y}=\left[\begin{matrix}0.3&\cdots\\0.2&\cdots\\0.1&\cdots\\0.4&\cdots\end{matrix}\right]
Y ^ = ⎣ ⎢ ⎢ ⎡ 0 . 3 0 . 2 0 . 1 0 . 4 ⋯ ⋯ ⋯ ⋯ ⎦ ⎥ ⎥ ⎤
Y
^
\hat{Y}
Y ^
4
∗
m
4*m
4 ∗ m
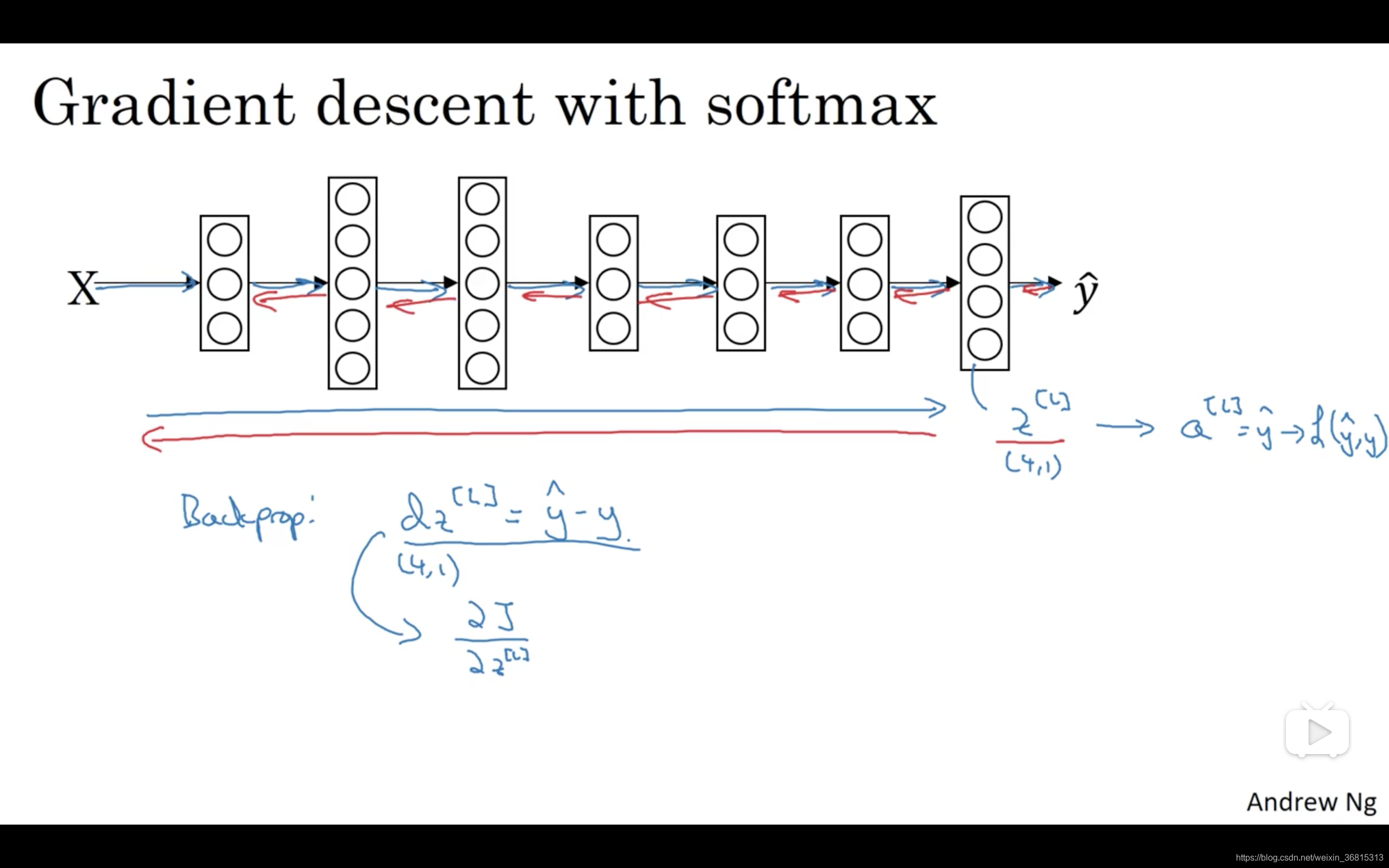
最后我们来看一下,在有Softmax 输出层时如何实现梯度下降法,这个输出层会计算
z
[
l
]
z^{[l]}
z [ l ]
C
∗
1
C*1
C ∗ 1 Softmax 激活函数来得到
a
[
l
]
a^{[l]}
a [ l ]
y
y
y
d
z
[
l
]
=
y
^
−
y
dz^{[l]}=\hat{y}-y
d z [ l ] = y ^ − y
y
^
\hat{y}
y ^
y
y
y
C
∗
1
C*1
C ∗ 1
d
z
dz
d z
z
[
l
]
z^{[l]}
z [ l ]
d
z
[
l
]
=
∂
J
∂
z
[
l
]
dz^{[l]}=\frac{\partial J}{\partial z^{[l]}}
d z [ l ] = ∂ z [ l ] ∂ J
有了这个,你就可以计算
d
z
[
l
]
dz^{[l]}
d z [ l ]
但在这周的初级练习中,我们将开始使用一种深度学习编程框架,对于这些编程框架,通常你只需要专注于把前向传播做对,只要你将它指明为编程框架,前向传播,它自己会弄明白怎样反向传播,会帮你实现反向传播,所以这个表达式值得牢记(
d
z
[
l
]
=
y
^
−
y
dz^{[l]}=\hat{y}-y
d z [ l ] = y ^ − y Softmax 回归或者Softmax 分类,但其实在这周的初级练习中你不会用到它,因为编程框架会帮你搞定导数计算。
Softmax 分类就讲到这里,有了它,你就可以运用学习算法将输入分成不止两类,而是
C
C
C